2023年是基础大模型的爆发元年,专家预测2024年将是AI应用的爆发元年。
因此,本专栏希望通过一系列文章,和大家探讨AI应用的规划、落地、实践等问题:
如何在千行百业寻找AI应用的落地点?如何用AI为客户带来真实的价值?
如何开发高质量AI应用?如何评估和控制AI应用的开发成本?
RAG是目前AI应用落地的主要技术领域,本文首先来探讨RAG相关的产品实践。
1.开发AI应用前,我们应该考虑什么?
(1)我们真的需要AI应用吗?
相信大家有一种感觉:AI很强大,但问及AI解决什么具体的行业问题?又无从回答。
这是一个产品规划问题:
- 行业痛点:我的行业领域有什么Gap点?
- 业务设计:AI能解决这些Gap点吗?
- 价值呈现:这些问题解决后能给客户带来什么价值?
我们不能叶公好龙式地迷失在AI浪潮中,还是要落脚于解决客户痛点、呈现产品价值。
以Khan Academy在AI赋能教育的实践为例:
Khan Academy是一家具备全球影响力的在线教育平台,愿景是为提供普惠教育(为无法享受基础教育的学生提供覆盖学科广泛、内容专业的在线课程。
行业痛点:Khan Academy的普惠教育理想,意味着既要高教学质量、千人千面,又要控制教学成本。
业务设计:
- 怎么学:通过AI对不同学生的画像,自动化(成本)、专业化(高质量)、针对性(千人千面)地给出学习地图。
- 学什么:通过AI自主挖掘发现学习资源,自动化(成本)、针对性(千人千面)地为学生推荐学习资源。
- 监督引导:通过AI,自动化(成本)、有耐心(高质量)地监督与调整学生进度及学习习惯。
价值呈现:
- 自主学习、个性化学习是普惠教育的基石。
- AI从教学质量和成本上使得自主学习、个性化学习成为了可能。
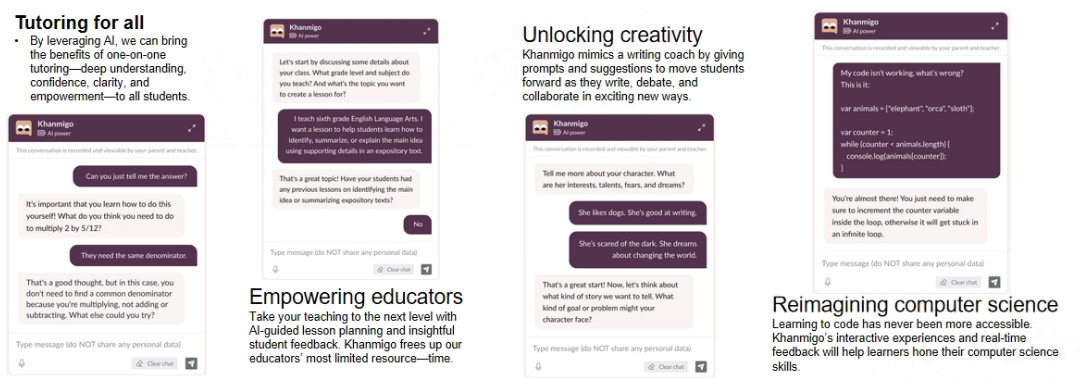
(2)解决问题的手段只有锤子吗?
AI智能问答是一把锤子(也是目前国内AI应用的主要形态),但它只是AI能力的很小一部分。
为了更好地选择合适的AI能力解决客户问题,我们需要理解AI能力的全集。
AI能力可以分为基础能力和综合能力:
- 基础能力:AI的听说读写能力,这些能力可以让AI将"文字”、“语音”、“图像及视频"进行相互转换。
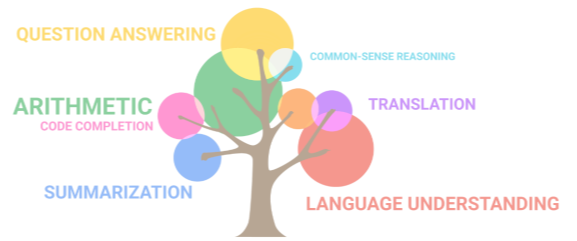
- 综合能力:综合能力依托于AI基础能力,进而解决客户的业务问题。
- RAG能力:AI可以通过外挂形式,进行垂域知识问答。
- ReAct能力:可以发挥AI具备的一定的推理能力,分解任务,自动执行。

面向不同类型的客户问题,我们选择的AI能力不同:
- 检索类问题适合采用RAG。
- 如:了解工作流程、学习专业知识等检索类客户问题,适合使用AI的RAG综合能力。
- 任务执行类问题适合采用ReAct。
- 如:挖掘海量互联网学习资源、根据学生学习情况监督调整学习计划等任务执行类问题,适合采用ReAct综合能力。
2.如何构建RAG数据集?
