国内的数据行业领域大致有3个市场分水岭:
- 2008年以前,关系型数据库厂商领军,以
MySQL、Oracle、SQLServer为代表。 - 2008年~2012年,与关系型数据库竞争的各类NoSQL厂商异军突起,以
Hadoop生态、MongoDB、Neo4j等为代表。 - 2012年至今,云厂商巨头挥舞着
大数据、云原生、中台、数据集市、数据湖等旗帜一统江湖,以亚马逊、阿里云、华为云为代表。
2022年的今天,如何透过这些漫天飞舞的大数据概念与术语,看清它们的技术本质、在To B的产品中落地呢?
笔者试图通过**《数据仓库(Building the Data Warehouse)-第四版》**这本经典著作的思想脉络进行阐述。

1.数据江湖恩仇录
1.1.数据仓库的初创期
**《数据仓库(Building the Data Warehouse)-第四版》**包含了有3份序言(第2版序言、第3版序言、第4版序言)。
从第2版序言、第3版序言看,在1995年之前,刚兴起的数仓理论不太受待见:
数据库学者不太接受数据仓库理论:- 从学术看,数仓理论只是
空洞的新概念。 - 从实践看,似乎没有必要将数据从原有的数据库集群(事务型)中分出来,存入另一个数据库集群(分析型)中。
- 从学术看,数仓理论只是
商业投资人也不太看好数据仓库:- 似乎那个年代的资本兴趣点在互联网。
从第4版序言看,在1996年之后,数仓开始成熟并商业落地:
- 第4版序言只用了一句话的盖棺定论:
数据仓库对于那些赞同传统数据库理论的人来说是一种智力上的威胁。 - 第4版序言大篇幅在阐述:
- 架构:设计数仓的关键架构理论。
- 需求:数据设计的关键方法论。
详见《数据仓库(Building the Data Warehouse)-第四版》的序言章节。

1.2.数据仓库的成熟期
随着数据仓库理论的成熟与落地,出现了数据仓库的两大宗师:Inmon和Kimball。
Inmon就是《数据仓库(Building the Data Warehouse)-第四版》的作者。
这两位宗师好似气宗与剑宗,代表了数仓理论的2大流派。
两位宗师的理论有很多相似点:
- 对数仓的作用理解一致:产品的数据库中存储的是事务型数据,而数仓中存储的是分析型数据,这些分析型数据是为了商业智能做决策的。
- 比如:淘宝存储了每个人的下单、付款、收货等记录,这属于事务型数据。
- 比如:淘宝对进行用户画像,商品推荐等产生的数据,这属于分析型数据。
- 对数仓的架构理解一致:都认为需要进行数仓分层,也都认同每一个数仓架构中的组件都会衍生出一个垂直技术领域。
- 比如:数仓中的数据需要分为贴源数据层、明细数据层、主题数据层、应用数据层等——这些数仓/数据湖中O表、D表、A表的理论基础。
- 比如:数据采集要有针对不同类型的数据的采集基础设施——这就是现在大数据领域中的ETL的理论基础。
- 比如:数据存储、数据计算要依托于高性能/高HA的基础设施——这就是现在HBase、Hive、Kafka、Kylin等中间件的理论基础。
- 比如:数仓中的数据要能识别出血缘关系、数据质量属性——这就是Atlas等中间件的理论基础。
两位宗师的理论最大的分歧点:在于业务数据建模的方法论。
- 在2022年的今天看来,Kimball的维度建模理论应该变成了主流。
为什么维度建模最终胜出呢?笔者有两个粗浅的猜测:
- 猜测1:维度建模理论更接地气。
- 从Inmon大师的这本《数据仓库(Building the Data Warehouse)-第四版》书,真的很难看懂他的方法论如何落地。
- 而从Kimball大师的各种论文与书籍中,更容易理解维度建模的思想。
- 猜测2:维度建模的案例更多。
- Kimball大师背后是一家商业咨询公司,出版/发布的数仓书籍与论文中,包含了很多维度建模的行业案例。
- 而Inmon大师,在《数据仓库(Building the Data Warehouse)-第四版》这本书中仅仅在第13章、第15/17/18/19章中谈到了一些High Level的建模方法。
详见《数据仓库(Building the Data Warehouse)-第四版》的目录。

1.3.数据仓库的修仙期
从1995年数仓理论成熟至今,数仓慢慢开始神话。
- 微软推出商业智能的概念以及PowerBI产品,微软的PowerBI一统江湖了很多年。
- 在被微软垄断的那些年,数仓属于企业级高端玩家才会触及的高端货,因此也没啥新的突破。
- 到了2012年移动互联网的爆发,数仓借着
大数据开始神话,出现了Hadoop、Spark、MongoDB、Kafka等一大堆IT基础中间件,也出现了数据中台、数据湖等一大堆新的技术名词。
2.如何抓住大数据时代的技术主线?
