1.问题
在《【chatGPT】学习笔记9-Transformer之Seq2Seq,大语言模型的关键部件3》中,我们实现了Seq2Seq,看到了编码器-解码器架构的诸多优势。
但,Seq2Seq也有不完美的地方:
- 长距离依赖问题:读了后面,忘了前面。
- 信息压缩问题:Seq2Seq的上下文向量是固定长度的,很难将无限的信息压缩到有限长度的向量中。
这个视频,体现了长距离依赖问题和信息压缩问题:
- 长距离依赖问题:沈腾的几个问题,对于老大爷,都是听了后面忘了前面。
- 信息压缩问题:沈腾的每个问题,对于老大爷,字数都太多。
长距离问题、信息压缩问题的本质,都是信息损失的问题。
2.注意力机制的核心思想
理解了Seq2Seq的问题,我们会很自然地产生一种思路:如果将原始信息化繁为简,喂给LLM的是有效信息,而不是全量信息,是否可以解决长距离问题、信息压缩问题?
我们再来看一段视频:
- 从全量信息看,“关键问题"四个字高频出现。
- 从有效信息看,这么长一段话也就是一句有效信息——“关键问题很重要”。
在人类世界,这些没用的废话叫艺术。在AI的世界,这些没用的废话叫干扰。
从直觉上理解,人类接收信息时,会做两件事:
- 关注关键信息。
- 关注不同维度的关键信息。
比如:《八佰》这张海报,你看到了什么?
- 四行仓库:它是海报的背景,为什么会吸引观众的注意?
- 残垣断壁:正常的第一眼感觉是这里应该经历过多轮惨烈战斗,为什么我们不会关注断壁、废楼、电线杆的破坏程度?为什么我们不会关注零落的士兵?
- 对比鲜明:四行仓库和残垣断壁对比鲜明,我们应该可以感受到导演想表达的一种情绪。

上述这些,就是注意力,而且是不同维度的注意力:
- 当有人问”《八佰》这部电影发生的地点在哪里?",我们的注意力在”四行仓库"。
- 当游人问”《八佰》这部电影想表达什么主题?",我们的注意力在"四行仓库与残垣断壁"的对比鲜明——表现"八佰"勇士保卫上海最后一寸土地的英勇决绝。
论文《Attention Mechanisms in Computer Vision: A Survey》,更加形象化地展示了注意力在计算机视觉领域的实验效果:
- 我们可以发现,加入了注意力机制的AI,会更加关注原始图像中的关键要素。

3.注意力原理解读
接下来,我们尝试一下用代码实现一下直觉上理解的注意力机制。
3.1.点积注意力
首先,回顾一下点积的定义,特别关注一下点积的代数表达:
在数学中,点积又称数量积或标量积,是一种接受两串等长的数字序列(通常是坐标向量)、返回单一数字的代数运算)。在欧几里得几何,两条笛卡尔坐标向量的点积常称为内积。
从代数角度看,先求两数字序列中每组对应元素的积,再求所有积之和,结果即为点积。
从几何角度看,点积则是两向量的长度与它们夹角余弦的积。这两种定义在笛卡尔坐标系中等价。

然后,我们再来看看点积注意力:
- 假设:向量X1表示帅哥,假设向量X2表示美女。
- STEP1:计算X1和X2的点积
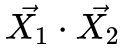 ,这个叫原始权重。
,这个叫原始权重。 - STEP2:对原始权重进行softmax
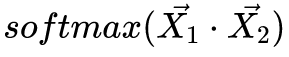 ,得到归一化注意力。
,得到归一化注意力。 - STEP3:计算归一化注意力与X2的加权和
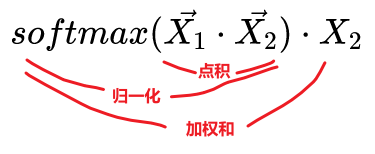 ,得到X1对X2的最终注意力。
,得到X1对X2的最终注意力。 - 结果:经过上述代数计算,最终注意力的信息主体肯定是X1,最终注意力还包含了X2的信息。因此可以这么理解:
- 向量X1表示:没有坠入爱河的帅哥。
- 最终向量表示:心中有美女的,坠入爱河的帅哥。
具体代码如下:

运行结果:

3.2.缩放点积注意力
在"3.1.点积注意力"的STEP2中,对原始权重进行softmax,可能由于原始权重过大导致梯度过小甚至梯度消失。
因此,缩放点积注意力的本质是对原始权重除以一个系数后,再进行softmax,具体如下:
- 假设:向量X1表示帅哥,假设向量X2表示美女。
- STEP1:计算X1和X2的点积,这个叫原始权重。
- STEP2:对原始权重缩放
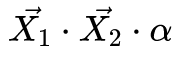 ,得到缩放权重。
,得到缩放权重。 - STEP2:对缩放权重进行softmax
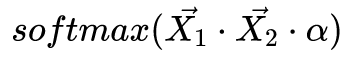 ,得到归一化注意力。
,得到归一化注意力。 - STEP3:计算归一化注意力与X2的加权和
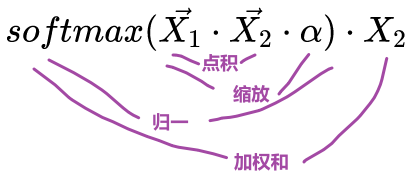 ,得到X1对X2的最终注意力。
,得到X1对X2的最终注意力。 - 结果:经过上述代数计算,最终注意力的信息主体肯定是X1,最终注意力还包含了X2的信息。因此可以这么理解:
- 向量X1表示:没有坠入爱河的帅哥。
- 最终向量表示:心中有美女的,坠入爱河的帅哥。
具体代码如下:

运行结果:

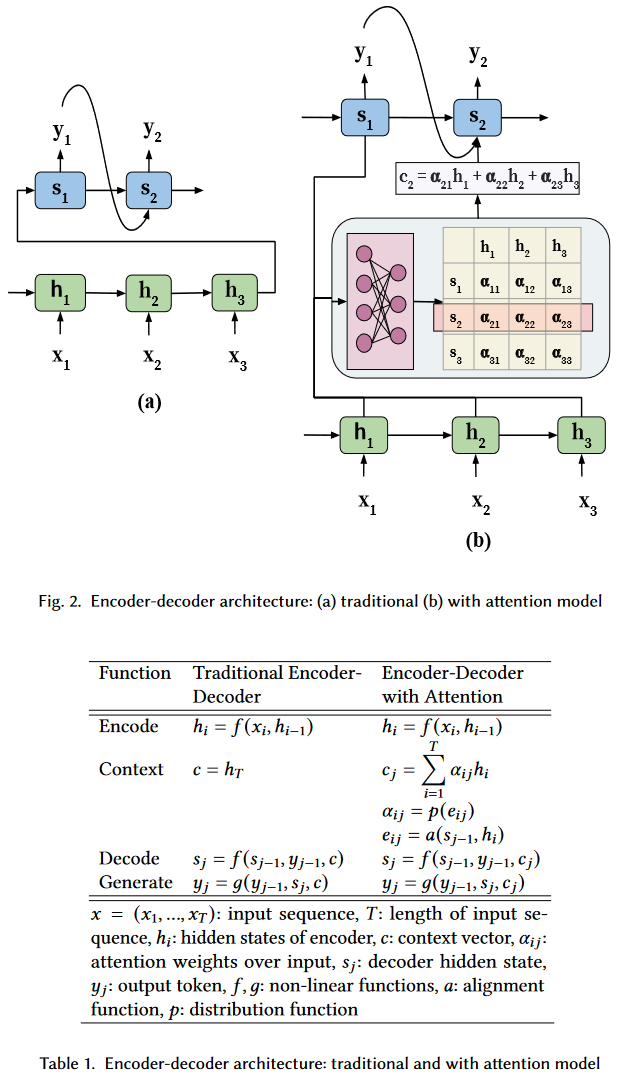
3.3.解码器-编码器注意力
有了缩放点积注意力,我们就可以尝试一下:对编码器-解码器架构增加注意力机制了。
回顾一下《【chatGPT】学习笔记9-Transformer之Seq2Seq,大语言模型的关键部件3》,我们详细分析了各个时间点上编码器、解码器的处理流程。截取t5和t6时刻:
- t5时刻:第一个解码器的输入是编码器输出的上下文向量+TeachForcing的第一个单词Who,第一个解码器的输出是最终答案的首词Who+隐藏状态。
- t6时刻:第二个解码器的输入是第一个解码器的隐藏状态+TeachForcing的第二个单词are+第一个解码器预测的最终答案的首词Who。
我们可以看出,每一个解码器的输入本质包含了三要素:
- 问题是什么:每个编码器输出的隐藏状态,但隐藏状态无法记忆太长的问题序列,所以每个解码器只知道问题的只言片语。
- 参考答案是什么:TeachForcing会告诉每个解码器,参考答案是什么。
- 上一个解码器的答案是什么:每个解码器都能知道上一个解码器预测的答案的一部分是什么。
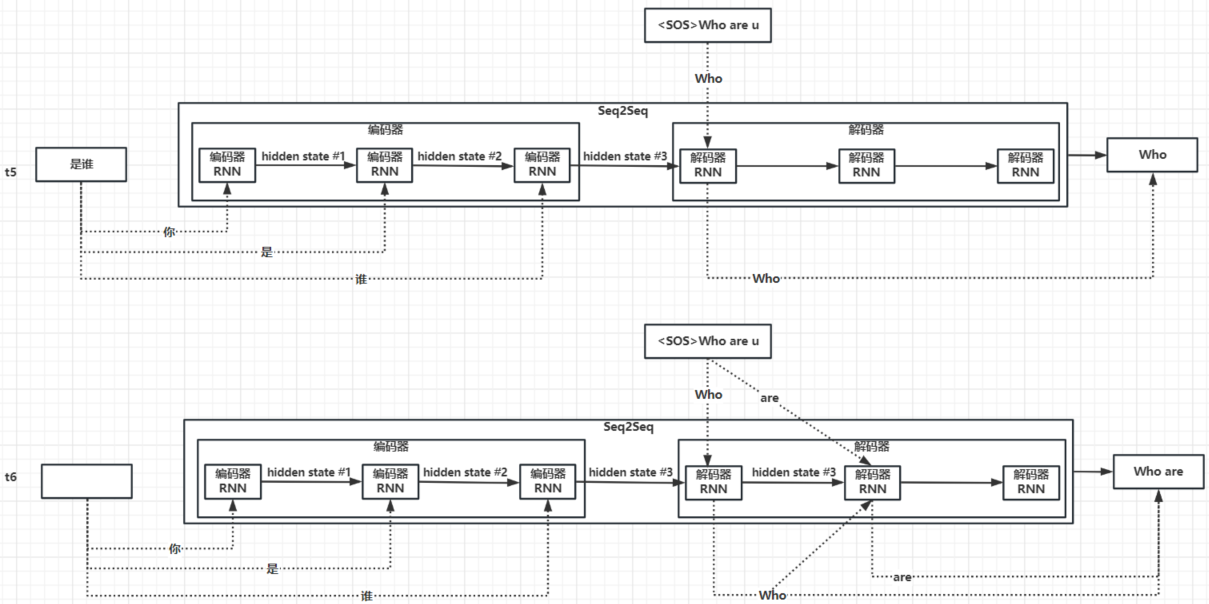
思考一下:注意力机制,可以如何优化编码器-解码器架构?
显然,只有优化"问题是什么"这个要素——如果我们将第一个解码器增加注意力层,就可以让输出的隐藏状态注意编码器输出的上下文向量——这样每个解码器就能用有限长度的向量了解原始问题中最关键的部分。
具体代码如下:




运行结果如下:
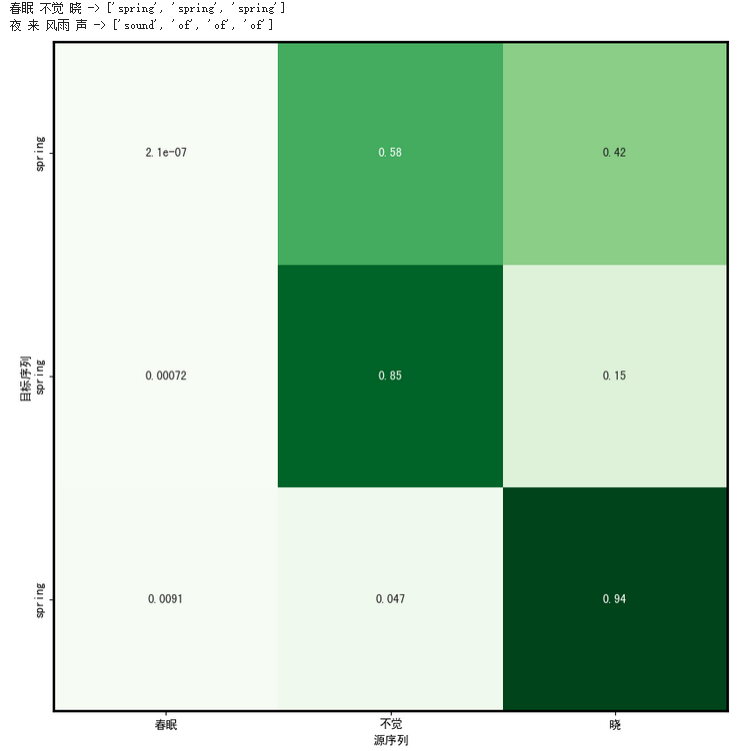
写到这里,我们要稍微小结一下(避免陷入术语、概念、数学公式的细节中):
- 神经网络架构:实现Seq2Seq的编码器-解码器架构,是神经网络架构中的一种。
- 注意力机制:注意力机制是一种专项技术,也有很多种实现,无论是哪一种,都是在解决神经网络架构的长距离问题、信息压缩问题。
如果您对编码器-解码器这种神经网络架构的细节记不太清,可以回看这篇《【chatGPT】学习笔记9-Transformer之Seq2Seq,大语言模型的关键部件3》。
如果您对注意力机制这种专项技术的细节记不太清,可以回看本文的点积注意力、缩放点积注意力、编码器-解码器注意力章节。
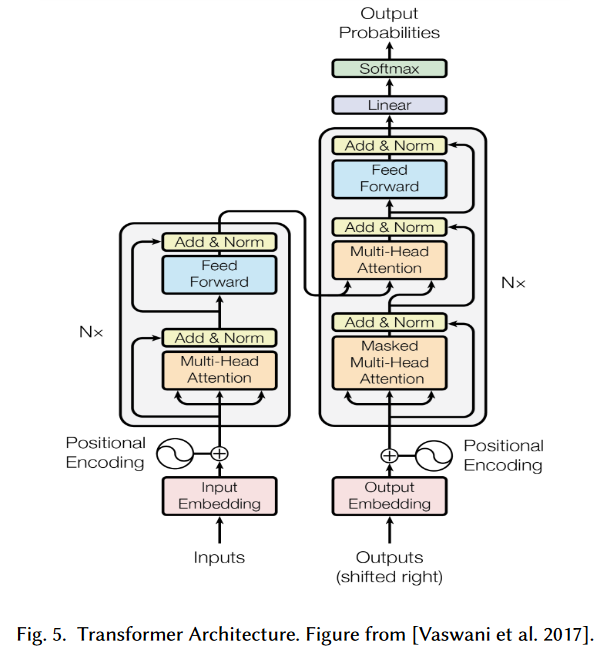
当我们对上述概念有了基本认识后,我们也就可以理解,自1990年注意力机制提出后,有很多科学家在思考:
- 有没有一种更好的神经网络架构,充分发挥这种仿人类的注意力机制的独特优势?
于是如雷贯耳的Transformer架构诞生了,于是如雷贯耳的论文《Attention Is All Your Need》诞生了。
笔者不在本文展开描述Transformer的实现原理,但我们可以在本文接下来的部分解读一下QKV、自注意力、多头注意力等Transformer架构中与注意力机制强相关的技术点,为后续解读Transformer做知识铺垫。
3.4.QKV
QKV注意力(query-key-value attention)是注意力机制中的一种变体。
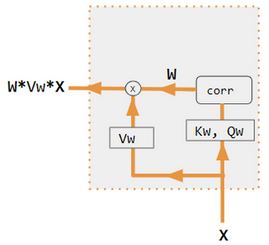
上图来自于维基百科,但维基百科对于QKV的介绍非常详细,但笔者试图给出这些过于理论化的QKV理论的通俗解释:
- 注意力机制的本质是让向量X1关注向量X2。
- Query,就是向量X1。
- Key、Value,就是向量X2。Key和Value的区别,仅仅是数学公式的差异(注意力权重、注意力权重加权和)。
- 向量X1,也就是Query,在编码器-解码器架构中,就是解码器输出的隐藏状态。
- 向量X2,也就是Key或者Value,在编码器-解码器架构中,就是编码器输出的上下文向量。
- 说白了,就是让每个解码器的输出都关注编码器输出的上下文向量。
我们来看一下代码:

3.5.自注意力
自注意力的理论也非常抽象,笔者试图给出这些理论的通俗解释:
- 注意力机制的本质是让向量X1关注向量X2。自注意力的本质是自己对自己的注意。
- Query,就是向量X1。
- Key、Value,也是向量X2。而向量X2的信息本质还是向量X1,只是线性变换的公式不同而已。
我们来看看实现自注意力的代码:

3.6.多头注意力
- 理解了QKV注意力,那么多头注意力仅仅是从更多维度对信息进行点积、缩放、Softmax、加权和而已。
具体代码如下:

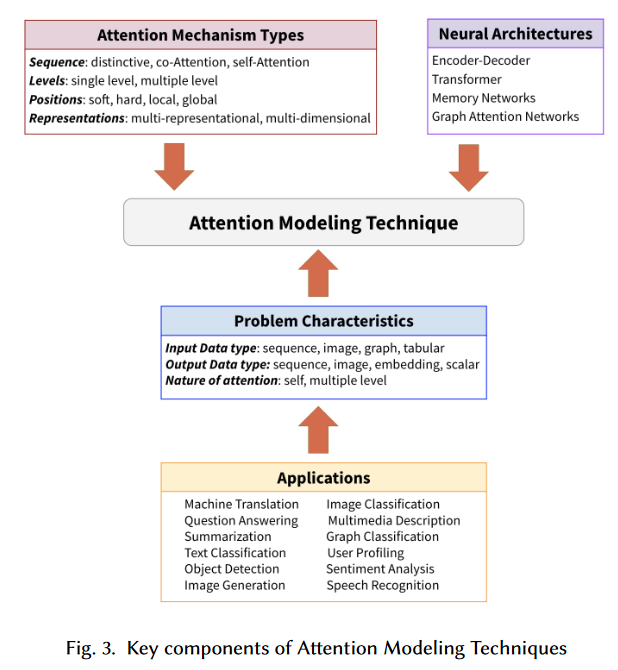
4.总结
- 本文通过介绍点积注意力、缩放点积注意力,进而解读了如何在编码器-解码器神经网络架构中,增加注意力机制。
- 本文的依据源于论文《An Attentive Survey of Attention Models》(https://arxiv.org/abs/1904.02874)
- 本文试图通过通俗的比喻、实际的代码,解读论文中复杂、抽象的算法流程。如下图:
- 本文进一步解读了QKV注意力、自注意力、多头注意力,为后续解读Transformer神经网络架构(如下图)奠定基础知识。
解读GPT背后的论文及实现技术实属不易,
从N-Gram到词嵌入,再到神经概率语言模型,再到Seq2Seq,直到本文的注意力机制,
我们距离自行实现一个简化版大语言模型越来越近了,同时笔者也受益匪浅。
欢迎各位小伙伴探讨交流,我们继续探索这个有趣的技术领域!