1.Brendan Gregg是谁
Brendan Gregg,性能界大神,曾就职于Netflix、Sun、Oracle、Joyent(被三星收购的一家云计算公司),从2022年5月的博客看,他目前就职于Intel。
Brendan Gregg在性能方面的成就数不胜数,仅列出两项就可以让我们膜拜了:
- 《Systems Performance : Enterprise and the Cloud》:中文名《性能之巅》,一本风靡全球的性能工程的圣经。
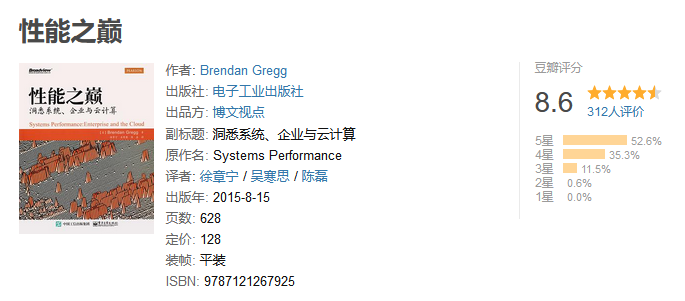
- “The Flame Graph”:Brendan Gregg于2013年提出的"火焰图”,火焰图方法也成为现在各种性能工具中必备的可视化能力。
Brendan Gregg在性能领域,还有一个被广为传播的骚操作——对着磁盘狂吼引发磁盘IO的性能问题。。。大神的世界我们永远不懂。。。

2.第一章笔记
Brendan Gregg在《性能之巅》第一章主要讲了2个问题:
- 为什么学习性能工程很难?
- 为什么实施性能工程很难?
为什么学习性能工程很难?
作者想表达的核心观点:
性能工程要求工程师具备宽广的技术广度,同时也要具备深邃的技术深度。
然而,技术深度与技术广度兼备的确是一件很困难的事情。
作者引用了2002年美国国防部长论述国际关系时的一段话:
国际关系中,
有已知的已知:有些事情我们知道自己知道。
也有已知的未知:我们知道有些事情我们不知道。
但还有未知的未知:有些事情我们知道自己不知道。
美国防部长这段话的本意是想论述国际关系复杂多变,任何一项决策要考虑充分,避免未知的未知引发不可估量的后果。
作者认为这段话也可以类比于性能工程:
当我们开展性能优化工作时,由于未知的未知太多,会导致:
(1)缺乏"高效"的定位手段——而且我们还不自知操作系统早已为我们准备好了对应的方法和工具。
(2)缺乏"有效"的解决办法。
作者的观点,与庄子的《养生主》异曲同工:
吾生也有涯,而知也无涯。以有涯随无涯,殆已!
人类的生命是非常有限的,而知识无边无尽,以有限的生命追求无边的知识,显然是不可能的。
作者有什么建议呢?可以归纳为两点:
- 对策1:对知识进行归纳,抽象出知识的本质。
- 对策2:有选择地、有优先级地学习。
- 巩固已知的已知,扩大已知的未知,减少未知的未知。
作者认为知识肯定是学不完的,但学习时可以:
- 首先,将尽可能多的"未知的未知"转换为"已知的未知”。
- 然后,实战时再查资料,将"已知的未知"转换为"已知的已知”。
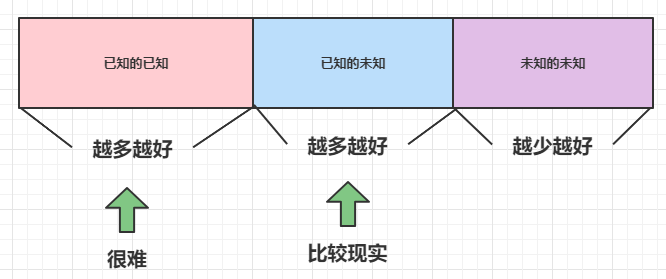
但,工程师分三种:
天才型工程师:知识结构大多是已知的已知,这是大神,也是少数。
扎实型工程师:知识结构大多是已知的已知、已知的未知,这是大多数人的可能达到的状态。
愚昧型工程师:知识结构大多是未知的知识,这种工程师往往觉得自己就是全世界。
“用到的时候再查文档“这句话,
对于扎实性工程师是有效的。
对于愚昧性工程师是无效的——即便实战时给他充足的时间查资料,首先他都不会去查(因为他不知道),即便去查也可能查不到、查到也看不懂。
作者的这个学习论,可以推广到各种知识的学习中。
为什么实施性能工程很难?
