最近的专栏都是在拆解大语言模型的内部实现及论文,我们再来写点儿偏工程实践的内容——LangChain。
1.LangChain简介
(1)如何实现基于AI的App?
如果我们想开发一个基于大语言模型的AI知识库,怎么做呢?这个App的架构如下图:
- 准备环节:
- STEP1.数据管理:需要将垂直领域的知识进行词嵌入,放到向量数据库中。
- STEP2.提示词管理:需要构造好提示词模板。
- 微调&应用环节:
- STEP3.知识查询:将用户输入的自然语言问题向量化,寻找与输入问题相关的知识向量。
- STEP4.提示词查询:找到和输入问题有关的提示词模板。
- STEP5.调用大语言模型:将
知识向量+提示词模板传递给大语言模型(大语言模型可能在本地,也可能在云端,大语言模型可能是1个也可能是多个)。
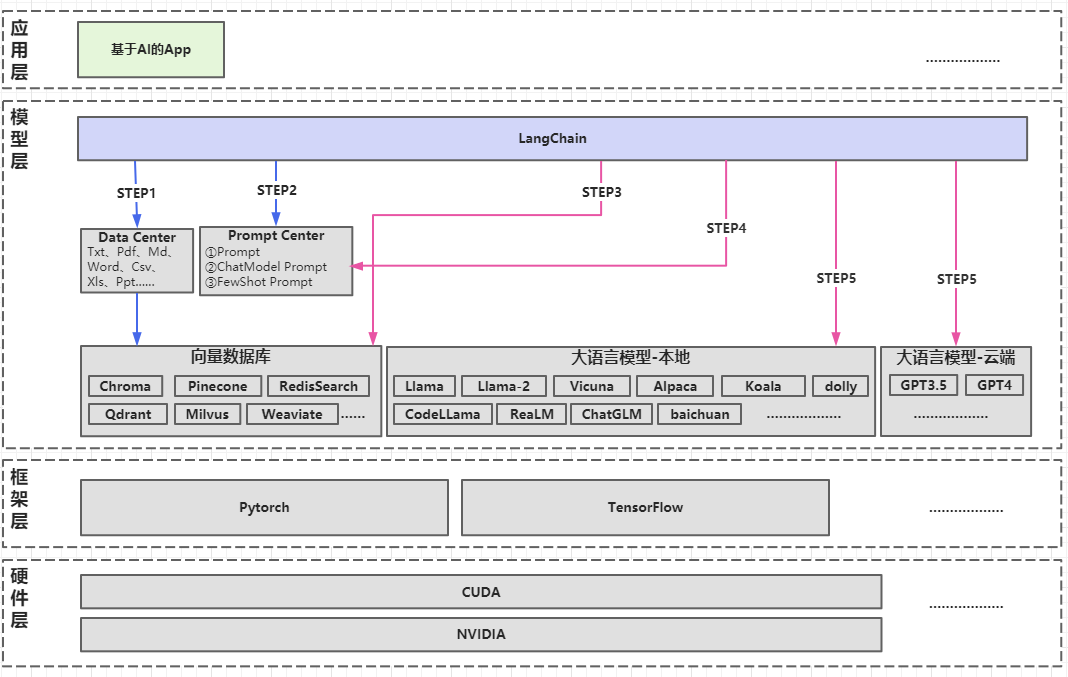
从这个架构可以看出,存在以下问题:
- 文档解析多样:垂直领域的知识文档,存在不同的文件格式,如何解析?
- 提示词需要复用:无论面向多少种不同厂商的大语言模型,提示词如何最大化复用?
- 模型多样:需要面向不同厂商大语言模型的不同调用接口,如何适配?