在确定采用RAG技术解决客户问题后,构建高质量的RAG数据集是RAG成功的关键(否则就是"垃圾进,垃圾出"的结果)。
我们接下来讨论如何构建高质量RAG数据集。
2.1.问题分类
在制作数据集前,要理清垂域中的垂域用户问题和垂域知识的特点。
垂域用户问题有如下特点:
高频问题易识别: 常见问题和重复性问题出现的频率较高,垂域专家清楚高频问题是什么。
针对性强&辨识度高:通常针对特定的知识进行提问,问题描述包含垂域专业术语,不闲聊。
兼具广度和深度:可能是问结构纲领级的问题,也可能是针对某个具体细节的问题。
垂域知识有以下特点:
- 独特性:垂域知识有其独特的知识体系和术语,需要具备一定的专业背景和知识储备才能理解和应用。
- 结构明确:垂域知识通常有明确的结构和层次,各层知识间不存在重复和二义性。垂域知识更新很快,但知识结构变化相对小。
基于以上特点,可以将垂域用户向AI提问的问题类型分为2类:
- 高频问题:适合采用FAQ问答技术,一则可使答案准确可控,二则减少AI的资源消耗。
- 知识问答:适合采用文档问答技术,一则文档所覆盖的垂域知识深度与广度兼备,二则构建成本相对较低。
2.2.FAQ问答数据集构建
(1)关注构建成本
FAQ问答数据数据集构建时,可能存在一种误区:问题不够加问题?
- 问题不是不够,而是AI的理解能力有限,无法理解同一个问题五花八门的表达形式。
- 问题不够加问题,本质就是穷举问题表达形式,但自然语言的表达形式穷举成本极高甚至不可穷举,因此会导致数据集构建成本不可承受。
如果上述方法行不通,则说明我们需要:用有限的问答对覆盖多样的问题表达形式,进而才能控制FAQ数据集的构建成本。
如下是我们的工程实践:
从知识的覆盖度上构建问答对,而不是从问题的表达多样性上构建问答对——这样问答对的数量就是有限的。
覆盖多样的问题表达形式,可以采用关键词、扩展问等技巧。
这个过程必须投入业务专家,根据上述两点工程实践进行把关和输出,业务专家需要保证。
- 每个问题要保证语义唯一性。
- 所有问题构成的语义集合要保证业务覆盖性。
(2)关注关键词提取
关于前文提到的关键词技巧,也存在一个误区:直接将问题中的主谓宾作为关键词。
- 这里举个例子:
Java是"如何提高Java的调试与定位能力?“这个问题的关键词吗? - 显然,从自然语言角度
Java是关键词,但从业务角度Java不是关键词。- 因为用户对Java领域的常见问题,都会带有Java这个单词。
- 如果将Java作为本问题的关键词,那么所有的垂域问题都会被AI认为与本问题有关。
我们的实践经验是:
每个关键词必须具备独特性。
- 上述例子中,
Java没有独特性,失去了特征,而调试与定位能力作为这个问题的关键词更为合适,因其具有独特性。
- 上述例子中,
关键词集合必须具备丰富性。
- 从业务角度,“调试与定位能力”,也有"调试定位”、“调试与定位"这种惯用语,因此关键词集合可以丰富为[“调试与定位能力”, “调试与定位”, “调试定位”]。
2.3.文档问答数据集构建
(1)关注文档质量
文档问答是AI对垂域文档进行学习理解(向量化)。这个过程类似老师(AI工程师)教小孩(AI)学习一本教材(垂域文档)。
需要充分理解AI的特点(因材施教),设计出AI更容易理解垂域文档(好教材),是构建文档问答数据集的关键技术。
构建垂域文档,有如下实践:
- 知识组织形式会影响召回率:
- 通过实测和尝试,将垂域知识构建为树状结构,比较易于当前国内LLM理解和学习。
- 不要在垂域知识树的节点之间产生关联关系形成有向图,可以通过搬移树节点的形式用线性的形式表达知识节点的关系。
每个知识块节点的粒度适中。
- 知识块不宜过大:将整个垂域文档设计为一个知识块,会导致问啥问题都返回这个知识块。
- 知识块不宜过小:将垂域文档设计为一句话一个知识块,会导致知识点太碎,知识点之间存在复杂的逻辑关联,远超出现有LLM的推理能力。
每个知识块节点内容避免重复。
每个知识块节点内容避免矛盾。
2.4.AI辅助构建数据集
前述FAQ数据集构建、文档问答数据集构建的过程,都可以采用AI、自动化工具等方式辅助构建。
我们会在后续文章中分享AI辅助构建数据集的工程方法与实践。
但,无论采用怎样的数据集构建过程,还是要关注数据集的内容本身,是否满足上述工程实践的要求和原则。
3.小结
构建RAG数据集,需要考虑一系列实践方法,建立标注规范,确保数据的质量和有效性。具体实践经验如下:
AI应用的规划与设计:
要用产品规划方法进行业务设计,落脚于解决客户痛点、呈现产品价值。
要选择合适的AI能力解决业务问题,可用的AI能力包括基础能力(听说读写)和综合能力(RAG、ReAct)。
构建RAG数据集方法:
- 问题分类:
- 高频问题:适合采用FAQ问答技术,一则可使答案准确可控,二则减少AI的资源消耗。
- 知识问答:适合采用文档问答技术,一则文档所覆盖的垂域知识深度与广度兼备,二则构建成本相对较低。
- FAQ问答数据集构建方法:
- 每个问题要保证语义唯一性。
- 所有问题构成的语义集合要保证业务覆盖性。
- 文档问答数据集构建方法:
- 知识组织形式会影响召回率:将垂域知识构建为树状结构,可以通过搬移树节点的形式用线性的形式表达知识节点的关系。
- 每个知识块节点的粒度适中:知识块不宜过大,也不宜过小。
- 每个知识块节点内容避免重复。
- 每个知识块节点内容避免矛盾。
- 可采用AI辅助构建数据集,但关键还是要关注数据集的内容本身符合上述工程实践的要求和原则。
- 问题分类: