Sora自2024年2月16日发布以来,持续霸屏、热度不断。从OpenAI官网上的演示视频看,效果也是相当震撼。
本篇基于OpenAI发布的技术报告对Sora的技术特点和原理进行解读。
1.Sora是什么?
Sora是一个文生视频的AI模型,可以根据文本信息生成真实且富有想象力的视频内容。主要特点:
- 以自然语言为输入(提示词),生成符合提示词描述的视频。
- 可生成1分钟内容连贯的视频,视频尺寸/分辨率可调整,目前只有Sora做到。其它模型只能生成4秒以内、256x256固定尺寸的视频。
- 真实世界的模拟器,不仅理解物理实体(如人、猫、狗、…),还懂得物理规律(如光照、碰撞、粒子、…)。
Sora出道即颠峰,让一众顶级文生视频模型望尘莫及。我们来直观感受下Sora生成的视频的震撼效果:
提示词如下:
Several giant wooly mammoths approach treading through a snowy meadow, their long wooly fur lightly blows in the wind as they walk, snow covered trees and dramatic snow capped mountains in the distance, mid afternoon light with wispy clouds and a sun high in the distance creates a warm glow, the low camera view is stunning capturing the large furry mammal with beautiful photography, depth of field.
视频如下:
2.Sora原理浅析和技术优势
OpenAI没有公开Sora的模型细节,本文后续分析依据OpenAI的"Technic Report"推测所得。
2.1.Sora是否采用了新的模型架构&技术?
答案是没有。
文生视频可能涉及的模型架构如下:
- RRN (循环神经网络)
- GAN (生成式对抗网络)
- 自回归Transformer
- Diffusion (扩散模型)
Sora采用的是:
- 自回归Transformer
- Diffusion (扩散模型)
2.2.Sora对现有模型架构&技术的创新
Sora架构是结合了Diffusion扩散模型和Transformer架构的创新设计。
(1)用Transformer架构,学习视频特征
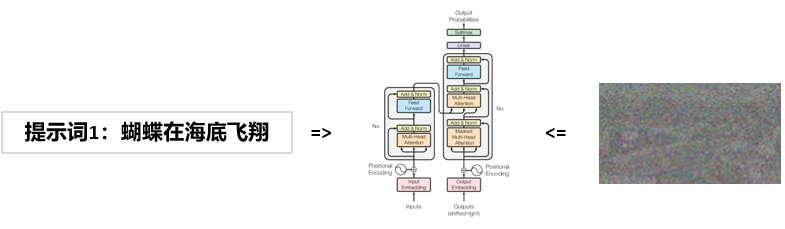
灵感来自于Tranformer架构在GPT中的成功应用,OpenAI把自然语言的特征表示方法引入到了视频处理中:
- 通过编码器,把视频的每一帧转换为有时序的向量,若干帧形成了向量矩阵,Sora称之为Turning visual data into patches。(大语言模型是把文字转换成一个个token,Sora则是把视频转换成一个个patch。)
- 与大语言模型中token线性序列不同,由patch组成的高维向量矩阵包含了时序、分辨率、高宽比等丰富信息。
- 和大语言模型一样(文本信息压缩网络),Sora模型本质是一个视频压缩网络Video compression network,使用该视频压缩网络把高维向量矩阵压缩成单维向量序列。

(2)用结合了Transformer的Diffusion模型,学习还原视频的特征
- 什么是扩散模型Diffusion Model
Diffusion Model的基本原理是将原始图片逐渐加入噪声(Noise),让原本清晰的图片逐渐变成全是噪声的状态。
Diffusion Model主要有两个过程:前向处理和反向处理。图解如下:
前向处理
AI训练过程中的1次噪声扩散

AI训练过程中,进行N次噪声扩散
- 进行N次噪声扩散,将图片变成全是噪点的图像

后向处理
- AI训练过程中,进行N次噪声降噪,变成清晰图片

经过如上扩散处理,我们得到了噪声与图像的关系。
利用transformer模型,既可以理解噪声的特性向量,也可以理解自然语言的特征向量,那么就可以建立噪声与提示词的关系。基于这种机制,模型就能够根据提示词来生成图片了。图片是视频的一帧,文生视频也可以用同样的原理来生成。
- Sora的Diffusion Transformer模型
在Diffusion Model的基础上,引入Transformer技术方法:
- 通过编码器,将每一帧噪声转换为向量,若干帧形成了噪声向量矩阵,Sora称之为Noisy patches。