(2)RAG
LangChain,为私有知识库App这类应用,定义了一个新的领域——RAG(Retrieval Augmented Generation,生成式检索增强)。
在RAG领域,通常有5类需要考虑的因素:
- 文本处理:对各类型文档的加载,对文本的切分等。
- 向量存储:适配不同向量数据库,将文档内容向量化并存储。
- 提示词管理:创建提示词模板,最大化重用提示词。
- 模型适配:针对不同厂商,适配各类大语言模型的接口。
- 输出解析:对大语言模型输出的文本进行结构化解析。
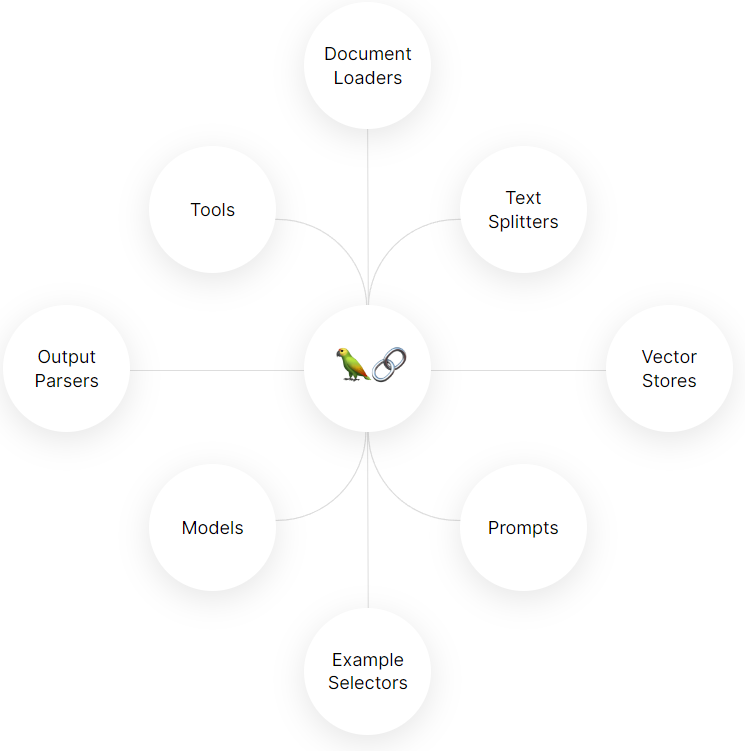
(3)LangChain的体系结构
LangChain为了解决RAG领域的五类问题,提供了6大模块,如下图:

我们在接下来的内容中,逐一解读各个模块的特性以及关键源码。
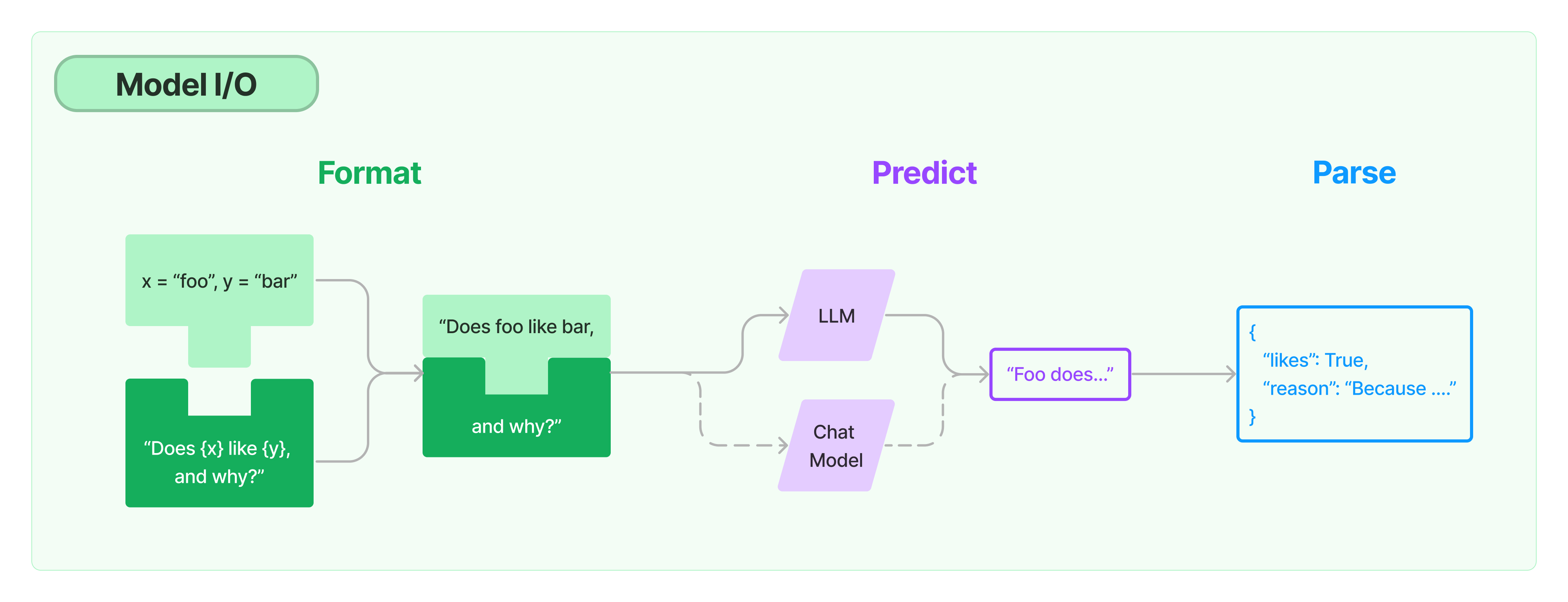
2.核心模块1:Model I/O
LangChain的第一个核心模块,就是
Model I/O。Model I/O最重要的能力就是封装了各大厂商大语言模型的不同接口。
