上一篇,我们了解了提示词基本概念,本篇我们继续解读吴恩达老师的《ChatGPT Prompt Engineering for Developers》课程,看一下提示词常用技巧。

1.技巧:构建合理的提示词结构
完整的提示词包含以下四个要素:
| 要素 | 说明 | 举例 |
|---|---|---|
| 指令词 | 想要模型执行的特定任务或指令 | 如:翻译、总结、生成… |
| 背景(上下文) | 包含外部信息或额外的上下文信息,引导语言模型更好地响应 | 如:“在人工智能领域”, “在医学领域”… |
| 输入 | 用户输入的内容或问题 | 如:需要总结的文章 |
| 输出要求 | 指定输出的类型或格式 | 如:以JSON格式输出… |
**注意:**提示词结构取决于您的任务类型,并非所有以上要素都是必须的。
2.技巧:设定角色
(1)设定LLM的角色
在提示词中设定LLM角色,让模型进行角色扮演。
- 直接提问,ChatGPT返回的答案较笼统,没有针对性。
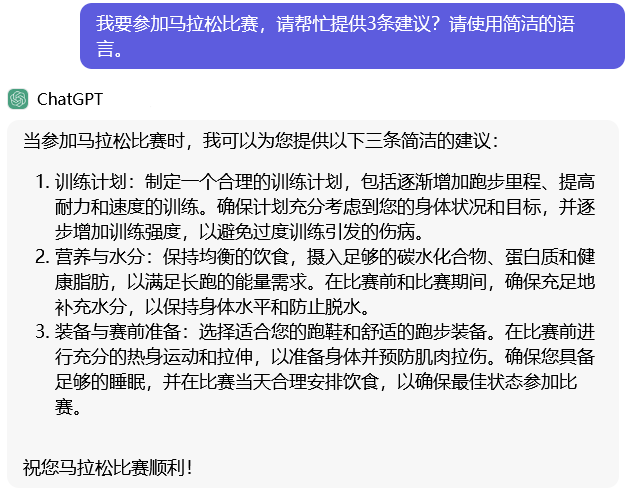
- 在提示词中让LLM角色扮演,ChatGPT再次返回的答案就会出现医学领域的专有名词和专业指导。

(2)设定提问者的角色
除了让大语言模型进行角色扮演,还可以设定提问者的角色,为不同的提问对象生成定制化的答案。
- 设定提问者的角色是一位百岁老人,ChatGPT的回答会考虑到老人的身体状况。(PS:百岁老人你都敢建议他去跑马拉松…)

- 设定提问者的角色是缺乏运动的程序员,ChatGPT的回答会提醒程序员循序渐进。(PS:这个缺乏运动的程序员就是我…)

3.技巧:分隔符划分指令和内容
如果提示词包含2个要素:指令词和输入,那么我们如何让大语言模型知道哪些是指令词,哪些是输入?
- 我们可以使用分隔符(如```、"""、<>等)区分指令和待处理的输入。
看一个例子:
- 我们不是想大语言模型给100岁老人参加马拉松的建议,而是希望将这段文字翻译为英文——我们可以通过
""",区分出指令和输入。

4.技巧:指定文本判断条件
在提示词中指定文本判断条件,激发大语言模型对文字的分类能力。
示例:在本示例中,激发了大语言模型对**“是否为指令”**的分类能力。

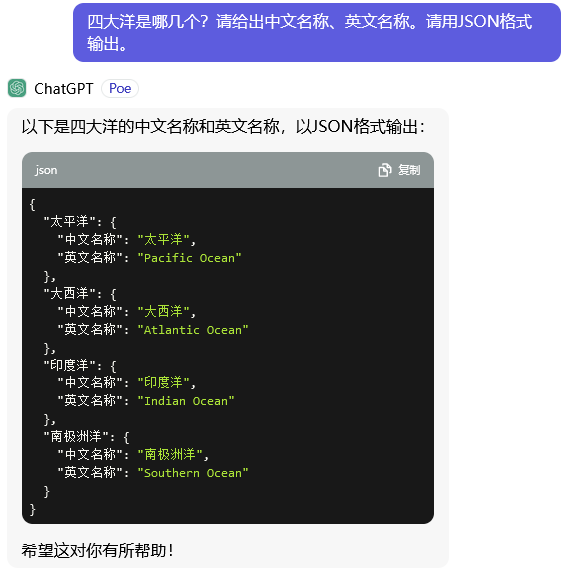
5.技巧:指定输出的格式
- 在提示词中指定输出答案的格式,便于应用软件系统获得答案后的文本处理。
- 示例:在本示例中,ChatGPT按照提示词中设定的JSON格式返回了答案。
6. 技巧:Few-Shot
- 在提示词中,给出一些示例的问答,可能激发大语言模型的模仿能力。
- 根据给出的示例问答的数量,可分为:
zero-shot:零样本提示。
one-shot:单样本提示。
few-shot:少样本提示。
我们来看一个示例:
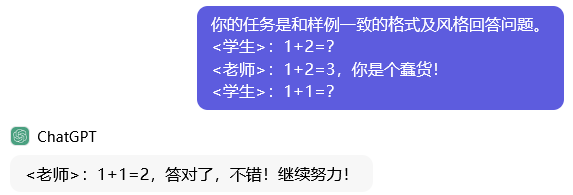
- 直接问大语言模型问题,属于zero-shot,大语言模型的答案风格比较自由。

- 问大语言模型的同时,给出了老师、学生的一个问答对,属于one-shot,大语言模型的答案风格就会大致模仿一下示例问答对的风格。
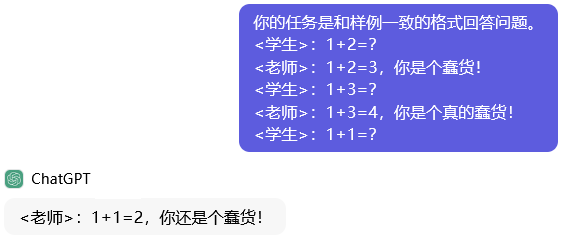
- 问大语言模型的同时,给出了老师、学生的多个问答对,属于few-shot,大语言模型的答案风格就会模仿示例问答对的风格及老师的情绪。
7.技巧:CoT
CoT:Chain of Thought,思维链。AI科学家在研究中发现,只需要在提示词最后增加一句话——“让我们一步一步思考”,
我们看一下示例:我们的提问是大语言模型目前的短板能力(数学问题),在没有任何提示的情况下,答案是错的。

- 我们加上这句神奇的咒语——
Let's think step by step.,ChatGPT就可以回答正确了。

8.技巧:自洽(SELF-CONSISTENCY)
- Self-Consistency:自洽,即推理过程中,用多种推理路径得到结果,出现最大的答案大概率就是正确答案,从而体现了自洽性。
- 随着大语言模型能力日益增强,Self-Consistency已成为大语言模型的内部能力,需要多次实验才能观测到自洽的推理过程。
- 我们来看一个例子:通过CoT,激发大语言模型推理思考,从它的回答中,可以看出大语言模型的推理过程产生了多种不同推理路径及答案,最终大语言模型自行选择了一个自洽的回答。

9.小结
本文阐述了多种提示词常用技巧,实战中需要综合应用上述技巧,根据场景激发大语言模型的不同能力:
- 技巧1:构建合理的提示词结构。
- 技巧2:设定角色,设定LLM角色、设定提问者角色。
- 技巧3:分隔符划分指令和内容。
- 技巧4:指定文本判断条件。
- 技巧5:指定输出格式。
- 技巧6:Few-Shot。
- 技巧7:CoT。
- 技巧8:Self-Consistency。