最近有小伙伴提意见,希望我的专栏能用小短篇的形式,将大模型相关知识通俗阐述一下。
特此请ChatGPT协助我一起将近几个月阅读的资料以笔记体记录下来,与大家分享。
1.ChatGPT不是什么?
1.1.古早的聊天机器人
一些古早的聊天机器人、客服机器人,有采用如下方式进行实现:
- 利用分词组件对用户输入的问题进行分词,获得问题中的关键词。
- 将关键词,在数据库、在互联网的上中进行搜索。
- 其中,数据库中预置了很多问题和答案。
- 将得到的答案过滤清洗、随机返回其中1个答案。
1.2.现代的聊天机器人
ChatGPT及其更早的NLP领域技术,早已不是从数据库、互联网生成答案的。
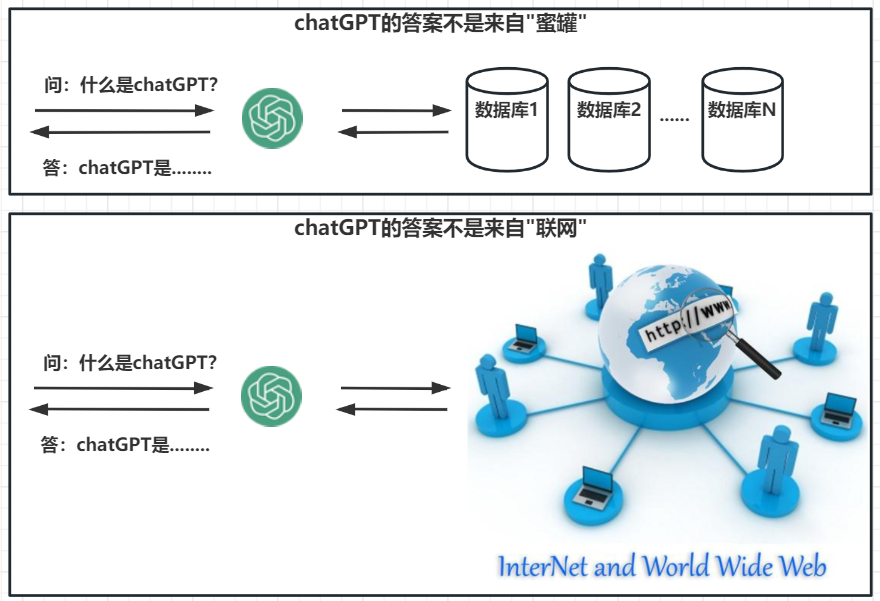
ChatGPT官方也明确表达了"ChatGPT is not connected to the internet”。

2.ChatGPT是什么?
2.1.大模型的生成原理(ChatGPT版)
- 请ChatGPT解释一下大模型的生成原理,如下:

2.2.大模型的生成原理(通俗版)
我们再来通俗理解一下:
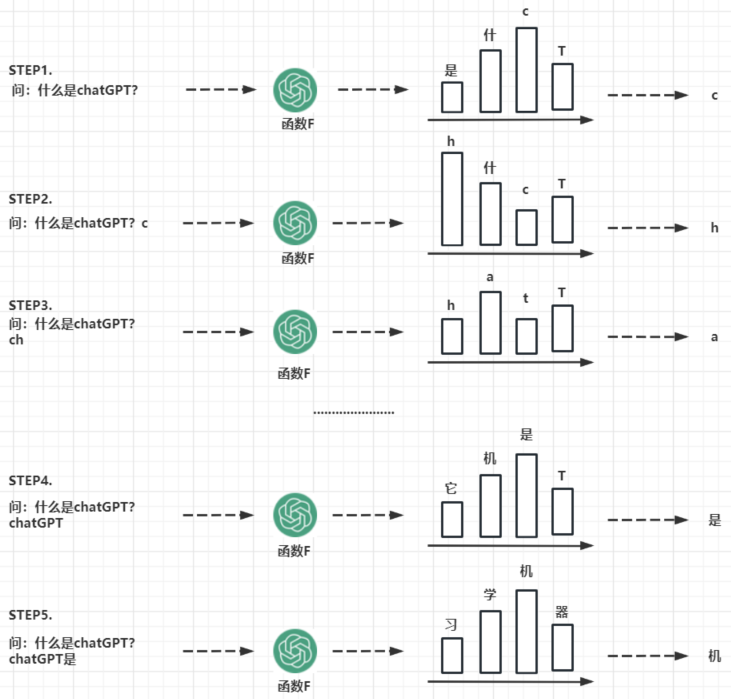
- STEP1:问一个问题"什么是ChatGPT?",可以将ChatGPT看成1个函数F,这个函数会输出即将回答的答案中第一个字(词)的概率。比如:根据问题,答案第一个字是"c"的概率是最大,最终就认为答案的第1个字是"c”。