Model I/O包括三个子特性:
- Prompts
- Models
- Output Parsers
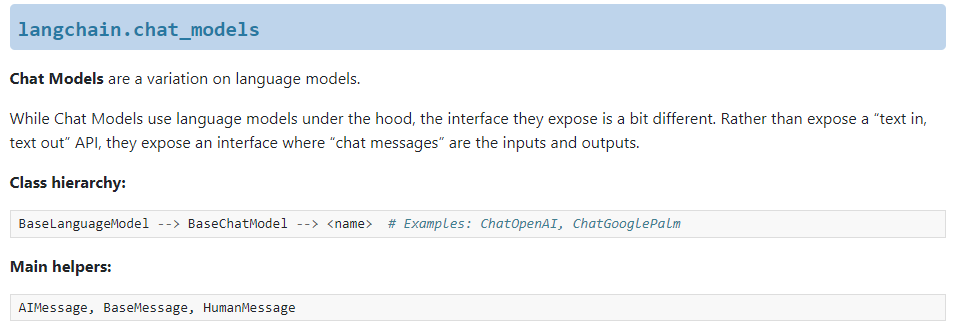
2.1.Models(模型)
- 在Models特性中,LangChain抽象了两类模型:
- 语言模型:LLMs,LangChain在这里封装了各厂商大语言模型的接口。
- 聊天模型:ChatModels,对语言模型的高层封装,提供输入一组聊天消息对象、输出聊天结果对象的模式。
2.1.1.LLM(语言模型)
(1)LangChain源码解读
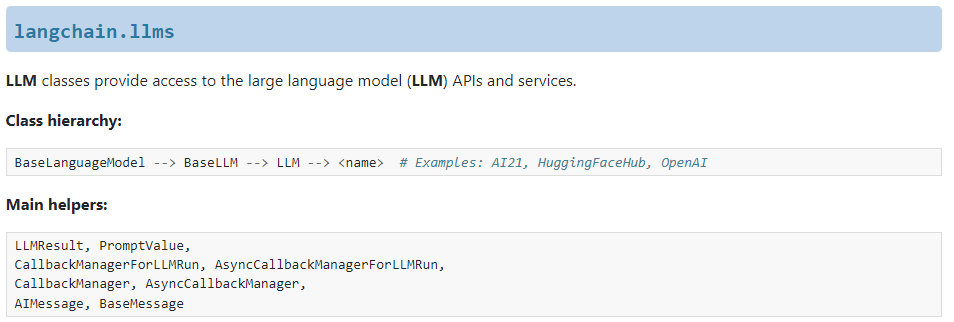
- LangChain通过3个关键类实现LLM:
- class BaseLanguageModel
- class BaseLM:继承class BaseLanguageModel
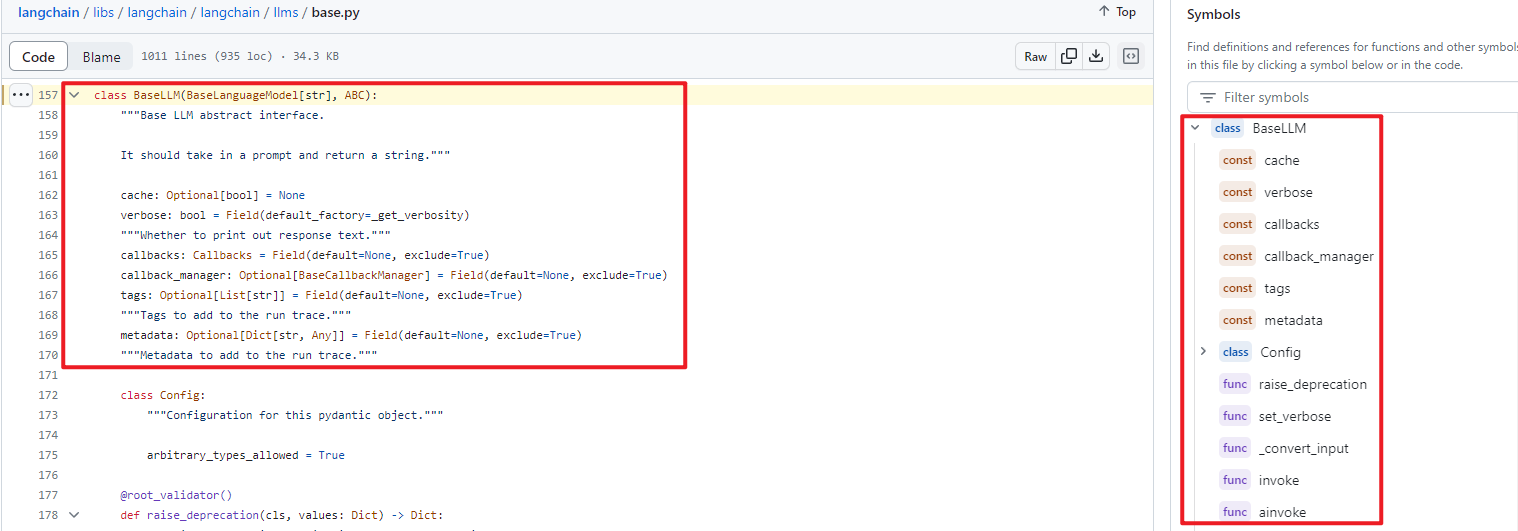
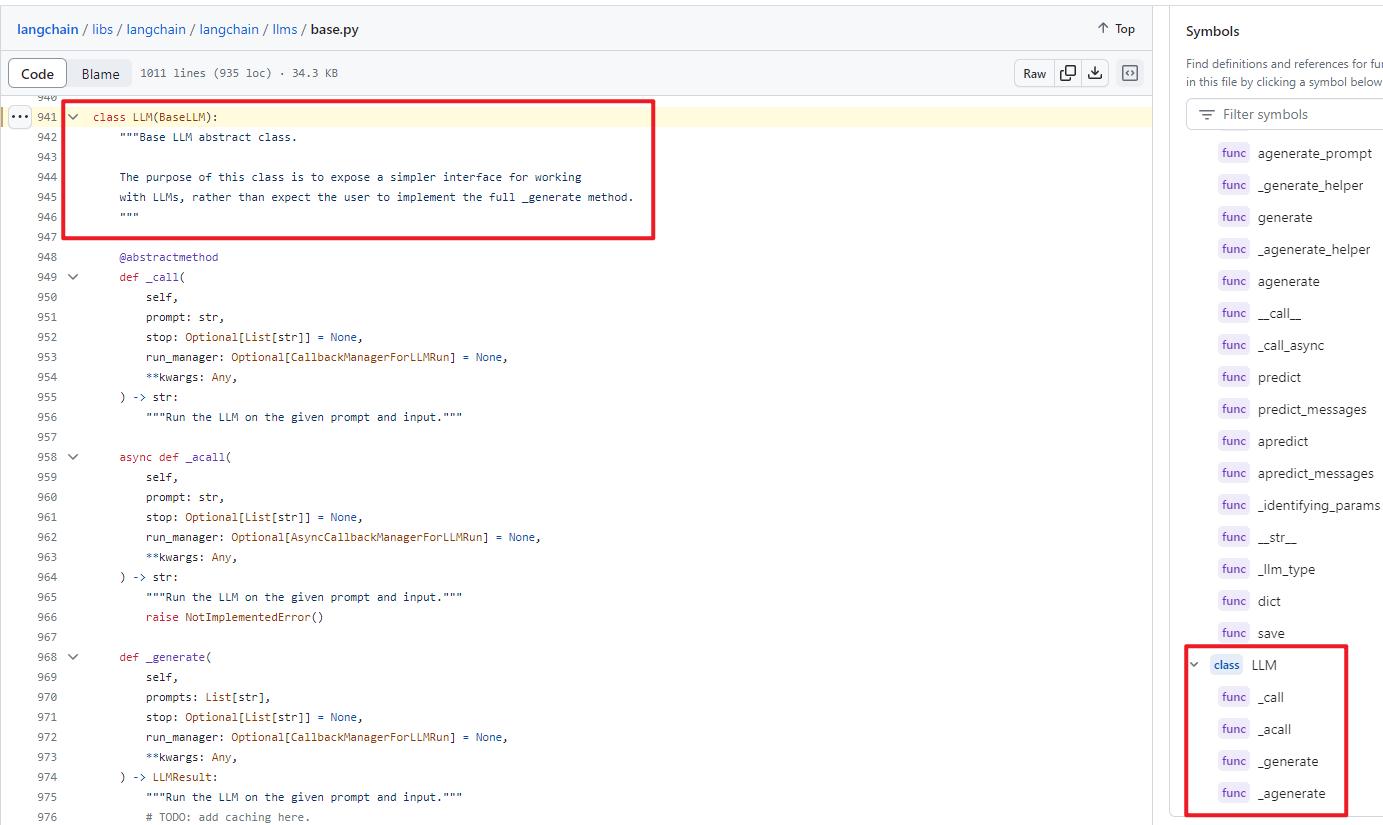
- class LLM:继承class BaseLM
- 与LLM相关的关键类如下:
LLMReusult,PromptValueCallbackManagerForLLMRun,AsyncCallbackManagerForLLMRunCallbackManager,AsyncCallbackManagerAIMessage,BaseMessage
class BaseLanguageModel:语言模型的基类,所有语言模型封装子类,都继承自本类。
- def generate_prompt:这是一个抽象函数,该函数由各个语言模型封装子类自行实现,输入提示词序列,输出是语言模型返回的结果。
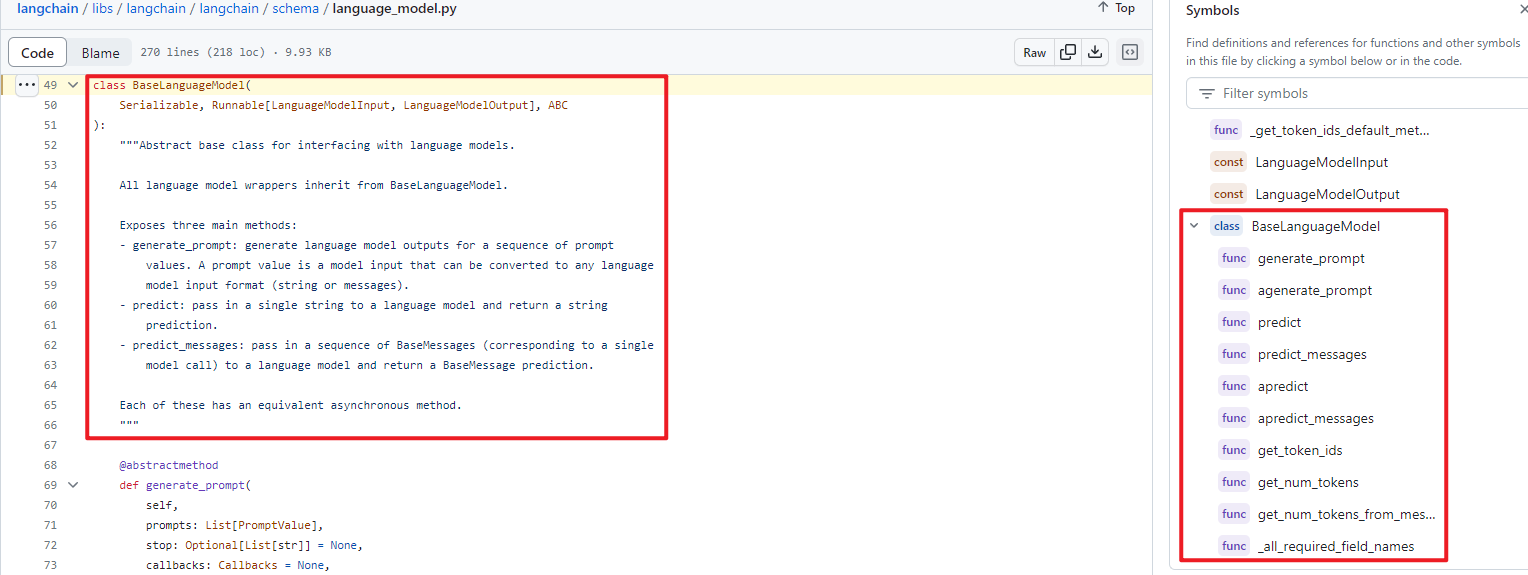
class BaseLLM:继承class BaseLanguageModel,实现了各语言模型封装子类的共性函数。
class LLM:继承class BaseLLM,进一步封装个语言模型封装子类的共性函数。
