从深圳返程的路上,开始阅读chatGPT的论文,努力理解其中精妙的理论与公式。
渴望真正理解chatGPT,所以写下我在学习过程中的思考,希望前辈高手指教。
1.从宏观看
1.1.软件内驱力,制约了目前的AI能力
(1)非AI程序的特点
当人类可以归纳出某种人类知识的规则、规律时,程序员就可以把它做成软件。
比如:客户需要开发1个路由器产品,路由器遵循的TCP/IP协议就是人类对网络通信的归纳总结。在软件行业的黑话称之为**“需求”、“规格”**。
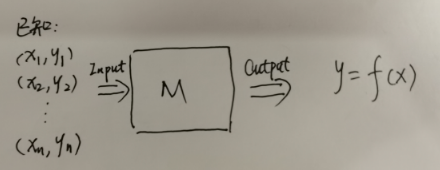
将非AI的程序抽象成如下公式,人类的工作重心就在函数f上:
- STEP1.归纳出函数f的规则、规律
- STEP2.交给人类程序员用某种编程语言实现出来
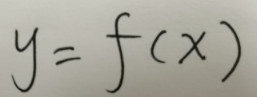
因此,产品研发过程中,某1个人类传递了错误的**“需求”、“规格”**,就会造成软件工程中经典的问题:

(2)AI程序的特点
当人类无法归纳出某种人类知识的规则、规律时,程序员实现某种数学工具的程序,该数学工具可以从已知的输入输出,自动归纳出规则、规律。
比如:我们需要实现计算机看一张照片,就知道这张照片里有一只狗。
人类如何归纳出"照片里具备怎样的特征就表示有一只狗"的规则、规律呢?
暂且把看图识狗的问题放一边,我们换1个更简单的例子:已知历史上每天的白菜价格(假定白菜价格满足某种线性规律),能否预测出明天的白菜价格?
我们可以把问题抽象为如下数学问题:
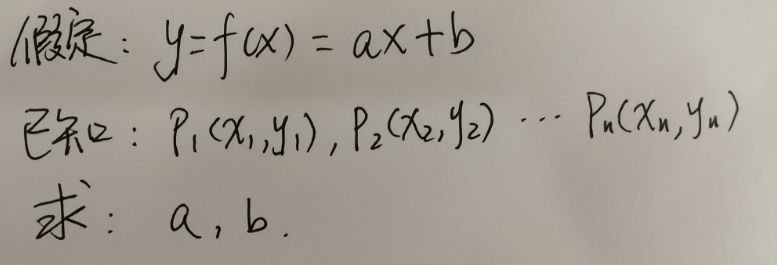
我们可以用最朴实的方法求解:
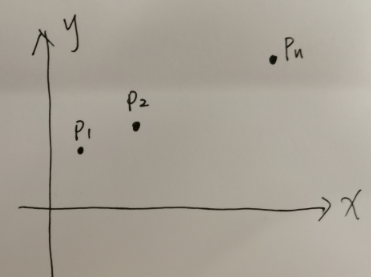
- STEP1.将p1、p2….pn在坐标系上描点
- STEP2.用蓝色线贯穿p1、p2….pn
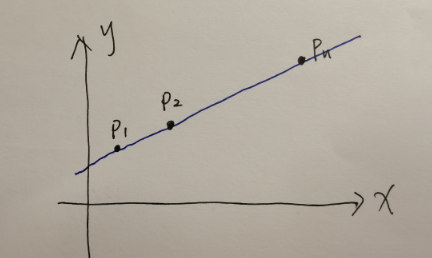
- STEP3.这根蓝色线即可确定a、b,即确定了函数f是什么
这个函数f就是从历史上众多白菜价格中归纳出来的规律、规则。
将AI的程序抽象如下,人类的工作重心在数学工具M上,而函数f由数学工具M自动/半自动产生:
(3)观点
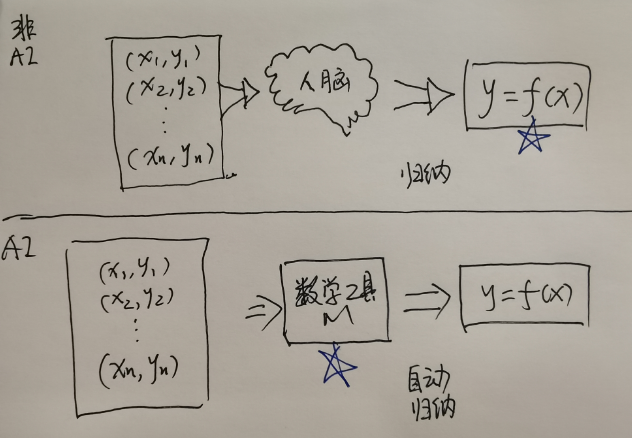
- 观点1:软件的内驱力是具备归纳能力的人脑或者数学工具。
- 对比两种程序,非AI程序的归纳来源于人脑,AI程序的归纳来源于数学工具。
- 观点2:如果期望机器像人一样思考,则必须满足数学工具的能力==人脑的能力。
- 非AI程序只能说是机器像人一样工作,而不是思考。
- AI程序中的数学工具的归纳能力和人脑持平,机器就真的像人一样思考了。
- 观点3:人脑作为创造了数学工具的造物主,有可能创造出等于甚至强于自身的数学工具吗?
- 这个问题和"万能的上帝能否造出自己举不动的石头?“是一样的,但未知的领域太大,未来或许可能。
- 无论未来是否可能,目前看起来很难。
1.2.计算理论,制约了AI解决问题的范围
(1)观点
面对人类和AI,我的观点是:
观点1:无论非AI程序,还是AI程序,最终都是用来解决世间万物问题的。
观点2:世间有一类问题是不可解决的,这种问题无论人类还是AI都无法解决。
观点3:世间还有一类问题是可解决的,其中一部分可以"彻底解决”,另一部分可以"委婉解决”,无论哪种,AI终将比人类做的好。
观点4:人类具有通过灵性突破不可解决的问题,和将"委婉解决"的问题降维成"彻底解决”,目前AI很难做到。
(2)不可判定问题
在计算理论中,不可解决的问题被称为不可判定问题,人类解决不了的问题,AI也解决不了。
- 比如:理发师宣称给全村所有不给自己刮胡子的人刮胡子就无法解决。
- 类似的问题还有"停机问题”、“上帝造石问题"等等。
- 但人类未知的领域太多了,可能在未知的领域,理发师可以做到他宣称的任务。
说明:计算理论用数学工具对世间所有问题进行了分类,可简单认为不可解决的问题是不可判定的问题,可解决的问题是可判定问题。
(3)判定问题
在计算理论中,对于可解决的问题被称为可判定问题,这些可解决的问题有分两类:
- 此类问题中的一部分可以直奔主题、彻底解决,在计算理论中叫P问题。
- 比如:计算一个圆的面积,知道了圆心和半径,就能彻底求解。
- 此类问题中剩余部分只能曲线救国,间接解决,在计算理论中叫NP问题。
- 比如:要给一张照片中的狗描边需要很高的计算成本,但要回答一张照片有没有狗,计算成本就会变得很低。
- 无论是P问题,还是NP问题,AI终将强于人类。
说明:计算理论针对可解决的问题,用数学工具进行了量化,通过计算时间表现解决这个问题的困难程度。
(4)灵感、灵性、灵魂
从解决问题的角度看,人类在如下两方面强于AI:
- 将不可判定问题转变为可判定问题,人类强于AI。
1935年,奥地利物理学家薛定谔提出了薛定谔的猫,直至今日众多科学家还在感叹自己从未懂得量子力学。
1851年,德国数学家黎曼分享了《论几何学作为基础的假设》,而在相隔近百年后爱因斯坦的《广义相对论的基础》中的空间几何采用了黎曼几何。
这些例子,就是人脑有机会将不可判定的问题转换为可判定问题,将未知变为已知。
- 将NP问题降维为P问题,人类强于AI。
和王志兄探讨的时候,他讲到了《模拟游戏》,以当时的算力无论如何都很难破解德军密码,山穷水尽时几个科学家在酒吧中灵感乍现,利用一个常用词,巧妙地简化了破解密码的过程。从计算理论看,破解密码是个NP问题,但因为其中反复出现的关键词,此问题降维成了P问题,也就是可求解的问题了。
再比如当今世界未解数学难题之一就是证明NP问题是否等于P问题,一旦证明了,世间众多难解问题都可以变为可求解问题了。比如:癌症这个NP问题,就变成可治疗的P问题了。
人类文明的跳跃总是这样:在浩渺的历史场合中,微醺中、睡梦中,灵光一现。
然而,人类的灵感、灵性、灵魂,似乎还没有数学公式可以表达。
这个话题不能再深聊下去了,再聊就哲学(身心二元论)和神学了。
1.3.小结:通用人工智能依然没有到来
通用人工智能,Artificial general intelligence,简称AGI。与之相反的就是弱人工智能(Weak AI),也叫做窄人工智能(Narrow AI)。通用人工智能与弱人工智能最大的区别就是是否具备认知能力。弱人工智能有点像绿野仙踪里没有心的铁皮人,他的梦想就是有一颗真正的心。
认知能力:详见https://en.wikipedia.org/wiki/Cognition

从前述的软件内驱力(驱动力)、计算理论(解决问题能力)看,除非发生了一种技术突变,否则机器要像人一样思考依然很困难。
但,AI技术在弱人工智能方向的确越来越强。我们接下来再从微观上做进一步分析。
2.从微观看
2.1.监督&无监督:只要狗粮撒的多,人工智能勉强行
(1)一个例子:是猫还是狗?
