我们继续写点儿偏工程实践的内容——LangChain的核心模块2——Chain。
1.核心模块2:Memory
实现一个问答系统,通常需要将历史上的问题和答案,作为本次问题的上下文。
因此,LangChain提供了Memory模块,这个模块对记忆进行了抽象:
- STEP1.当用户提出问题时,LangChain会去读Memory,获得过去的消息past_messages。
- STEP2.LangChain构造提示词,格式为”{past_messages}{question}"。
- STEP3.LLM进行回答后,得到答案**{answer:…}**。
- STEP4.LangChain将本次的答案**{answer:…}**,**写入Memory**。
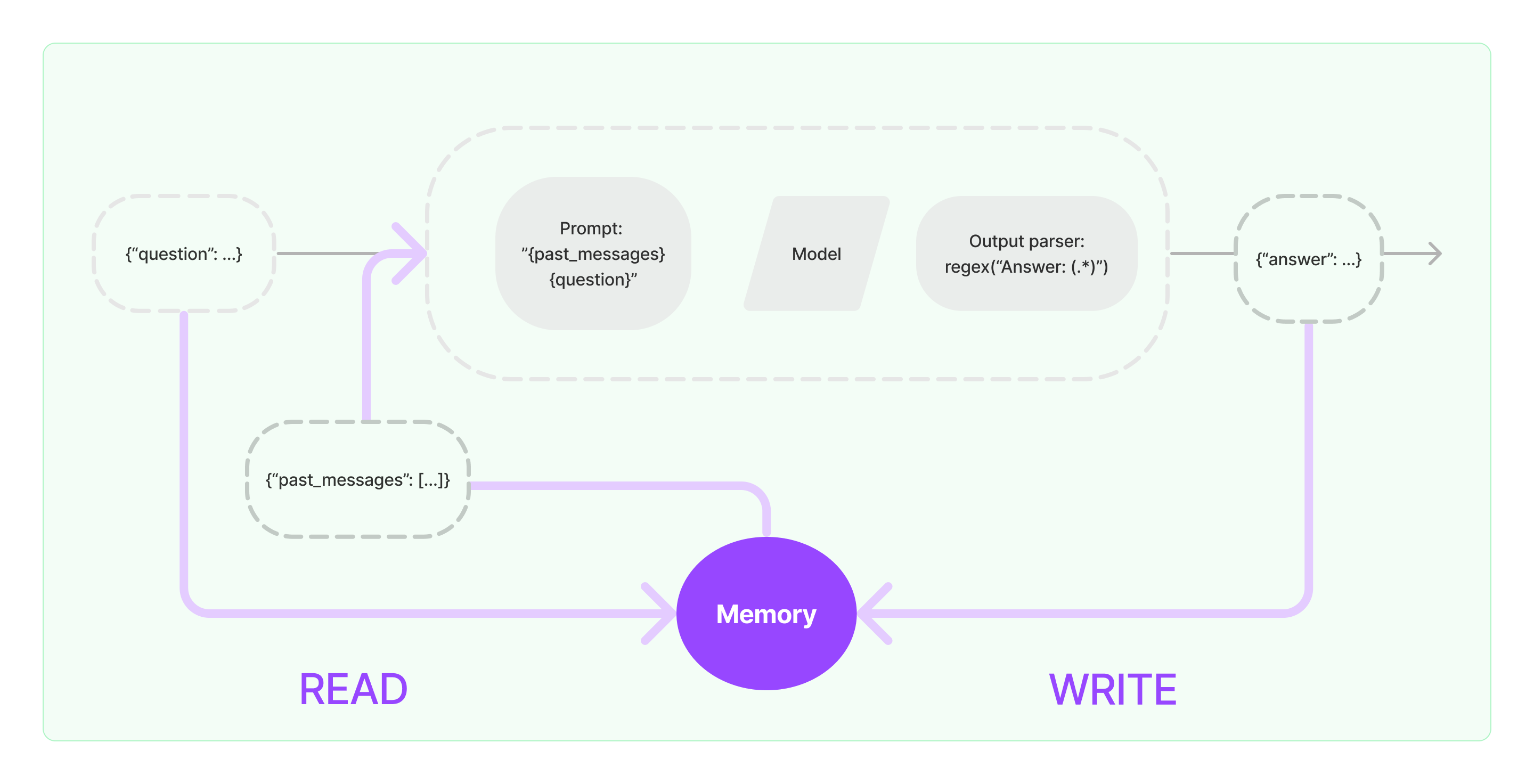
LangChain提供了多种ChatMessageHistory、ChatMemory,我们接下来详细解读。
1.1.ChatMessageHistory
- 类的继承关系:BaseChatMessageHistory –> ChatMessageHistory # Example: ZepChatMessageHistory
- BaseChatMessageHistory:聊天消息历史记录的基类,定义了一系列方法,由子类实现
- 代码路径/libs/langchain/langchain/schema/chat_history.py,详细源码如下:

1.2.BaseMemory
- 类的继承关系:BaseMemory –> BaseChatMemory –> Memory # Examples: ZepMemory, MotorheadMemory
- BaseMemory:Memory基类,定义了一系列方法,由子类实现
- 代码路径/libs/langchain/langchain/schema/memory.py,详细源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| class BaseMemory(Serializable, ABC):
"""Abstract base class for memory in Chains.
Memory refers to state in Chains. Memory can be used to store information about
past executions of a Chain and inject that information into the inputs of
future executions of the Chain. For example, for conversational Chains Memory
can be used to store conversations and automatically add them to future model
prompts so that the model has the necessary context to respond coherently to
the latest input.
这里的内存指的是Chains中的状态。内存可以用来存储Chain过去执行的信息,并将信息注入到Chain的未来执行的输入中。
例如:对于会话型Chains,内存可以用来存储会话,并自动将它们添加到未来的模型提示词中,以便模型具有必要的上下文来连贯地响应最新的输入。
class Config:
"""Configuration for this pydantic object."""
使用pydantic库,并在本类中定义抽象方法,待子类实现
arbitrary_types_allowed = True
@property
@abstractmethod
def memory_variables(self) -> List[str]:
"""The string keys this memory class will add to chain inputs."""
@abstractmethod
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
"""Return key-value pairs given the text input to the chain."""
@abstractmethod
def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, str]) -> None:
"""Save the context of this chain run to memory."""
@abstractmethod
def clear(self) -> None:
"""Clear memory contents."""
|
1.3.BaseChatMemory
- BaseChatMemory:BaseMemoryd的子类,实现了一部分通用方法,剩余由子类扩展
- BaseChatMemory维护了ChatMessageHistory
- 代码路径/libs/langchain/langchain/memory/chat_memory.py,详细源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| class BaseChatMemory(BaseMemory, ABC):
"""Abstract base class for chat memory."""
chat_memory: BaseChatMessageHistory = Field(default_factory=ChatMessageHistory)
output_key: Optional[str] = None
input_key: Optional[str] = None
return_messages: bool = False
def _get_input_output(
return inputs[prompt_input_key], outputs[output_key]
def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, str]) -> None:
"""Save context from this conversation to buffer."""
input_str, output_str = self._get_input_output(inputs, outputs)
self.chat_memory.add_user_message(input_str)
self.chat_memory.add_ai_message(output_str)
def clear(self) -> None:
"""Clear memory contents."""
self.chat_memory.clear()
|
接下来就可以看一下常用的几种Memory了。
1.4.ConversationBufferMemory
- ConversationBufferMemory:一种Memory的具体实现。提供了记录历史聊天记录的能力。
- 代码路径/libs/langchain/langchain/memory/buffer.py,详细源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
| class ConversationBufferMemory(BaseChatMemory):
"""Buffer for storing conversation memory."""
human_prefix: str = "Human"
ai_prefix: str = "AI"
memory_key: str = "history" #: :meta private:
@property
def buffer(self) -> Any:
"""String buffer of memory."""
return self.buffer_as_messages if self.return_messages else self.buffer_as_str
@property
def buffer_as_str(self) -> str:
"""Exposes the buffer as a string in case return_messages is True."""
return get_buffer_string(
self.chat_memory.messages,
human_prefix=self.human_prefix,
ai_prefix=self.ai_prefix,
)
@property
def buffer_as_messages(self) -> List[BaseMessage]:
"""Exposes the buffer as a list of messages in case return_messages is False."""
return self.chat_memory.messages
@property
def memory_variables(self) -> List[str]:
"""Will always return list of memory variables.
:meta private:
"""
return [self.memory_key]
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
"""Return history buffer."""
return {self.memory_key: self.buffer}
|
我们再来看一个例子:

- 针对第一个问题,LangChain发送给LLM真实的问题如下:

- 针对第二个问题,LangChain会把第一次发给LLM的问题和答案+第二次的问题发送给LLM:

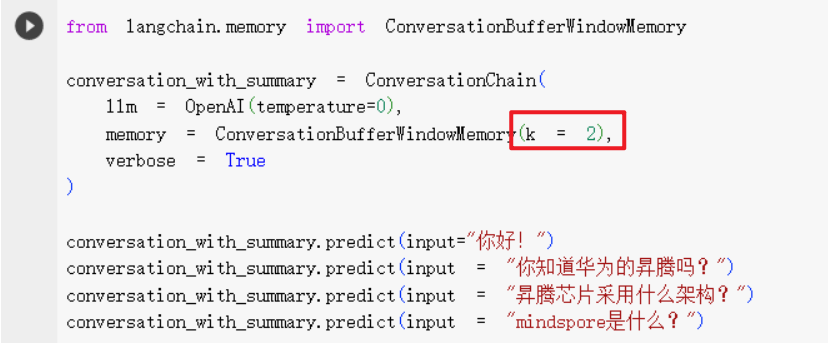
1.5.ConversationBufferWindowMemory
- ConversationBufferWindowMemory:一种Memory的具体实现。提供了带有滑动窗口的记录历史聊天记录的能力。
- 代码路径/libs/langchain/langchain/memory/buffer_window.py,详细源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
| class ConversationBufferWindowMemory(BaseChatMemory):
"""Buffer for storing conversation memory inside a limited size window."""
human_prefix: str = "Human"
ai_prefix: str = "AI"
memory_key: str = "history" #: :meta private:
k: int = 5
"""Number of messages to store in buffer."""
@property
def buffer(self) -> Union[str, List[BaseMessage]]:
"""String buffer of memory."""
return self.buffer_as_messages if self.return_messages else self.buffer_as_str
@property
def buffer_as_str(self) -> str:
"""Exposes the buffer as a string in case return_messages is True."""
messages = self.chat_memory.messages[-self.k * 2 :] if self.k > 0 else []
return get_buffer_string(
messages,
human_prefix=self.human_prefix,
ai_prefix=self.ai_prefix,
)
@property
def buffer_as_messages(self) -> List[BaseMessage]:
"""Exposes the buffer as a list of messages in case return_messages is False."""
return self.chat_memory.messages[-self.k * 2 :] if self.k > 0 else []
@property
def memory_variables(self) -> List[str]:
"""Will always return list of memory variables.
:meta private:
"""
return [self.memory_key]
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
"""Return history buffer."""
return {self.memory_key: self.buffer}
|
我们看一个例子:

- 第一次问答:LangChain真实发送的问题只有"你好”

- 第二次问答:LangChain真实发送的问题是第一次问题答案+第二次问题

- 第三次问答:LangChain真实发送的问题是第一次问题答案+第二次问题答案+第三次问题

- 第四次问答:LangChain真实发送的问题是第二次问题答案+第三次问题答案+第四次问题

为什么会有近3次问答内容的限制呢?因为初始化ConversationBufferWindowMemory时,设置了k=2。
1.6.ConversationSummaryBufferMemory
- ConversationSummaryBufferMemory:一种Memory的具体实现。提供了记录历史聊天记录,并对历史聊天记录进行归纳总结的能力。
- 代码路径/libs/langchain/langchain/memory/summary_buffer.py,详细源码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| class ConversationSummaryBufferMemory(BaseChatMemory, SummarizerMixin):
"""Buffer with summarizer for storing conversation memory."""
max_token_limit: int = 2000
moving_summary_buffer: str = ""
memory_key: str = "history"
@property
def buffer(self) -> List[BaseMessage]:
return self.chat_memory.messages
@property
def memory_variables(self) -> List[str]:
"""Will always return list of memory variables.
:meta private:
"""
return [self.memory_key]
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
"""Return history buffer."""
buffer = self.buffer
if self.moving_summary_buffer != "":
first_messages: List[BaseMessage] = [
self.summary_message_cls(content=self.moving_summary_buffer)
]
buffer = first_messages + buffer
if self.return_messages:
final_buffer: Any = buffer
else:
final_buffer = get_buffer_string(
buffer, human_prefix=self.human_prefix, ai_prefix=self.ai_prefix
)
return {self.memory_key: final_buffer}
@root_validator()
def validate_prompt_input_variables(cls, values: Dict) -> Dict:
"""Validate that prompt input variables are consistent."""
prompt_variables = values["prompt"].input_variables
expected_keys = {"summary", "new_lines"}
if expected_keys != set(prompt_variables):
raise ValueError(
"Got unexpected prompt input variables. The prompt expects "
f"{prompt_variables}, but it should have {expected_keys}."
)
return values
def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, str]) -> None:
"""Save context from this conversation to buffer."""
super().save_context(inputs, outputs)
self.prune()
def prune(self) -> None:
"""Prune buffer if it exceeds max token limit"""
buffer = self.chat_memory.messages
curr_buffer_length = self.llm.get_num_tokens_from_messages(buffer)
if curr_buffer_length > self.max_token_limit:
pruned_memory = []
while curr_buffer_length > self.max_token_limit:
pruned_memory.append(buffer.pop(0))
curr_buffer_length = self.llm.get_num_tokens_from_messages(buffer)
self.moving_summary_buffer = self.predict_new_summary(
pruned_memory, self.moving_summary_buffer
)
def clear(self) -> None:
"""Clear memory contents."""
super().clear()
self.moving_summary_buffer = ""
|
我们看一个例子:

- 从这段代码的输出,可以看到LangChain对历史问题和答案进行了概括总结:
1
2
3
4
| {'history': [
SystemMessage(content='\nThe human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good because it will help humans reach their full potential. The human then asks what LLM is, to which the AI responds that it stands for Large Language Model, and provides a list of LLM models, including GPT-3, GPT-J-6B, CLIP, BERT, and T5.',
additional_kwargs={})
]}
|
2.小结
本文阐述了Memory模块的内部实现:
- ChatMessageHistory:提供记录历史聊天记录的对象
- BaseChatMemory:维护1个ChatMessageHistory对象,并对外提供CRUD历史聊天记录的接口
- ConversationBufferMemory:BaseChatMemory的1种子类,对外提供最终的CRUD历史聊天记录的接口
- ConversationBufferWindowMemory:在ConversationBufferMemory的基础上,提供了滑动窗口能力
- ConversationSummaryBufferMemory:在ConversationBufferMemory的基础上,提供了历史聊天记录的摘要能力
后续文章,我们继续解读LangChain的核心模块,感谢阅读。