LangChain实现的各类语言模型封装的子类:
(2)例子
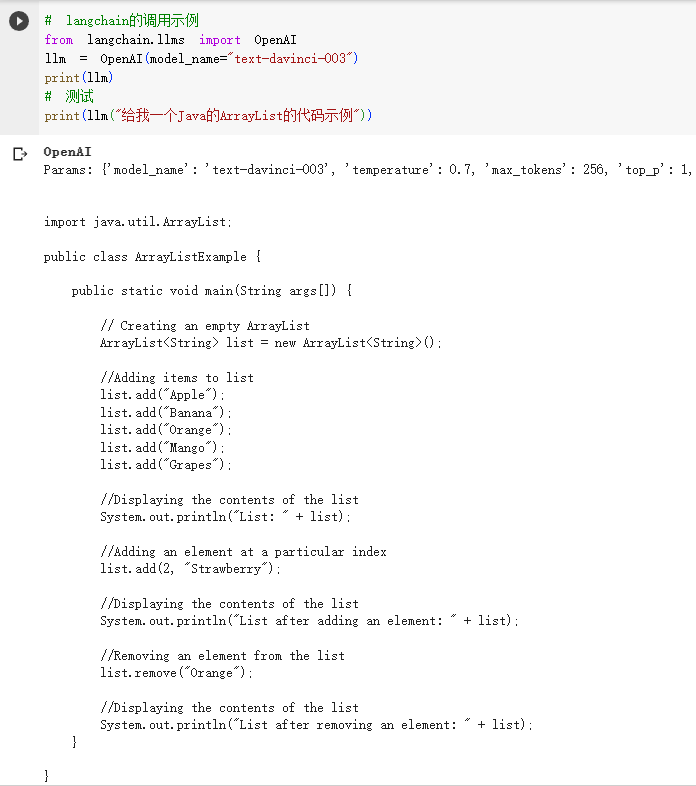
- 示例代码中,调用了GPT的达芬奇003模型。其中,class OpenAI就是对GPT的模型进行的封装。
- 输入:给我一个Java的ArrayList的代码示例。
- 输出:是一段ArrayList代码。
- 这样,就屏蔽了GPT的API未来可能的变化,适配是由LangChain完成的。
2.1.2.ChatModel(聊天模型)
(1)LangChain源码解读
- LangChain通过2个关键类实现聊天模型:
- class BaseLanguageModel
- class BaseChatModel:继承class BaseLanguageModel
- 相关的关键类如下:
AIMessage,BaseMessage,HumanMessage
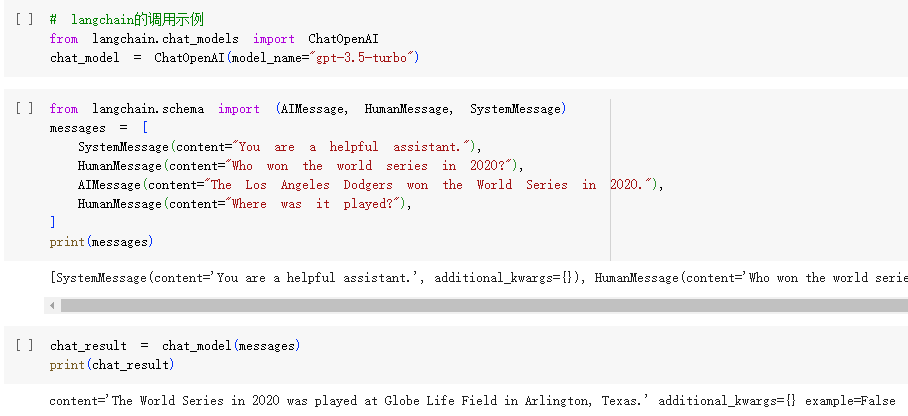
(2)例子