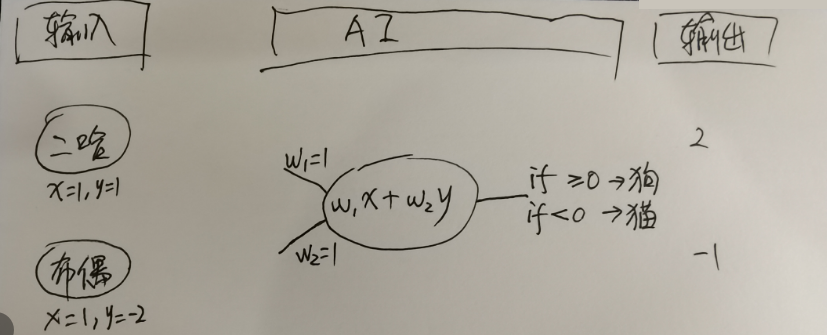
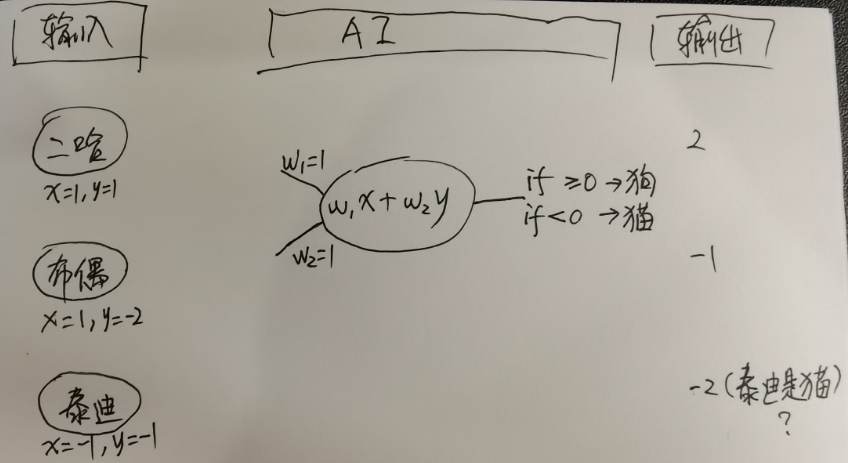
假设AI的数学工具为w₁x+w₂y(其中w₁初始值1,w₂初始化1),
并且,AI的数学工具输出表示:
- 如果数学工具输出>=0,则表示照片中是1只狗。
- 如果数学工具输出<0,则表示照片中是1只猫。
第一波学习:
输入第1张照片(是二哈,一种狗),二哈的数学表示为(x=1, y=1),则AI的数学工具输出2,进而推理出第1张照片是狗。
输入第2张照片(是布偶,一种猫),布偶的数学表示为(x=1, y=-2),则AI的数学工具输出-1,进而推理出第2张照片是猫。
第二波学习:
- 输入第3张照片(是泰迪,一种狗),泰迪的数学表达是(x=-1, y=-1),则AI的数学工具输出-2,进而推理出第3张照片是猫。
- 此时就错了,泰迪怎么可能是一种猫。
第三波学习:
- 此时,就要调整w₁和w₂,我掐指一算,调整为w₁=-1,w₂=1。
- 输入第1张、第2张、第3张照片,AI的数学工具输出为0、-3、0,进而可知二哈是狗、布偶是猫、泰迪是狗。
- 显然,w₁和w₂设计的合适,能够应对更多的照片,而不是每次输入一个新照片就要重新调整,这就是人工智能的黑话——泛化。
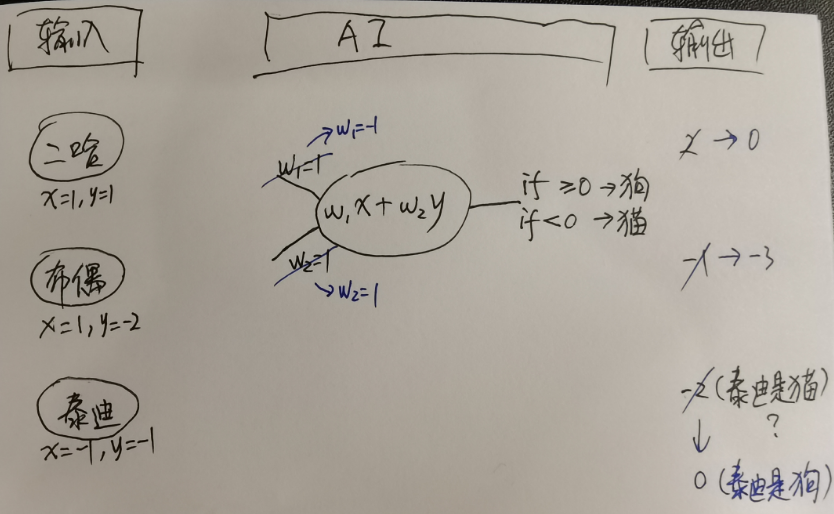
于是,不断地喂进去新的图片,不断地调整w₁和w₂……
于是,我师傅把上述过程叫做喂狗,这些图片就是狗粮。
(2)监督学习:狗粮的成本很高
根据前面的例子,首先需要人类准备好非常非常多的照片,并且人要标识出来每张照片是猫还是狗,这种学习方式就是监督学习。
这就好像有个人类小孩儿不太聪明,他爸爸要把世界上所有的习题册都买回来,爸爸还要把每一道题自己先做一遍,再来一道一道教这孩子。
在这种高昂的教学成本下,我们就可以看到父慈子孝的场面了:

(3)无监督学习:从狗粮中吸收的营养有限
与监督学习相对的,是无监督学习。无监督学习还是需要人类准备好非常多的照片,只是不需要人类把每一张照片都标注出是猫还是狗。
人工智能在学习过程中,也能学会猫和狗两类照片的差别,但是它并没有猫、狗的概念。
相当于,狗粮吃了,吸收的营养有限。
(4)感知机、LeNet、神经网络,喂狗工具在进化
除了考虑狗粮问题,从Perceptron感知机,到LeNet,再到神经网络,喂狗工具也在进化,这里给出动图,我们感受一下:
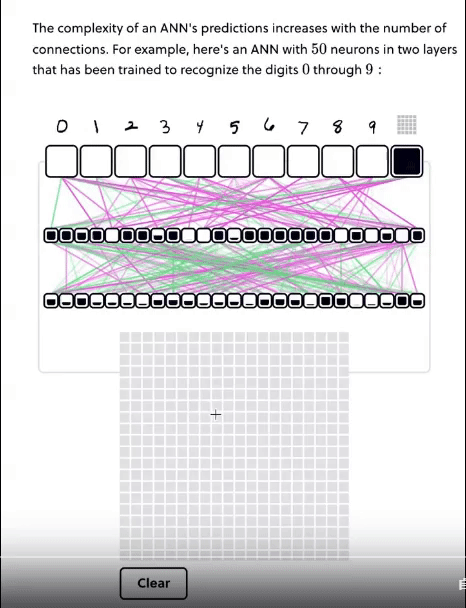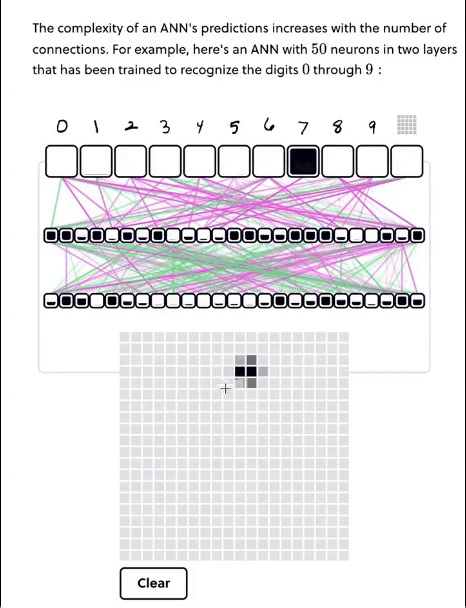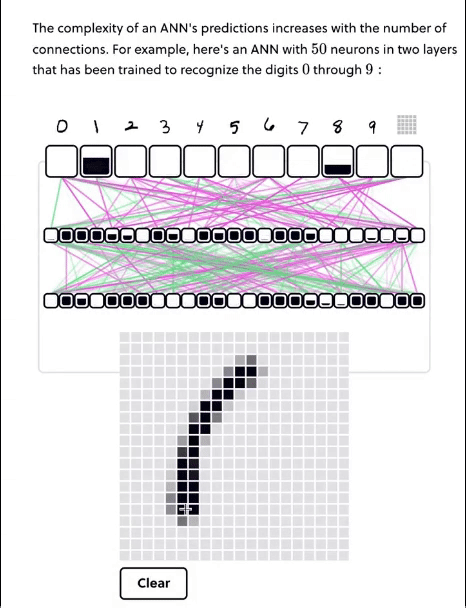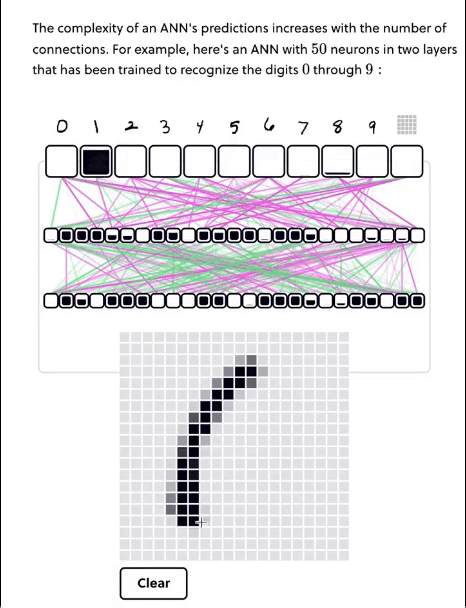
(5)观点
前面介绍了监督学习、无监督学习的方法论,可以看到:
- 观点1:对数据要求高,成本高。无论是数据清洗,还是数据标注,人工成本都很高。
- 观点2:方法论决定了AI的能力只能解决某些特定领域下的问题。
2.2.强化学习:没有狗粮去喂狗,人工智能还能行
(1)什么是强化学习
先看一个实验,对强化学习有一个直观感受:
- 机器人看到面前的架子,一次次地把盘子放到架子里,盘子碎了减分,盘子放好了加分。
- 机器人看到面前随机出现的杯子,一次一次地把水倒进杯子里,倒进去的水越多加分,反之减分。

强化学习中,有几个概念:
- Agent:智能体,可以简单地认为就是人工智能本身。
- Environment:环境,就是智能体所处的外在环境。
- Action:行为,智能体会不断尝试做出1个行为,触发环境发生变化。
- State:智能体观测环境发生此刻的状态。
- Reward:当智能体做出一个行为以后,环境会对智能体产生奖励,也可能产生惩罚。
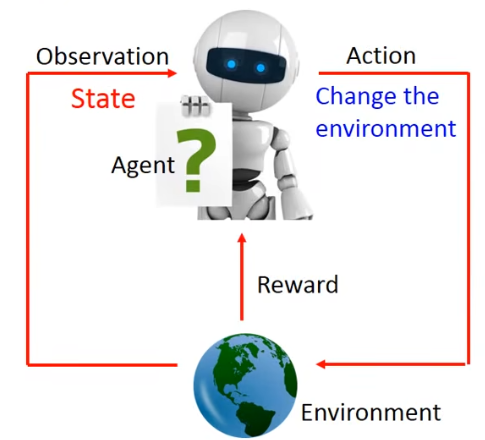
再看看强化学习的流程:
- STEP1.观察到**Environment(环境)中的State(状态)**有一杯水。
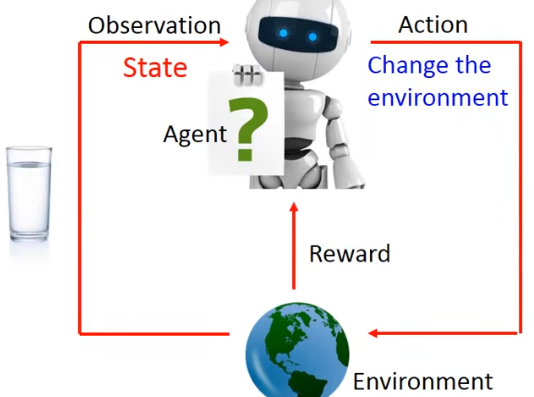
- STEP2.**Agent(智能体)做出了一个Action(行为)**打翻水。
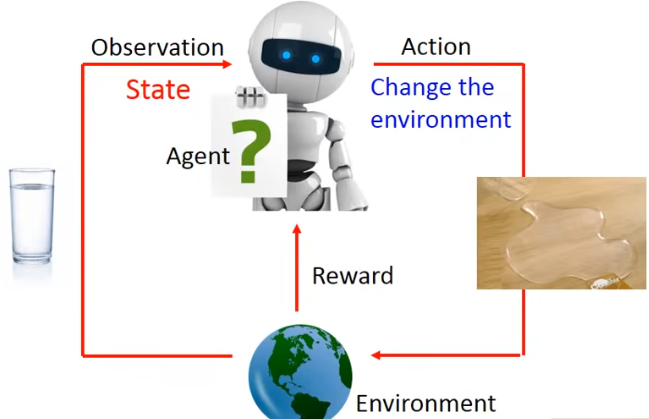
- STEP3.Environment(环境)产生了一个Reward(奖赏)——此时是个负向的奖赏——别那么做!

