在《AI拾遗》这个专栏中,我们建立了从N-Gram到词嵌入再到神经概率语言模型,从Seq2Seq到注意力机制的知识脉络。
这条脉络本质就是NLP发展的路线图,有了这些知识储备,我们终于可以来理解论文**《Attention Is All You Need》**中大名鼎鼎的**Transformer架构**了!
1.问题
在《【chatGPT】学习笔记13-Transformer之注意力机制,大语言模型的关键部件4》中,笔者为编码器-解码器架构增加了注意力机制,进而实现了增强版的Seq2Seq模型,模型能力的确有所增强,但并不是彻底解决了长距离依赖问题和信息压缩问题。
在《Attention Is All You Need》的第一章阐述了这个观点:
- howerver, remains(第二段最后一句):历史上很多论文和技术都在增强编码器-解码器架构,注意力机制也成为序列建模必备的技术,但长距离依赖问题依然存在。
- parallelization(第三段):这里提到了并行化,这是前面没有提到的问题——RNN网络决定了Seq2Seq只能一个词一个词的处理。

2.Transformer逐步拆解
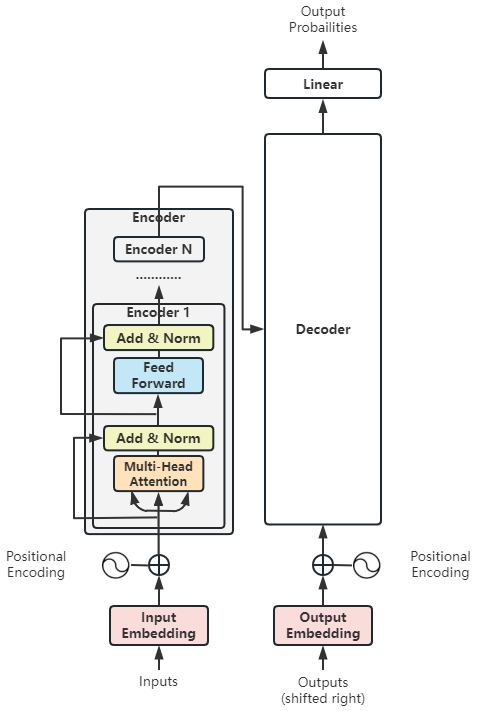
这是论文中第三段绘制的Transformer整体架构,我们将对它进行拆解:
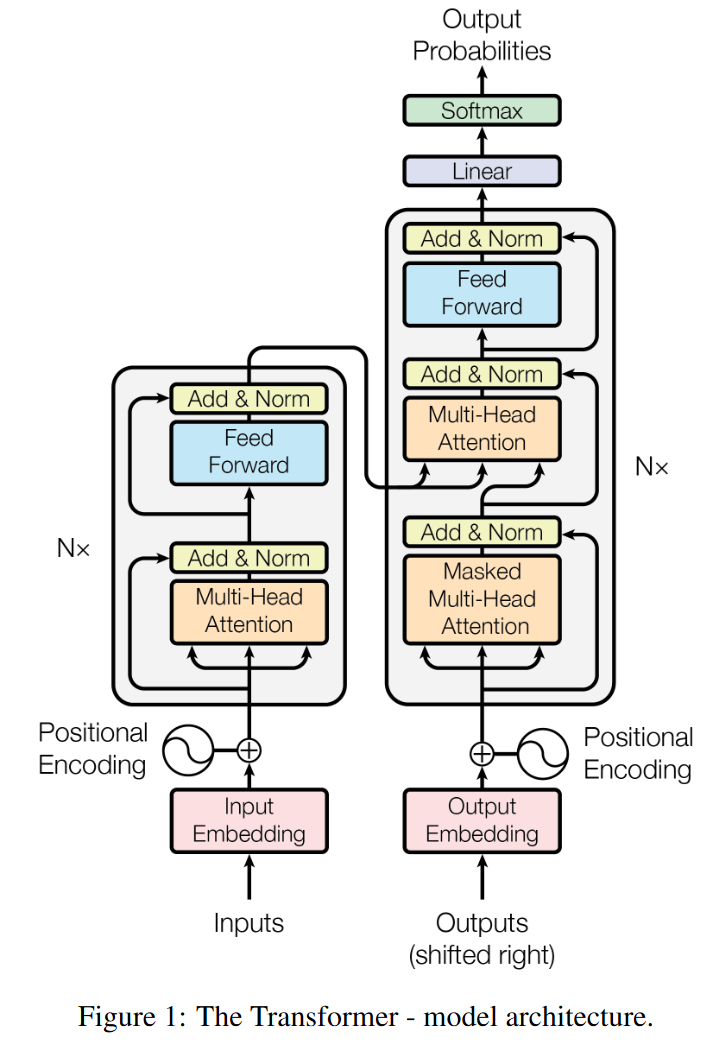
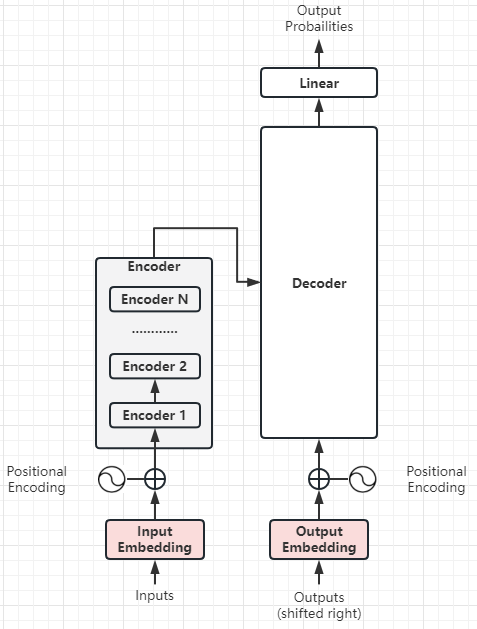
(1)整体:Transformer
将上图抽象化,我们可以看到:
- Transformer依然可以遵循Encoder-Decoder架构
- Decoder的输出交给一个线性层,将解码器的输出转换为目标词汇表大小的概率分布——这属于常规操作,与Transformer核心思想关系不大。
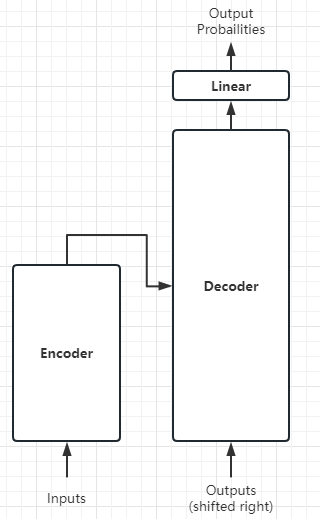
代码实现如下:
- 1:对应上图将Inputs输入给Encoder。
- 2:对应上图将Outputs+Encoder的输出,传入给Decoder。
- 3:对应上图将Decoder的输出,传入给线性层。
PS:这里的corpus是一个封装了Inputs和Outputs的工具类,代码如下(比较简单,不赘述):

(2)局部1:正弦位置编码表
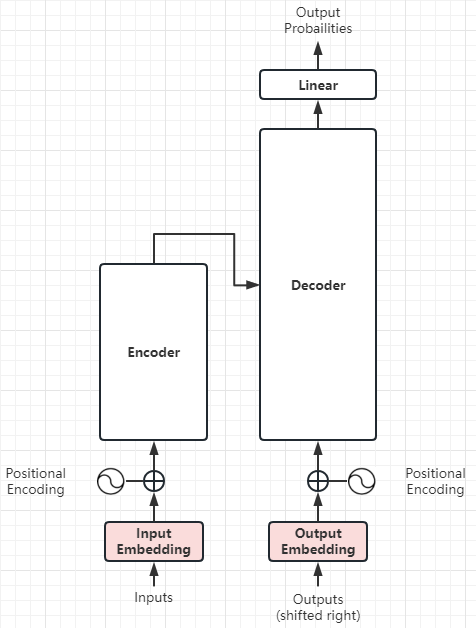
首先,我们来细化Inputs和Encoder之间的流程:
- STEP1.对Inputs实施词嵌入,得到词向量。
- STEP2.在词向量和Encoder之间增加了位置编码表(也是一个向量),这个位置编码表体现了词和词序的关系。
- 由于Transformer取消了RNN,也就不再逐个词串行处理,所以必须建立词和词序的关系。
- STEP3.将STEP2的位置表码表向量和词向量相加,输入给Encoder。
Outputs和Decoder之间的流程和上述流程一样。
那么位置编码表如何计算呢?论文3.5章节详细阐述如下:
- d:词向量的维度。
- pos:单词在句子中的位置。
- i:词向量的维度的奇数维。
- PE:指定位置的单词,在词向量的某一个维度上的数值。
- 通俗地理解,d个PE值构成了指定单词在整个句子中的位置向量。