- 示例代码中,调用了GPT3.5 Turbo模型。其中,class ChatOpenAI就是对GPT的聊天模型进行的封装。
- 输入:一组聊天消息对象
- 输出:聊天消息的回答对象。
- 这样,就屏蔽了GPT的API未来可能的变化,适配是由LangChain完成的。
2.2.Prompts(提示词)
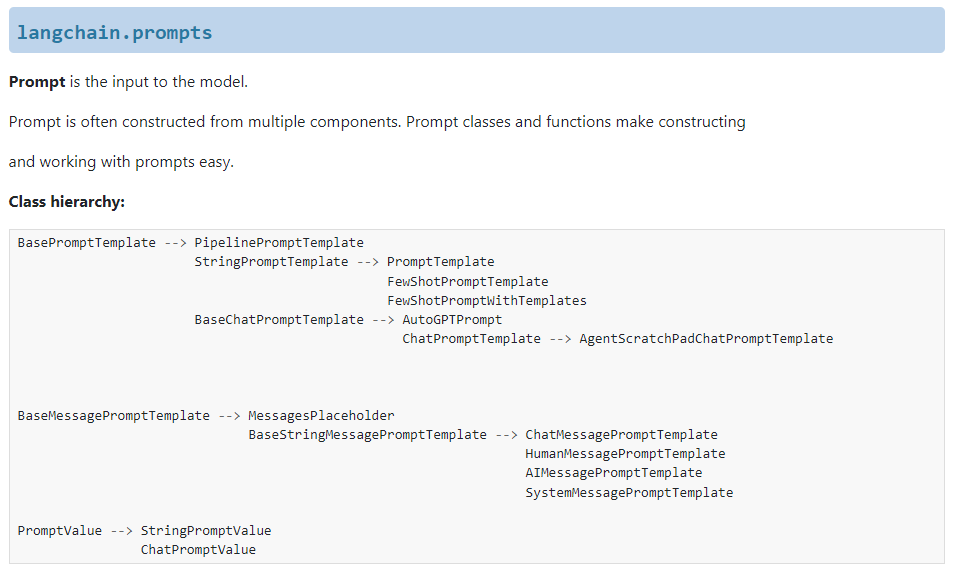
(1)LangChain源码解读
- LangChain通过2个关键类实现LLM:
- class BasePromptTemplate:基础提示词的基类。
- class BaseMessagePromptTemplate:聊天模型提示词的基类。
- 相关的关键类如下:
PromptValue
(2)例子-基础提示词
- 示例代码中,通过
from_template方法构造了提示词模版 - 调用时,传入了
lang变量,通过1个提示词模板,实现了生成java、python、C++的冒泡排序代码。 - 这样,就实现了一个模板引擎,最大化复用了提示词。

(2)例子-ChatModel提示词