- STEP4.**Agent(智能体)再次看到的Environment(环境)的State(状态)**是水杯打翻了。
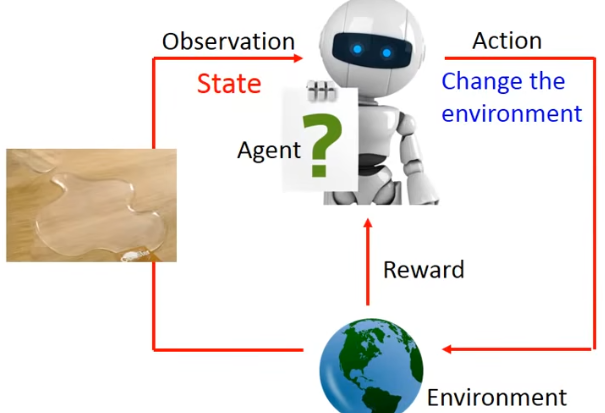
- STEP5.**Agent(智能体)做出了新的Action(行为)**把水擦干。
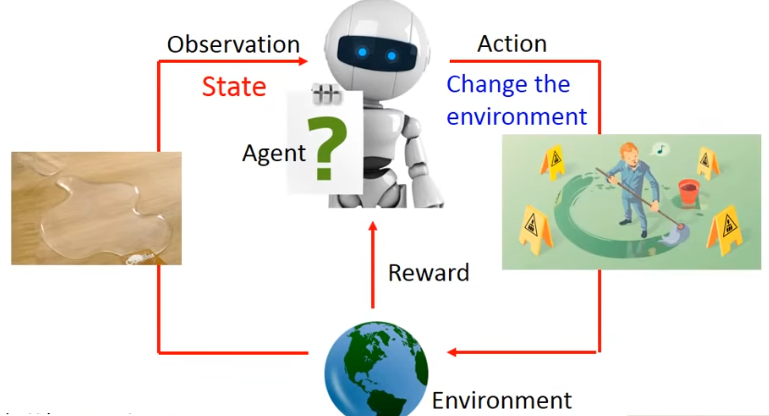
- STEP6.此时Environment(环境)发出的Reward(奖赏)——真棒
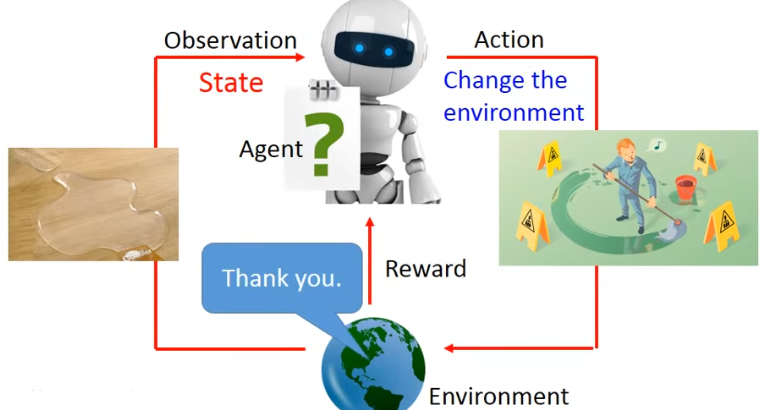
- 最终,人工智能学会了正确的选择。
(2)强化学习的核心思想:一次次的救赎
这有点像电影《Source Code》的剧情,男主不断地经历同一次循环,他在循环里的每一步都在寻找突破,最终突破循环。

作为人类的我,多么嫉妒人工智能具备的这种能力——后悔药——曾经有一份真诚的爱情放在我面前,我没有珍惜,等我失去的时候才后悔莫及,人世间最疼苦的事莫过于此。如果上天能够给我一个再来一次的机会,我会对那个女孩说三个字:我爱你。如果非要在这份爱上加一个期限,我希望是……一万年。

(3)强化学习的难点:延迟奖励&探索,突破灵性的灵犀一指
强化学习有两个难点:
- 延迟奖励:有一种可能——每一步都看起来得到最高的奖赏,但很可能最终还是输了整个游戏。这就是延迟奖励,前面几步不仅不要赢,反而要输,赢得最终的比赛才是关键——色即是空,空即是色。
- 探索:再就是不走寻常路,某一步忽然走了以前没做过的动作,意外地得到奖励,也可能失败,一把梭哈,撞个大运。
强化学习的这两个难点,就好像《天龙八部》中的珍珑棋局,那么多青年才俊都无法攻克,虚竹却胡乱下了一步(探索),死了一大片子却开拓了新的天地(延迟奖励)。如果再来从宏观层面谈,根据计算理论,虚竹这灵犀一指就是将不可判定问题变为了可判定问题,而这一指就是人类的灵性。

(4)观点
- 观点1:强化学习一定程度地解决了有监督、无监督中的狗粮问题。