2.1.为什么数仓理论是技术主线?
从30多年前的数据仓库,到今天的大数据时代,各种架构概念、业务概念,你方唱罢我登场。
从2021年开始,国家又推出了企业数字化转型的政策,各企业随之兴起了企业数字化的风潮。
作为架构师、程序猿的我们,如何才能抓住大数据时代的技术主线?
笔者认为,数仓就是这条技术主线:
从需求看,企业用户低估计数字化难度造成项目失败后,会催生对掌握数仓方法论的技术人才的需求:
- 企业用户低估数字化难度的原因:
- 认为什么原始数据都有——比如:客户的订单数据、商品浏览数据、物流数据等。
- 认为数字化等于一个数据大屏——比如:看看什么商品利润高、该给什么客户推送什么商品等。
- 缺乏理论指导,大数据沦为数据大
- 缺乏业务设计:大屏上要展示哪些报表,这些报表最终说明了什么业务问题?这些报表最终可以得出什么决策结论?
- 缺乏数据分析与设计:为了获得最终展示在大屏上的报表,需要哪些中间层数据,这些中间层数据又通过哪些原始数据可以得到?
- 数仓方法论如何解决问题?
- 聚焦业务决策:数仓理论的核心思想是要数据分析师回答依托报表,到底可以得到怎样的商业决策。
- 自顶而下:数仓理论的落地过程是先确定业务过程->数据维度->数据粒度,得出需要哪些中间数据;再确定数据事实,最终得出需要采集哪些原始数据。
- 企业用户低估数字化难度的原因:
从架构看,数仓理论可以直击本质,将纷繁的大数据中间件串联起来:
- 数仓原始数据采集相关的中间件:Flume、Kafka、Sqoop等。
- 数仓数据存储相关的中间件:MySQL、HBase、Redis、MongoDB等。
- 数仓数据计算相关的中间件:Hive,Spark,Flink,Storm等。
- 数仓的即席查询、多维分析相关的中间件:Presto,Kylin等。
- 数仓的任务调度、集群监控相关的中间件:Azkaban、Zabbix,Prometheus等。