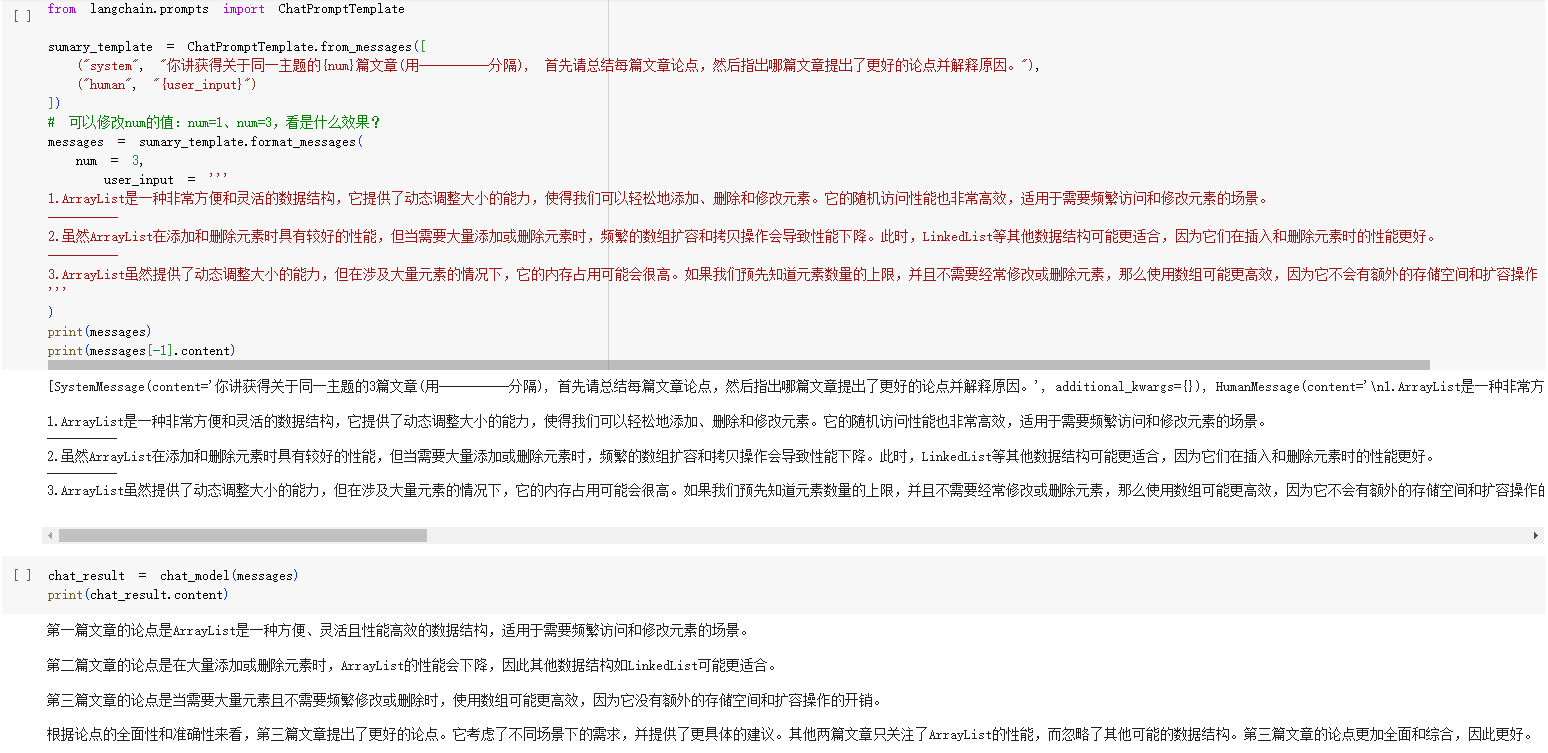
- 示例代码中,通过
from_messages方法构造了提示词模版 - 调用时,传入了
user_input变量,通过1个提示词模板,实现了生成对Java的ArrayList的知识点摘要。 - 这样,就实现了一个模板引擎,最大化复用了聊天模型的提示词。
(3)例子-FewShot提示词
- 示例代码中,通过
FewShotPromptTemplate构造了FewShot提示词模版 - 调用时,传入了
input变量,通过1个提示词模板,实现了一系列FewShot语料。 - 这样,就实现了一个模板引擎,最大化复用了FewShot的提示词。

2.3.Output Parsers(输出解析器)
- 输出解析器是一个很有趣的特性,大语言模型返回的答案是千奇百怪的,如何解析呢?
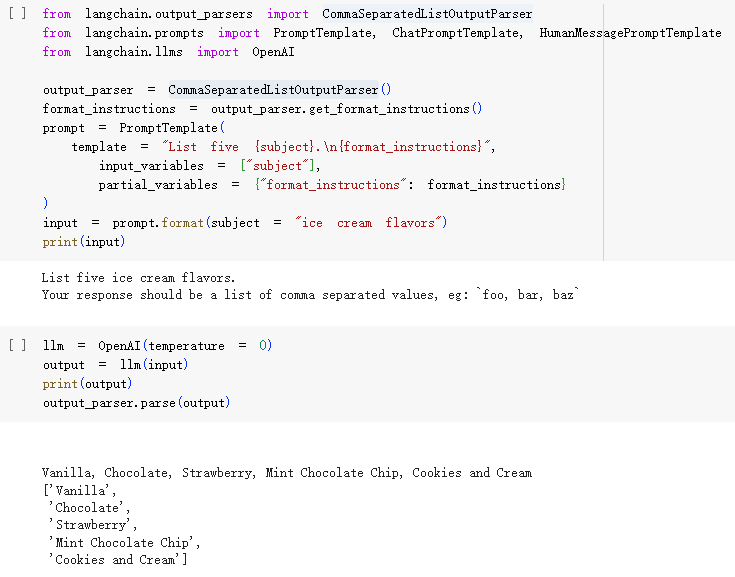
- 这里以
List Parser为例:- LangChain提供了class CommaSeparatedListOutputParser,这个类会在提示词中限定大语言模型的返回。
- 比如:输入的问题是
请问《圣斗士星矢》中,有哪几个主角?。 - class CommaSeparatedListOutputParser会构造提示词:Your response should be a list of comma separated values, eg:
foo, bar, baz。 - 大语言模型回答问题的文本就有了固定格式:
星矢、紫龙、冰河、瞬、一辉,这样就可以解析成list了。
3.小结
本文介绍了:
- LangChain的功能,为大家构建了对LangChain的宏观认识。
- LangChain的Model I/O核心模块:
- 该模块通过Models,抽象了各厂商的大语言模型,我们可以使用统一接口去调用不同的大语言模型。
- 该模块通过Prompts,提供了多种提示词模板的构建。
- 该模块通过Output Parsers,提供了对大语言模型输出结果的结构化解析。
后续文章,我们继续解读LangChain的核心模块,感谢阅读。