作者归纳了实战中性能工程的3个难点:
- 性能的主观性
- 系统的复杂性
- 人员的协作性
性能的主观性
作者认为性能是主观的,同样是磁盘单次IO的时间是1ms,
在实时系统场景下是很慢的,在管理信息系统场景下却是很快的。
因此,性能工程要结合实际产品制定合理、合适的性能标准。
系统的复杂性
作者认为被测系统是复杂的,进而导致2个问题:
- 寻找性能问题时,找不到分析的起点。
- 很多性能培训案例,是假定我们已知问题起点了。
- 比如:假定我们已经知道就是进程A的线程B疑似死锁了,于是演示各种工具如何证明是死锁。
- 关键我们怎么知道就是进程A有性能问题?怎么知道就是线程B有问题?怎么知道就是死锁问题?
- 解决性能问题时,往往牵一发而动全身。
- 修改死锁问题,可能CPU的瓶颈没有了。
- 但,应用程序继续往下一个环节运行,又引发了IO的瓶颈。
- 所以才有程序猿感慨:“时间是不可能被消灭的,只可能被转移。“

人员的协作性
作者根据经验总结了3个与人相关的问题:
- 性能工程涉及到产品研发体系的众多角色。比如:系统管理员、应用开发者、DBA、网络工程师。
- 角色间的部门墙可能导致性能工程断点。
- 即使是性能工程师,也可能专注于某个领域。比如:Java性能工程师、MySQL性能工程师等。
看来在哪儿都有部门墙,有人的地方就有江湖。

3.第二章笔记
Brendan Gregg在《性能之巅》第二章主要从6个方面讲了性能工程的方法论:
- 开展性能工程的21种方法
- 被测系统的架构
- 被测系统的模型
- 性能工程的2种分析视角
- 性能指标
- 性能工程涉及的数学模型
开展性能工程的21种方法
作者在这一段讲了21种性能工程常用的方法(英文anti-methodologies),译者生造了个词——讹方法。
讹方法?难道是讹人的意思?我选了两种方法说明一下:
街灯讹方法
作者讲了个故事:
有个醉汉在路灯下找钥匙,警察帮忙找了半天也没找到。
警察问醉汉确不确定就在这个路灯下丢的钥匙。
醉汉说:我也不确定,但是这里是最亮的。
这。。。
不就是某些程序猿定位性能问题但找不到切入点时,先随便怀疑一段代码,碰碰运气吗。。。
责怪他人讹方法
作者说了一下操作步骤:
第一步、找到一个不是自己负责的模块——注意,一定不是自己负责的模块!
第二步、假定问题就是这个模块造成的。
第三步、把问题扔给那个模块的负责人。
第四步、如果那个模块的负责人证明不是他的问题,重复步骤1。
这。。。
不就是某些程序猿最喜欢干的事儿吗——甩锅大法!!!