- 数仓的数据可视化相关的中间件有:Superset、DataV、PowerBI等。
- 数仓的元数据管理相关的中间件有:Altas等。
2.2.数仓理论的3个关键步骤
基于《数据仓库(Building the Data Warehouse)-第四版》,笔者绘制了一幅数仓落地概念图:
- STEP1.开展数仓架构设计。
- STEP2.开展数仓业务数据设计。
- STEP3.开展数仓业务实现。
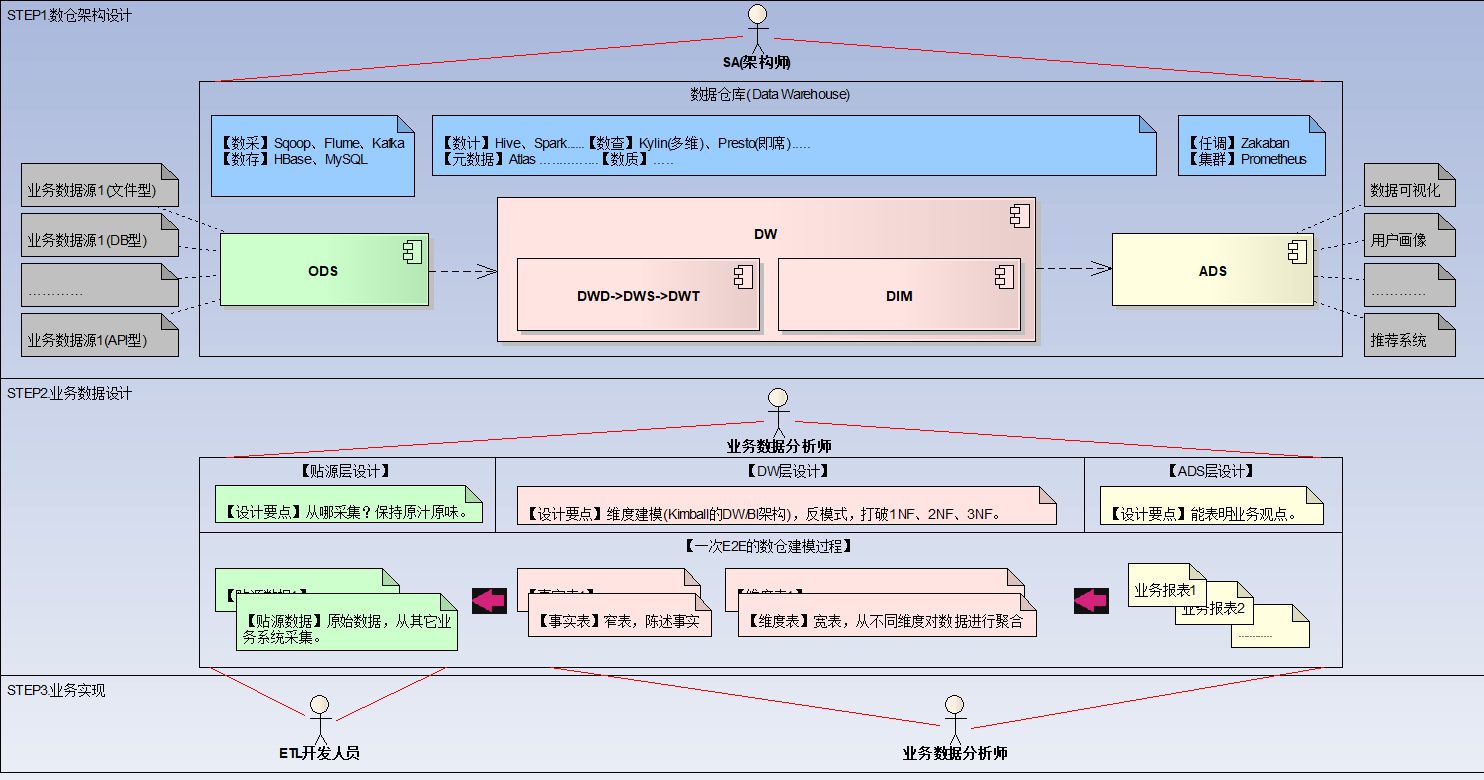
2.2.1.第一步,数仓架构设计
此步骤的主要角色:软件架构师
软件架构师的能力模型:熟练掌握各类大数据中间件,而不必太纠结具体的业务细节:
掌握ODS数据获取的工具:
- 数据采集相关:Flume、Kafka、Sqoop等。
- 数据存储相关:MySQL、HBase、Redis、MongoDB等。
掌握DW层的工具:
数据计算相关:Hive,Spark,Flink,Storm等。
数据查询相关:Presto,Kylin等。
元数据管理、数据质量相关:Altas等。
任务调度、集群监控相关:Azkaban、Zabbix,Prometheus等。
数据可视化相关:Superset、DataV、PowerBI等。
详见《数据仓库(Building the Data Warehouse)-第四版》的第2章、第5~11章、第14章。
2.2.2.第二步,开展数仓业务数据设计
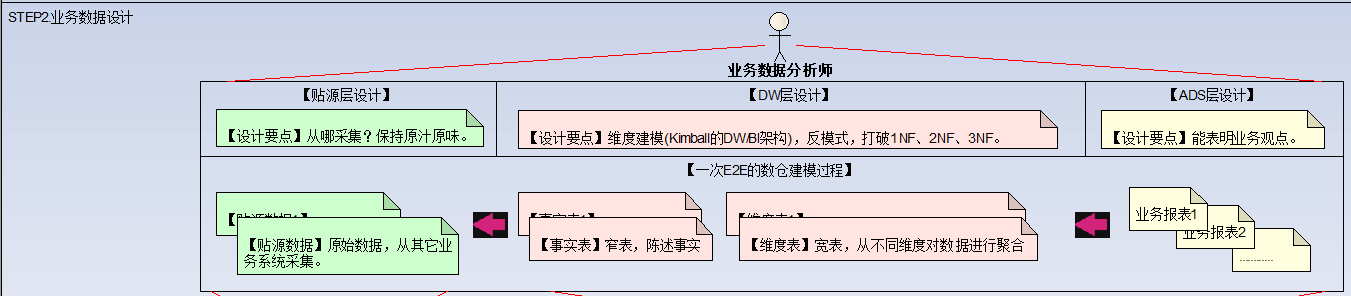
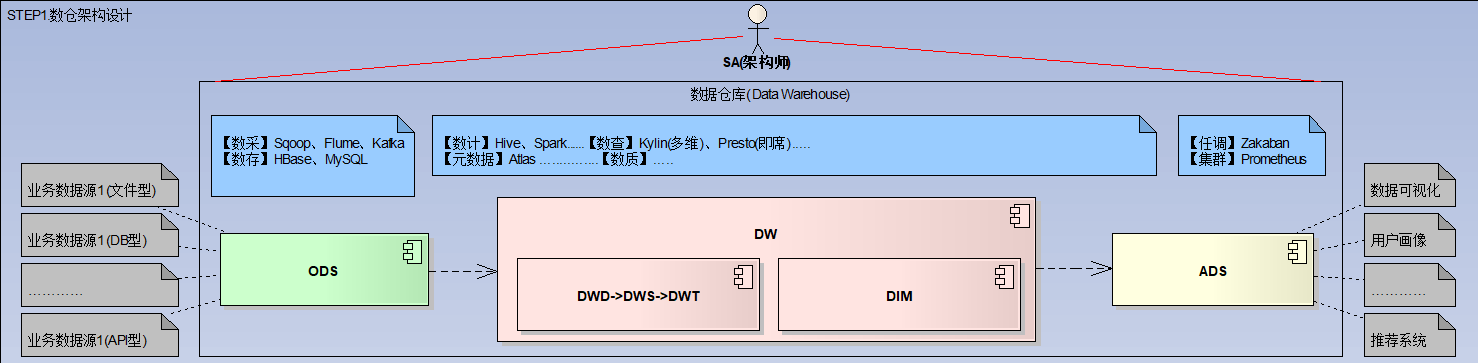
此步骤的主要角色:业务数据分析师
业务数据分析师的能力模型:熟练掌握维度建模。
- 维度建模本质是一种反模式,打破了关系型数据库的三范式(1NF、2NF、3NF),即允许数据的冗余。