- 观点2:由于没有直接告知答案,因此需要等待漫长的时间让机器去探索真理。所以强化学习的科学家们就是在不断优化其内部的数学工具,提升训练速度。
- 在强化学习中,有Policy-Based和Valued-Based两种策略,科学家为了解决策略梯度不好的问题,提出了TROP算法,chatGPT进一步改进了这个算法,就是PPO算法。
- 我们在本文中不必深入这些术语的公式、原理、细节,只需要大致有个印象,知道chatGPT用这个算法到底要解决什么问题。
- 观点3:强化学习的底层逻辑,其实就是主动学习、反复试错,你只需要给我时间,我并不需要你的狗粮。
- 这不仅仅是解决训练成本的问题,主动学习是人类的重要特质,主动学习能力或许是机器具备人类灵性的突破口之一。
- 观点4:强化学习的奖励机制,不一定是一个单纯的奖励模型,也可以是一个人类偏好模型。
- 感受自我、感知他人,这也是人类另一种重要特质,这也可能是机器具备人类灵性的突破口。
- chatGPT用了人类偏好模型,这就是为什么它会惊艳到很多人的原因之一,后文会讲到。
2.3.看chatGPT原理图
有了前文宏观层面建立的世界观,有了前文微观层面讲述的AI算法,我们可以来理解一下chatGPT的原理图了:
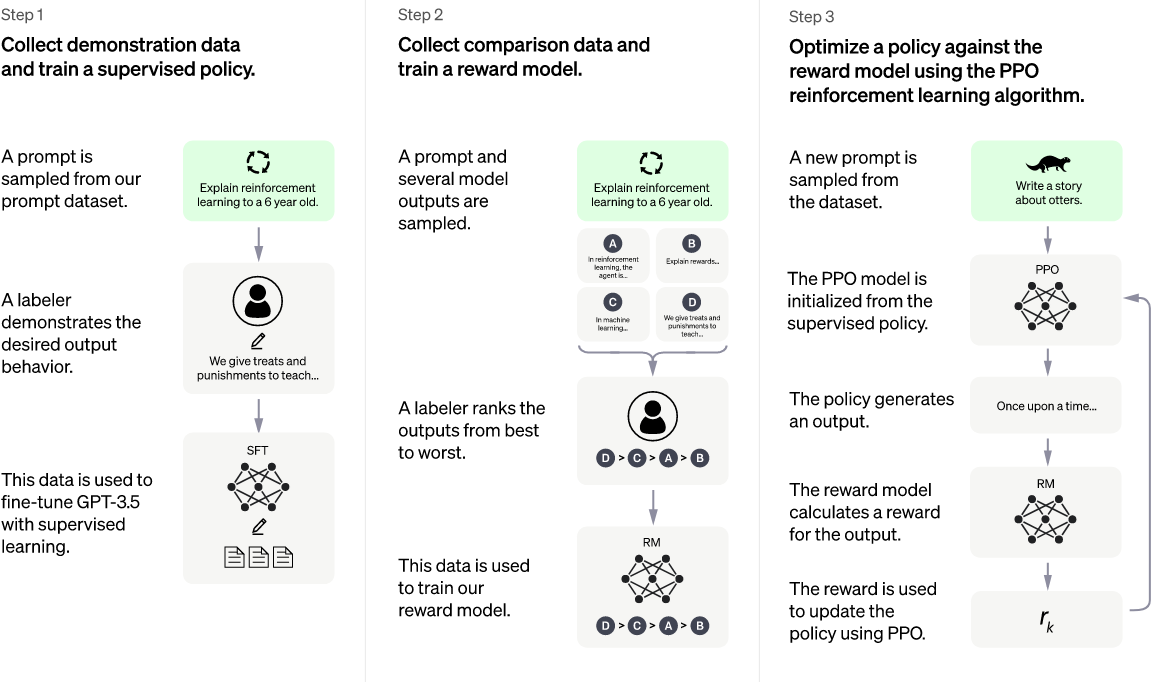
(1)拥有一个基础版本的聊天机器人
chatGPT第一阶段本质是监督+无监督,人类标注了一定数量的问题数据集,这里和大多数AI领域工程师现在的工作差不多。
在chatGPT,把训练的结果叫做SFT模型,本质就是获得了一个初级版本的聊天机器人。
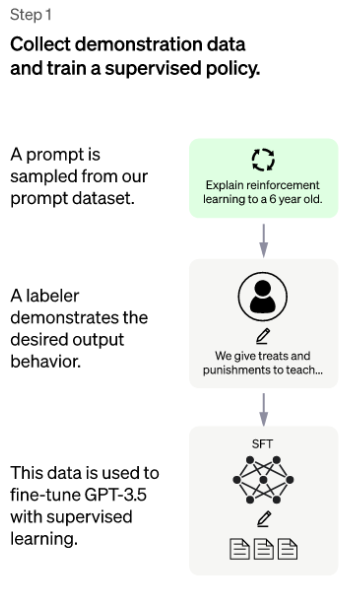
(2)关键步骤,我知道人类喜欢什么
第二步是关键步骤,用1个问题驱动SFT,机器人返回4个答案,人类只需要对这4个答案进行排序。
这太有创意了:一个人类回答问题是困难的(需要这个人类是这个问题的领域专家),但让人类判断哪个回答更好是简单的(这个人类只需要有一定的领域知识)。
排序也是一种标注,这个标注不再只是是猫是狗的简单标注,而是人类喜好!