Brendan Gregg竟然给甩锅大法取了这么牛X的名字,还给出了甩锅的详细步骤。。。

赤果果的调侃
行了,这一段儿基本可以跳过了。。。
这一段儿就是作者一本正经地调侃。。。
当然,以作者的骚气,他在这么权威的书里面写出这种段子,我们也不应该太意外。。。

被测系统的架构
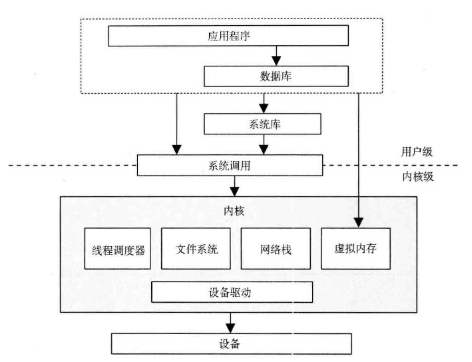
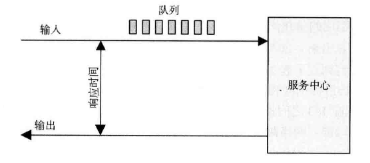
作者表达了1个观点和1个常用的架构:
- 1个观点:性能工程是针对整个系统(包括所有硬件和软件栈),实施性能工程前画出完整的架构图可以避免
只见树木不见森林。 - 1个常用架构:如下图。
被测系统的模型
- SUT模型:system under test
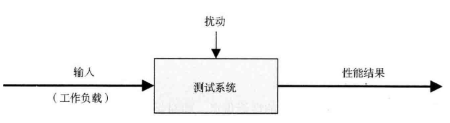
- 排队系统:这个模型很重要,作者贯穿全书的理念就是能将所有的性能问题都归纳为排队系统。
性能工程的2种分析视角
在梳理好被测系统的架构后,我们有两种选择:
- 自下而上:resource analysis,从硬件、内核、系统调用寻找资源瓶颈,进而定位到应用程序的进程、线程。
- 自上而下:workload analysis,从应用程序出发,找到资源瓶颈。
作者认为,其实两种分析视角要结合起来,才是最有效的性能工程方法。
性能指标
对于常用的性能指标就不展开了。如:延时、响应时间、时间量级、使用率、饱和度等。
作者重点展开了对缓存的基础知识介绍:
- 什么是缓存?
将数据不再存储在较慢的存储层,而是将数据存储到较快的存储层中。
- 典型的缓存?
CPU的L1、L2、L3缓存
- 缓存的命中率是什么?
命中率 = 命中次数 / (命中次数+失效次数)
- 失效率是什么?
每秒缓存失效次数
- 命中率、失效率与运行性能的关系?
运行时间 = 命中率 * 命中延时 + 失效率 * 失效延时
比如:
任务1的命中率很高(90%),失效率也很高(200/s)。
任务2的命中率略低(80%),失效率也很低(20/s)。
那么,最终任务2的性能会更好。
- 实现缓存的算法有哪些?
MRU:将最近最长使用的数据保留在缓存中。
LRU:将最近最少使用的数据移出缓存。
其它算法还有NFU、MFU、LFU。
- 缓存温度有哪些?
冷:命中率无限接近于0,比如缓存是空的。
热:命中率无限接近于预期的高度。
温:命中率还没有达到预期的高度。比如:缓存中存了一定有用的数据,但不全是有用的数据。
大白话一点,缓存机制的本质和海王海后的鱼塘逻辑差不多:
- MRU、LRU:MRU——最近经常撩的,加到鱼塘里、LRU——最近不咋联系的,踢出鱼塘。
- 命中率高、失效率低,性能好:鱼塘里都是鱼,鱼还很活跃,随便撩一下都是鱼,你说那啥效率高不高?

性能工程涉及的数学模型
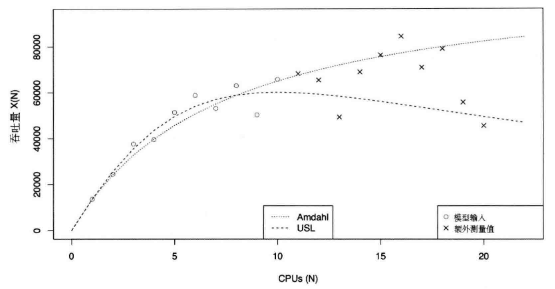
Amdahl扩展定律
由计算机科学家阿姆达尔,在1967年AFIPS春季联合计算机会议上提出。
这个阿姆达尔扩展定律的目的是为了预测性能优化到什么程度。
阿姆达尔定律本质上用严谨的公式证明了"木桶原理”——无法优化的那个部件决定了性能优化的上线。
如果:1个单线程的程序需要20小时,其中有1个小时无法并行化处理,
那么:将剩余19小时并行化了,最短执行时间也不可能小于1小时。
因此:我们就可以预测性能优化后可以加速20倍。
道理很通俗,但科学家需要严谨的公式推导,详细推导过程可以看看维基百科:
但阿姆达尔定律有一个缺陷:以上述案例,是不是我们19个小时的任务并行化,就一定可以将性能优化到1小时呢?