- Sora的创新点:一次性生成Noise Vector Cude,用以保证帧与帧之间的逻辑关系。从而生成时间和空间更流畅、更连贯的视频。

2.3.Sora的技术优势
虽然OpenAI没有公布Sora模型的训练细节,但即使公布了,其他厂家可能也很难复制或追赶。
(1)Sora的Video compression network依托于强大的算力
模型成功的一个重要因素是海量的训练数据,训练需要消耗大量算力。Sora采用高维向量矩阵模式的视频处理方式,意味着更大算力消耗。中信证券曾简单估算,一个6~8秒的视频(约60帧)需要约6万个Patches,如果去噪步数是20的话,相当于要生成120万个Tokens,这是相当大的计算量。那么Sora生成1分钟视频需要的算力可想而知。
同一个提示词,算力越高,生成视频效果越好。Sora给出基础算力、4倍算力、32倍算力下的效果展示:
(2)GPT4加速孵化多模态大模型,多模态大模型反哺LLM
- 遥遥领先的自然语言理解能力:
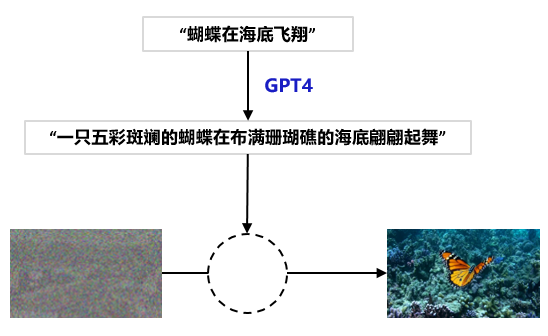
- 文生视频模型的训练离不开大量带有文字标注的视频,OpenAI基于GPT4专门训练一个高度描述性的字幕模型,使用它来为训练数据集中的所有视频生成文本字幕。这样进行训练极大的保证了文本保真度以及视频的整体质量。
- 同时,GPT优秀的文本扩展能力,可以丰富用户输入的提示词,让文本描述更丰富、更细致,从而生成丰富、细腻的视频。
3.Sora有哪些创意玩法
- Animating DALL·E images:图生视频
- 左边是图片和提示词,右边是生成的视频
- Extending generated videos:视频续写
- 基于原视频,向前或向后续写新的视频
- Video-to-video editing:编辑视频
- 左边是原视频,右边是根据提示词修改的视频
- Connecting videos:连接视频
- 通过左侧视频和右侧视频,生成中间过渡视频
- Image generation capabilities:生成高质量图片
- 生成各种尺寸的图片,分辨率最高可达 2048x2048

卓越的仿真能力:生成现实世界仿真视频
3D consistency:空间一致性
- 模拟摄像机镜头旋转和运行,画面中的人和场景元素在三维空间中也一致的移动。
- Long-range coherence and object permanence:时间一致性
- Sora能够有效地为短期和长期依赖关系建模。例如,模型可以保存人物、动物和物体,即使它们被遮挡或离开了框架(下左视频)。同样,可以基于单个样本生成同一角色的多个镜头,并在整个视频中保持其外观(下右视频)。
- Interacting with the world:模拟真实世界的动作和结果
- 随着画笔的移动,画面中增加了花瓣;人吃汉堡,汉堡留下咬痕。
4.Sora对视频相关领域的影响
内容创作与媒体行业:
在内容创作领域,Sora将缩短创作周期,降低制作成本。
导演、视频编辑等岗位将直面Sora的影响。
抖音类短视频App是否会面临挑战?
教育和培训: 教育工作者可以利用Sora创建生动的教学材料,提高课程互动性和学习效果。 但Sora仍然面临垂域微调的难题——我们尝试生成一个排序算法的Demo,得到的视频不尽如人意。
营销和广告 广告设计师和品牌经理可以通过Sora来快速生成视频广告内容。
游戏开发与动画制作 游戏设计师和动画制作人员可能会使用Sora快速原型制作和动画创建。 这不仅能够加快项目开发速度,还能使得复杂场景的测试和迭代变得更为高效。 不过,这也可能引发对传统动画和建模技艺的重新评估。
上下游基础设施: 上游厂商:AI服务器、AI芯片、通信行业、云厂商。 下游应用:大量的短/中/长视频应用和服务需求。
5.参考
https://openai.com/research/video-generation-models-as-world-simulators