我们不必纠结于论文中这两个公式的证明,笔者绘制一个例子,可视化地理解正弦位置编码表的作用:
- 假设:输入序列为”想去新疆“四个字,词向量的维度为4维,即d=4。
- STEP1:通过正弦位置编码公式,想字的位置0,求得位置0的位置向量[0, 1, 0, 1]。
- STEP2:通过正弦位置编码公式,去字的位置1,求得位置1的位置向量[0.84, 0.54, 0.01, 1.0]。
- STEP3:通过正弦位置编码公式,新字的位置2,求得位置2的位置向量[0.91, -0.42, 0.02, 1.0]。
- STEP4:通过正弦位置编码公式,疆字的位置3,求得位置3的位置向量[0.14, -0.99, 0.03, 1.0]。

代码实现如下:

(3)局部2:编码器堆栈
我们再来细化编码器:
- 编码器本质上由N个编码器串联而成的编码器堆栈。
- 论文中,N=6。
- 论文原文:

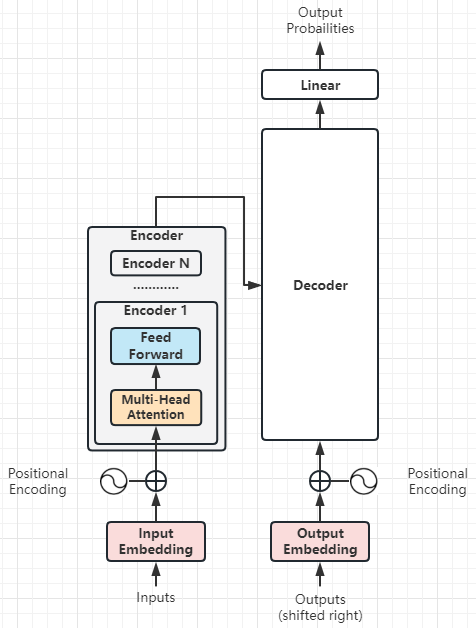
(4)局部3:编码器
我们再进一步细化编码器Encoder:
- 编码器Encoder由多头注意力和前向传播网络组成。
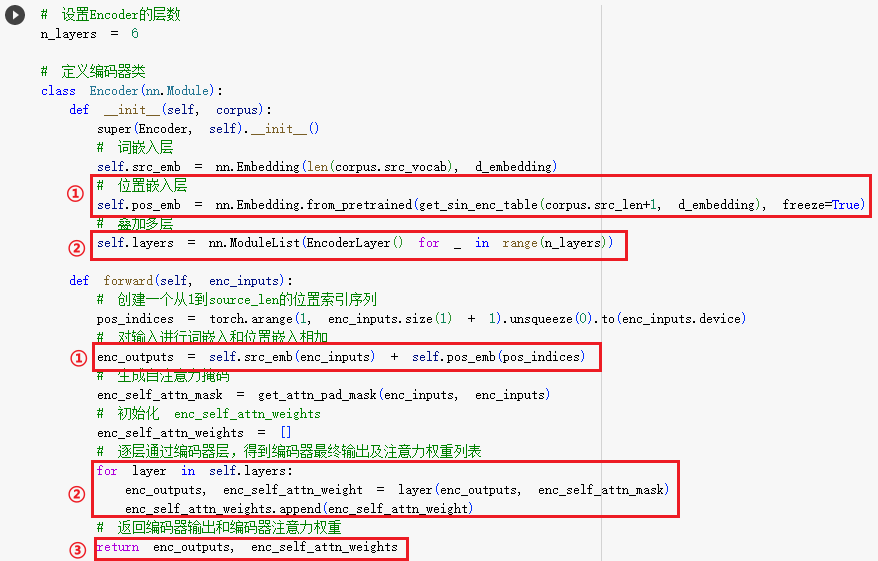
编码器堆栈的代码实现如下:
- ①:这就是调用正弦位置编码表,创建的位置编码层,再将词向量和位置编码向量相加。
- ②:这就是将多个编码器叠加成编码器堆栈,每个编码器的输入是上个编码器的输出和上个编码器输出的注意力权重。
- ③:这就是表示编码器堆栈输出的编码器输出、编码器输出的注意力权重。
编码器的代码实现如下:
- ①:就是多头注意力层,第一个编码器的多头注意力层的输入是词嵌入+位置编码向量之和以及自注意力掩码,后续编码器的多头注意力层的输入是上一个编码器的输出和自注意力掩码。
- ②:就是前向传播网络,它的输入是多头注意力层的输出。

这里又埋下了几个问题:
- 多头注意力层如何实现?
- 前向传播网络如何实现?
- 自注意力位置掩码如何实现?
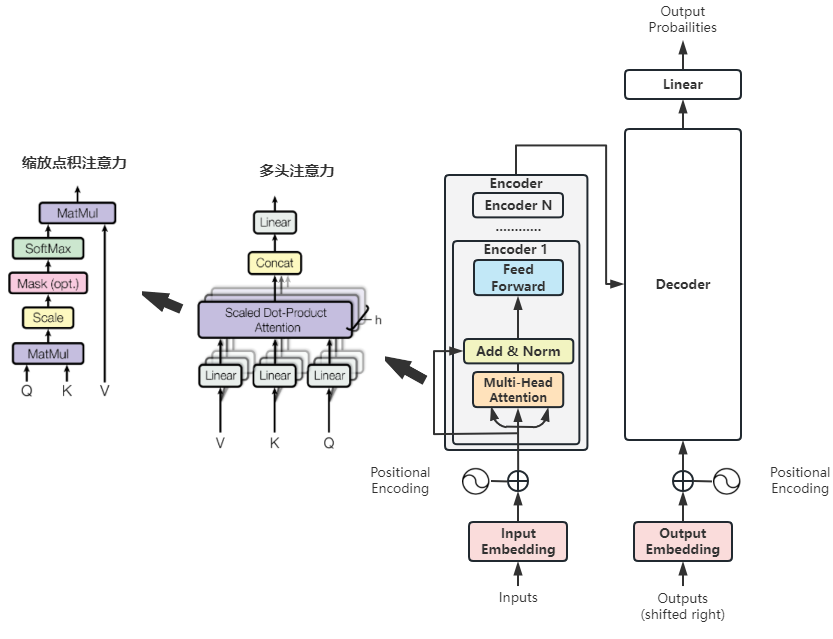
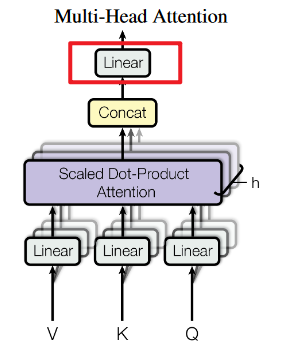
(5)局部4:多头注意力
我们再来细化多头注意力:
- 不赘述:关于点积注意力、缩放点积注意力、编码器-解码器注意力、QKV、自注意力、多头注意力,本文就不再赘述了。如果理解不太清晰,可以回看《【chatGPT】学习笔记13-Transformer之注意力机制,大语言模型的关键部件4》。
- 多头注意力的结构:多头注意力的输入是词向量与位置编码向量之和,每一个注意力头都是对多头注意力的输入进行矩阵乘法得到QKV,再输入给缩放点积注意力组件,这个组件输出的是注意力权重。最后,将每个注意力头输出的注意力权重求和,输入给一个线性层。
- 缩放点积注意力的结构:就是典型的缩放点积注意力的计算公式,即:Q、K求点积=>缩放=>注意力掩码=>Softmax=>和V点积。
- 细节:这里增加了Add & Norm,就是深度学习里面的残差连接、层归一化,为了解决梯度爆炸问题,这不是Transformer特有的新知识。
论文原文:
- 缩放点积注意力计算公式:

- 多头注意力:

缩放点积注意力的代码实现如下:

多头注意力的代码实现如下:

(6)局部5:前向传播网络
我们再来细化前向神经网络:
- 前向神经网络的全称是Position-wise Feed-Forward Network,即基于位置的前馈神经网络。
- two linear transformations with a ReLU activation:首先使用第一个线性层做升维,接着使用ReLU激活函数,再使用第二个线性层做降维。
这个基于位置的前馈神经网络到底有啥用呢?
- 就是论文中,多头注意力结构中的最后一步Linear!
论文原文:

代码实现如下:

(7)局部6:填充位置掩码
我们再来细化填充位置掩码:
- 填充位置掩码用在词嵌入之后,编码器输入之前。
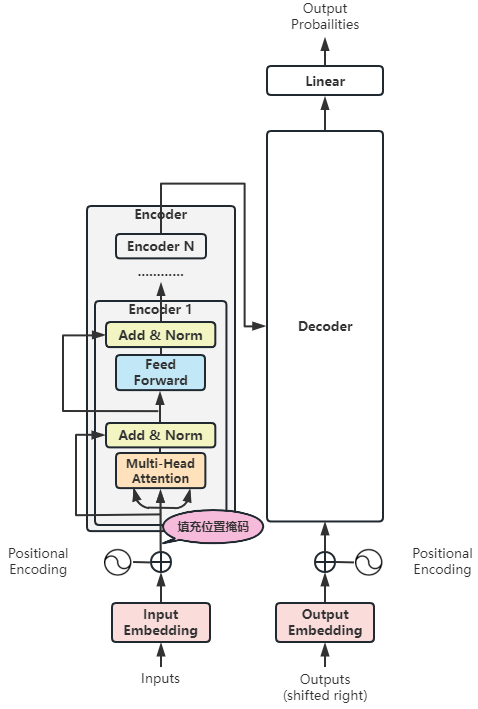
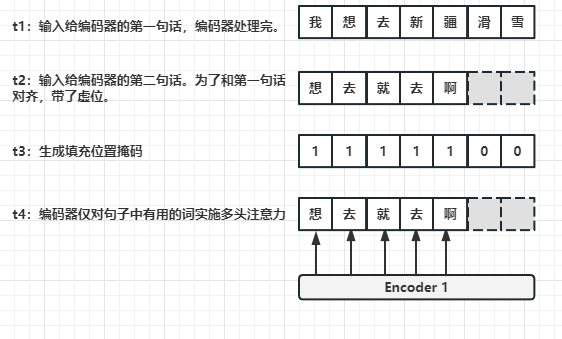
- 填充位置掩码有什么作用呢?
- t1时刻:给编码器输入了一句话——“我想去新疆滑雪”。
- t2时刻:给编码器输入第二句话——“想去就去啊”。为了和上一句话保持长度统一,我们就会在在第二句话末尾增加两个占位符。
- t3时刻:生成填充位置掩码[1, 1, 1, 1, 1, 0, 0]。
- t4时刻:编码器会将第二句话和填充位置掩码求与,这样编码器实施多头注意力的时候,就不会注意毫无意义的两个占位符。
代码实现如下:

至此,我们就把Transformer架构中编码器部分细化完成了,我们继续细化解码器部分:
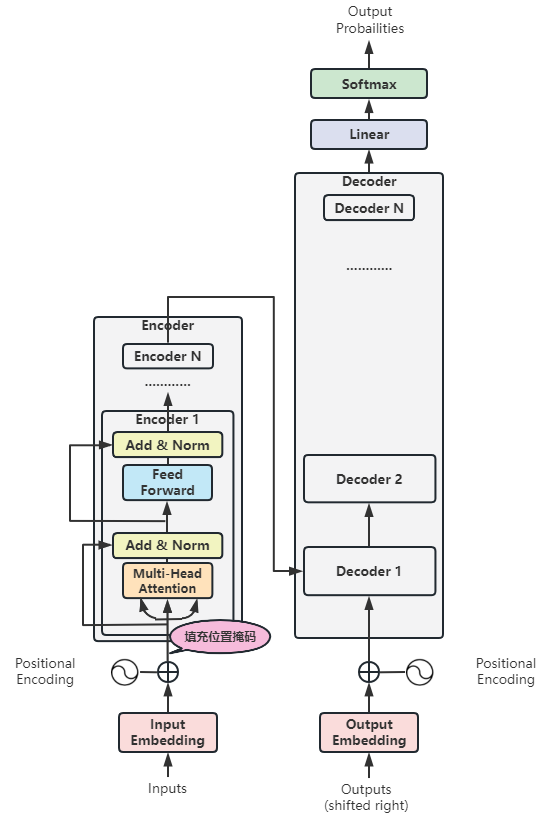
(8)局部7:解码器堆栈
解码器堆栈的思想到实现,和编码器堆栈完全一样,这里不再赘述,直接上图和代码:
(9)局部8:解码器
解码器的思想到实现,和编码器堆栈大致一样,这里不再赘述,直接上图和代码:
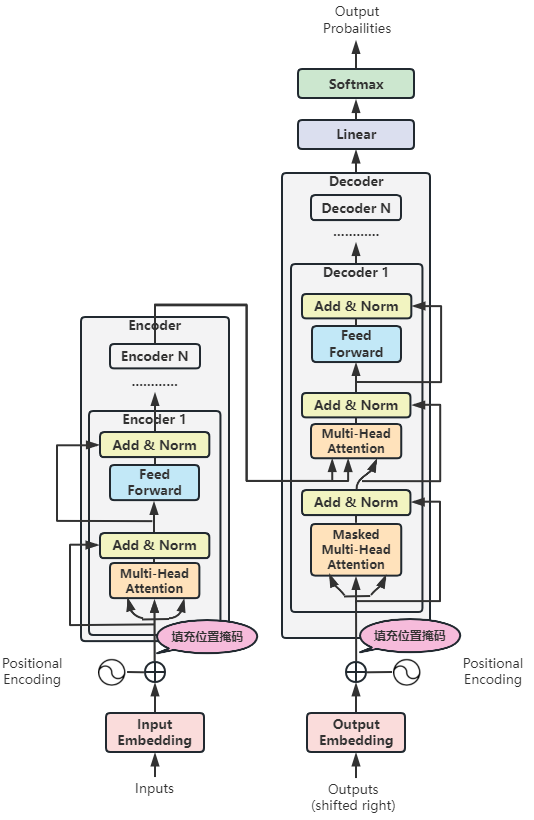
解码器堆栈代码如下:

解码器代码如下:

(10)局部9:后续位置掩码
在解码器中,还有最后一个遗留问题——后续位置掩码。
后续位置掩码只是因为解码器实施多头注意力的时候,是不能注意到未来的,也就是它还没有预测的后续词,所以要屏蔽掉。
后续位置掩码和填充位置掩码的思想是一致的,不赘述。
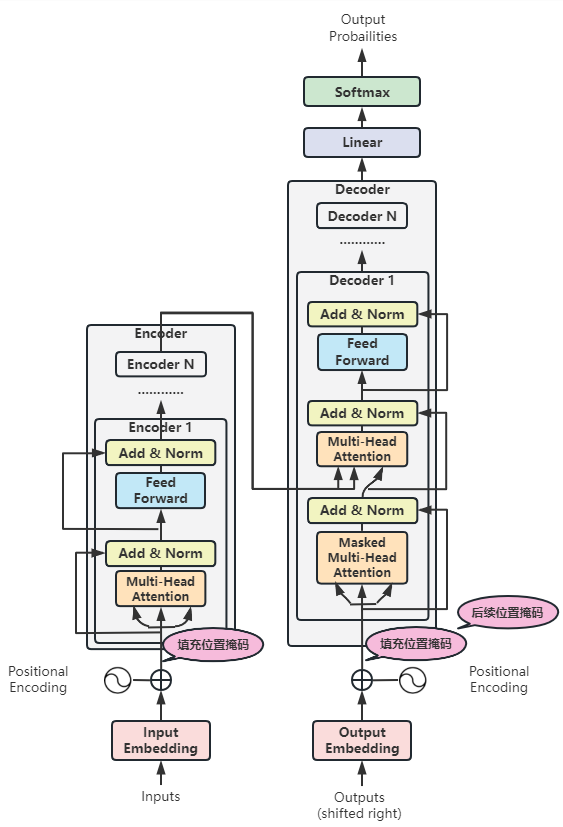
后续位置掩码的代码实现:

(11)模型训练
至此,我们已经完整地实现了Transformer架构,我们开始对其进行训练:
- 数据集如下:

- 模型训练:

(12)模型测试
- 测试用例采用贪婪编码,比较简单,具体代码如下:

3.小结
笔者在今年2月份第一次阅读论文《Attention Is All You Need》,读了好几遍,不得要领,只觉得非常抽象。
随着在网上阅读各类资料、逐步摸索复现论文中Transformer架构的源码,逐渐理解这篇论文中所说的——Attention Is All You Need的含义。
本以为理解了论文含义,提笔准备写出这篇文章时,又卡了壳——因为理解了,又很难表达出来Transformer的精妙原理!
此时,笔者才真正领悟之前听过一位大神所说的:”LLM涉及的每一篇经典论文,不仅值得反复阅读,甚至应该背诵下来。“的含义。
这篇文章写完,我们下一步就可以实现并训练我们平民版的ChatGPT了,且听下回分解了。