显然不是——随着CPU增加,可能会达到一个瓶颈点,随后无论怎么增加CPU,性能也不会优化了。
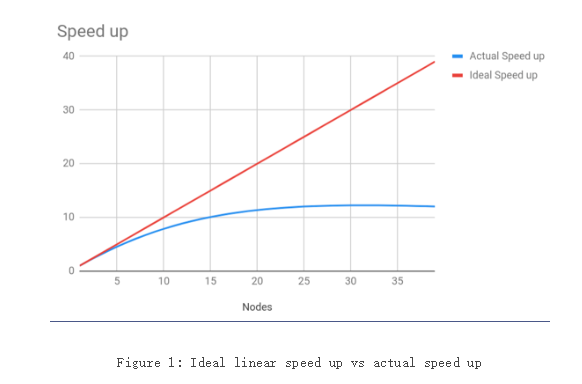
通用扩展定律
通用扩展定律:Universal Scalability Law,USL。由计算机科学家Neil J. Gunther于2008年提出。
这个定律就是用来更加精细化地预测:当我持续增加资源,实际的性能优化与阿姆达尔定律的理想化性能优化的偏移量。
排队论
Agner Krarup Erlang于1909年第一次提出了排队理论。
排队论描述了现实世界中有形、无形的各种排队场景。比如:12306抢票、网红店取号排队、超市排队买单等。
顾客肯定希望排队越短越好、办事儿时间越快越好。超市安排过多的收银员就浪费了,安排太少的收银员又会被顾客投诉。
顾客肯定不是按顺序一个个来超市,有可能在一个热点时间一拥而上来超市。
超市的排队规则是先到先处理,但是车牌摇号就是随机处理了。
……
上述这些,就是排队论研究的内容:
- 被服务者的到达遵循何种分布:如泊松分布。
- 服务机构的服务能力遵循何种统计特征:如每个收银员的处理速度。
- 排队的原则是什么:如先到先处理or随机处理。
- 排队的Topo结构:如超市最多放下10个收银台,那就有10条并行的排队结构。
最终排队论给出评估:
- 怎么排队,收益最大。
Brendan Gregg的核心观点是:
- 无论应用程序,还是CPU、IO、网络、磁盘都可以用排队模型化。
- 按照排队论,多种性能优化手段,最终一定有一个从"运筹学"上性能收益最大的选择。
理解排队论的推导,对于笔者还很困难,各位读者有兴趣可以参考相关资料:
https://zh.m.wikipedia.org/zh-sg/%E7%AD%89%E5%80%99%E7%90%86%E8%AB%96
基本统计指标
平均值、标准方差、百分位数、中位数、变异系数、多重模态分布、异常值,这些都是数理统计的基本概念,不赘述了。
4.第一章/第二章小结
- 未知的未知:Brendan Gregg的观点很赞,知道的越多就更容易知道自己的无知。
- 性能工程的视角:利用操作系统的工具链定位出CPU/内存/IO/网络的瓶颈找到性能切入点,进而定位到应用程序的进程/线程,虽然技能要求高,但能获得逻辑自洽的逻辑链,比撞大运靠谱。
- 性能工程的工程方法依托于数学:阿姆达尔定律、通用扩展定律、排队论,世界的尽头果然是数学啊。
5.参考文献
| |