- STEP2:将STEP1的输出追加到问题上,问题就变成了"什么是ChatGPT?c”,继续输入给函数F,得到新的概率,最终认为答案的第2个字是"h”。

- STEP3、STEP4、STEP5:不断重复STEP1、STEP2的动作,就会得到完整的答案,如下图:
3.未来的研究方向?
大模型未来的热点研究方向很多很多:提示词工程、神经网络编辑、机器遗忘、自适应计算和自适应模型、跨模态学习、模型压缩和加速、集成多任务和元学习、强化学习和自监督学习等等。
笔者认为”提示词工程、神经网络编辑、机器遗忘“最为有趣,因为它们和脑科学有点相近之处,都是在"激发神经网络”、“修改神经网络”、“抹除神经网络”。
3.1.提示词工程
- Prompt Engineering,吴恩达老师的课程让这个热点更热。提示词工程的本质可以认为:大模型好像一个博学的老人家(世界知识几乎都知道),只是记性不太好。你需要用一些特殊的提示词唤醒他的记忆(俗称会念咒),他就能很好地回答你的问题。

3.2.神经网络编辑
Neural Editing,随着模型越来越大,训练好一个模型的成本极高,重新训练几乎不可能,因此需要有一种改进神经网络生成结果的技术,可以通过对模型的生成结果进行编辑,来获得更准确、更自然的结果。该技术通常涉及到在生成结果中插入或删除一些元素,或者重新排列生成结果的顺序,以获得更好的输出结果。
3.3.机器遗忘
Machine Unlearning,机器遗忘是一种让机器学会忘记以前的知识的技术。说白了,就是"你知道了不该知道的事情”。这项技术可以应用于安全隐私、AI伦理领域。

3.4.其它方向
以下来自于ChatGPT的解释,供参考:
自适应计算和自适应模型:在大模型上进行计算是一项巨大的挑战,因为它们需要大量的计算资源和内存。因此,未来的研究方向将包括自适应计算和自适应模型,旨在优化大模型的计算效率和资源利用率。
跨模态学习:指使用多种类型的数据来训练一个模型。例如,将文本、图像和语音数据结合起来训练一个模型,以获得更准确、更全面的结果。未来的研究方向将探索如何在大模型上实现跨模态学习,以进一步提高模型的准确性和泛化能力。
模型压缩和加速:由于大模型需要大量的计算资源和内存,因此未来的研究方向将包括模型压缩和加速,以减少模型的大小和计算负载,从而使模型更加可扩展和可用。
集成多任务和元学习:指在一个模型中同时处理多个任务,例如,在自然语言处理中同时进行命名实体识别和情感分析。元学习是指在训练过程中学习如何学习的过程。未来的研究方向将集中在如何在大模型上实现多任务学习和元学习,以提高模型的泛化能力和效率。
强化学习和自监督学习:强化学习是指使用奖励信号来训练一个模型,在自我监督学习中,模型从未标记的数据中学习。未来的研究方向将集中在如何在大型模型上实现强化学习和自我监督学习,以提高模型的效率和准确性。
说明:本文部分内容由ChatGPT生成。