- 设计维度表:维度表通常是宽表,从不同维度对数据进行聚合。
- 设计事实表:事实表通常是窄表,记录具体的事实。
- 设计贴源表:说明从哪里采集原始数据,在这一层不会对原始数据进行任何处理。
这么讲很抽象,笔者举一个通俗的例子:
- 站在ADS层:可以认为企业老板想吃一桌川菜。
- 怎么理解一桌川菜呢?可能包含水煮鱼、鱼香肉丝、宫保鸡丁、干锅花菜、四川凉糕。
- 这就是ADS层,贴近业务,是最终客户能理解的东西。
- 站在DW层的维度表:可以类比是各道菜的菜谱。
- 比如:水煮鱼可以类比川菜中鱼这个维度的典型做法。
- 比如:鱼香肉丝可以类比川菜中猪肉这个维度的典型做法。
- 比如:四川凉糕可以类比川菜中甜品这个维度的典型做法。
- 站在DW层的事实表:可以类比各道菜菜谱涉及的食材。
- 比如:水煮鱼需要用到1条草鱼、3个朝天椒……
- 比如:鱼香肉丝需要1斤猪肉、1个朝天椒……
- 比如:干锅花菜需要1棵花菜、1个朝天椒……
- 站在ODS层:可以类比为最后厨房小工的采购清单:
- 厨房小工最后看到的清单会汇总。
- 汇总的原始清单可能从不同菜市场购买(不同原始数据来源)。
- 站在ADS层:可以认为企业老板想吃一桌川菜。
详见《数据仓库(Building the Data Warehouse)-第四版》的第13章、第15章、第17~19章。
2.2.3.第三步,开展数仓业务实现
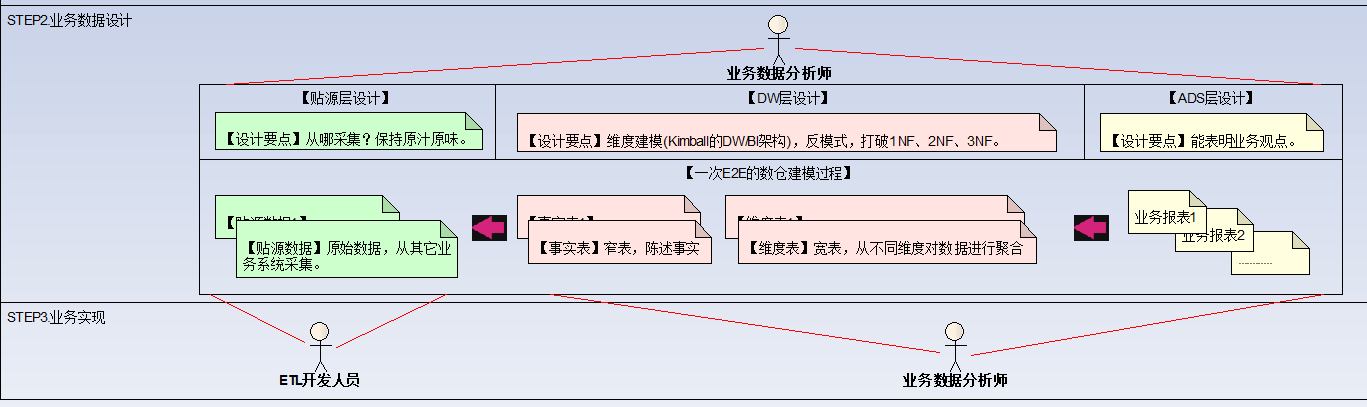
- 此步骤的主要角色:业务数据分析师、ETL开发人员
- 业务数据分析师的能力模型:通常一些商业化产品都带有可视化的建模工具,业务数据分析师可以通过
No Code,Low Code的方式进行维度建模。 - 开发人员的能力模型:会使用ETL工具,或自研代码,从不同数据源获取数据并存储到数据库中。
3.参考文献
| |