chatGPT将这种人类喜欢叫做RM模型。
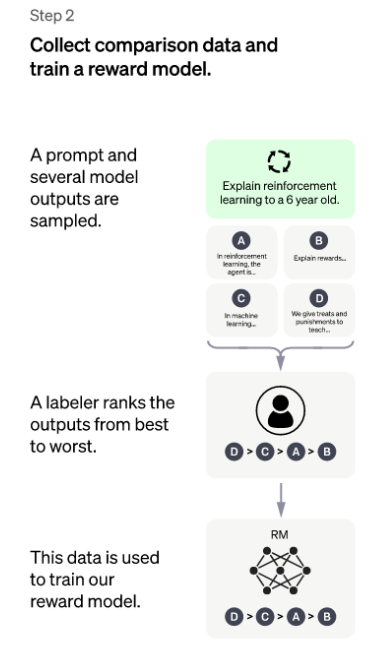
(3)学的快,我懂你
chatGPT到了第三步,似乎就水到渠成了。
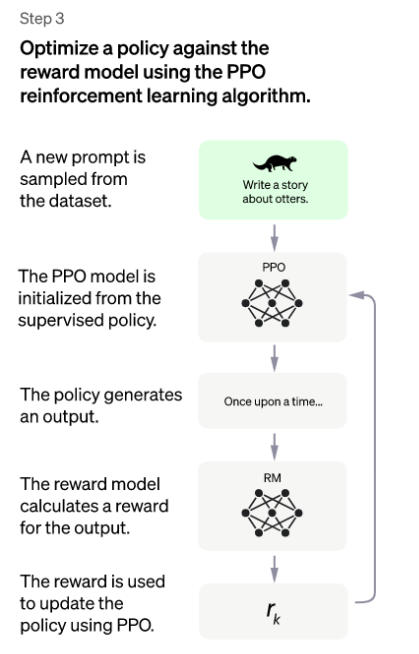
关于学的快,和人类学习一项新技能本质是一样的,抽象为两点:
- 学习有效信息:谷歌发明的注意力模型就是解决机器学习信息时,尽量像人一样关注到核心信息。
- 比如:下面这张图,我觉得大部分人类第一反应是注意到照片里有两匹马,而不是背后的风景吧(不过这里的风景真的很美)?

- 学的过程快:PPO算法是强化学习中的一个单点算法,优化梯度问题,本质还是解决学的过程要快。
关于我懂你,就是第二步的人类喜好模型RM:
- 将人类喜好模型作为奖赏,让机器人的回答不断解决人类喜好的那种回答。
- 这里面还有一个细节,回答类似输入法的自动联想,回答一个词就联想下一个词,下一个词的选择会遵循人类喜好模型。
一个人类的小孩,能从课本中提取到关键知识、理解关键知识很快、并且学习的目标一直围绕着正确的方向,这孩子一定是学霸。
这就是在正确的方向上强执行力地做事。
(4)观点
- 观点1:chatGPT并不是一个技术突变的产品,AI发展史上所有的技术都是被它使用的,能灵活运用已有的AI技术是值得我们学习的可贵之处。
- 观点2:宏观层面人类的灵性是强人工智能最大的挑战,但微观层面强化学习可能存在突破人类灵性的可能性。
2.4.小结:微观层面的术在不断进步
- 监督&无监督学习最大的问题是训练数据的成本,强化学习一定程度上解决了这个成本问题。
- chatGPT对强化学习的贡献在于:获得有效的知识(注意力模型)、高效的学习速度(PPO算法)、正确的努力方向(人类喜好模型RM)
3.理性思考、充满好奇、虚心求索
如果我的小伙伴们能看到这里,很感谢你们。这篇文章从提笔到写完,占用了我一周所有的业余时间。
chatGPT的论文涉及到的知识面太广,远超我的认知,同时由于给我的极大震撼,我又有太多想表达的内容。
在我的学习笔记第一篇,我选择表述我最感兴趣的话题——机器像人一样思考还有多远?
人类很多工作可能或正在被人工智能替代,这只能叫岗位转换,只是物理层面的替代。
拖拉机发明了,这个岗位的人类去做了别的岗位,但至今没看到人类被拖拉机统治。
很感谢学习过程中,身边有那些宏观、微观层面帮助我理性思考的小伙伴。
写这篇文章时,我被迫看了很多哲学和数学资料,比如:身心二元论、计算理论等等。
我们的世界底层逻辑还是数学和哲学,可惜功利的我不允许自己去探索这种没有既得利益的知识。
或许,我偶尔应该充满好奇,而不那么功利。
最后,面对国内对chatGPT的一片喧嚣,在努力弄懂chatGPT的原理之后,大致能分辨出哪些仅仅是停留在商业数据的分析伪洞察,哪些是没搞清How就乱给Do建议的伪分析。
虚心求索,欢迎小伙伴们共同研究这些有趣的技术、有趣的未来。