笔者在使用大语言模型开展具体业务领域的任务时,遇到了如下问题:
- LLM的预训练模型不具备垂域知识,无法很好回答垂域的问题;
- 希望用各种提示词技巧让模型理解专业问题,但效果有限,而且提高了使用门槛和模型推理成本;
- 微调词嵌入模型成本低、速度快,但容易出现过拟合或泛化不足,也是治标不治本。
经过不断尝试总结,最终落脚点还是回到了大模型自身 – 大模型的微调才是关键。
什么是大模型微调?微调如何做?本篇开始,我们将为大家一步步揭开大模型微调的神秘面纱。

1.大语言模型的技术金字塔
大语言模型相关技术可分为四层,其中:
- 预训练的难度和成本最高,通常只有巨型公司(如谷歌、微软、OpenAI)才能承担其成本。
- 提示词工程难度和成本最低,普通人就可以掌握。
- 大模型微调的难度和成本次高,但从效果来看,是中小型公司可落地的折中技术。
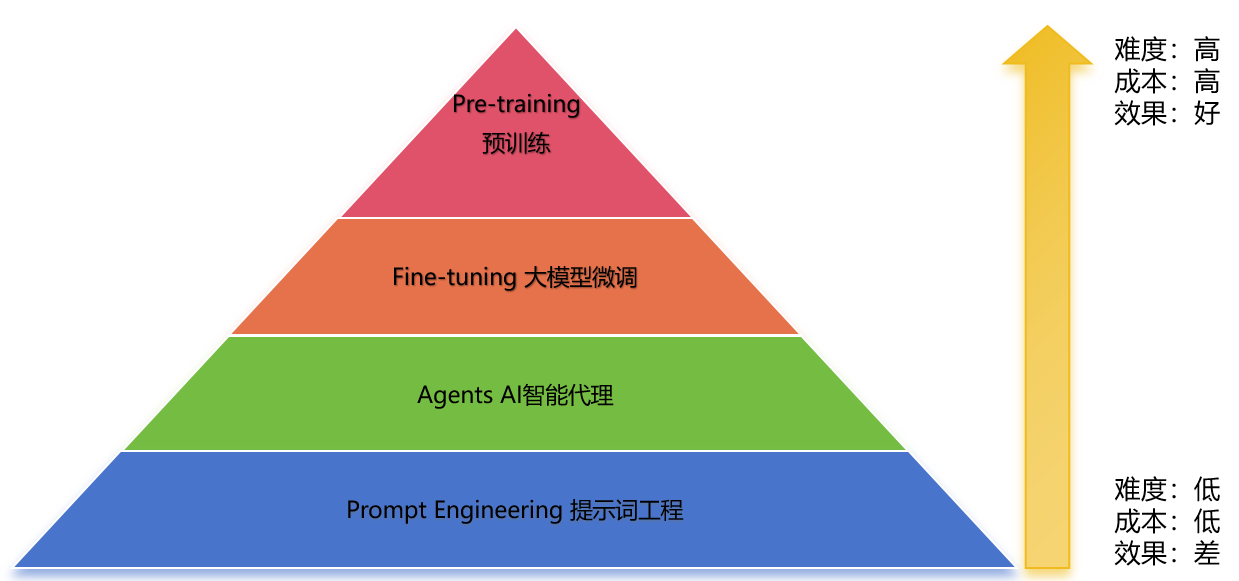
以下是各层技术的详细阐述:
- 提示词工程
- 技术原理:通过设计合适的提示或上下文来引导LLM生成期望的输出,侧重于用提示来激活预训练模型的能力,如总结摘要、翻译转换等。适用于文本处理、机器翻译等场景。
- 技术特征:技术门槛低,终端用户即可掌握。
- Agents:
- 技术原理:让LLM来决策一系列的动作,这些动作可以是让LLM分步解决问题,也可以是调用工具查询外部信息。这些动作形成一个工作流,最终完成任务目标。适用于相对复杂的用户交互应用,如智能客服。
- 技术特征:有技术门槛,需要专业的LLM应用开发人员,并且了解大模型的基础原理,熟悉其领域的业务逻辑和流程。
- 大模型微调:
- 技术原理:在预训练模型的基础上,针对特定任务的参数做调整。通过少量的数据训练即可提升模型在特定任务上的能力,同时保留模型原已学到的知识。适用于语义理解、垂域的各类应用。
- 技术特征:技术门槛相对高,需要垂域有自己的LLM应用研发团队,具有数据处理、模型训练的能力和经验。
- 预训练技术:
- 技术原理:比如训练出一个"GPT3.5”,或者"GLM3.0”。
- 技术特征:百G甚至千G的GPU资源需求,大量的大模型研究人员、数据科学家投入,超出了大部分公司的能力。一旦功成,效果显著。
由于大模型微调的实用性,本专栏后续会展开介绍大模型微调技术。
2.大模型微调的可行性及理论基础
(1)In-Context Learning
OpenAI在预训练过程中,发现LLM能够挖掘训练数据中的潜在特征和通用范式,进而习得训练数据之外的新能力。研究者把这一发现称之为In-Context Learning(基于上下文的学习)。
基于In-Context Learning思想,衍生出了两种训练微调技术:
Prompt-tuning
Instruction-tuning
In-Context Learning的本质就是举一反三,基于已知的知识和训练数据可以挑战从没做过工作(下游任务)。预训练模型所蕴含的知识、预训练模型所使用的数据是广义上的context。正因为In-Context Learning的有效性,所以对预训练模型进行微调是业界公认可行的技术路线。
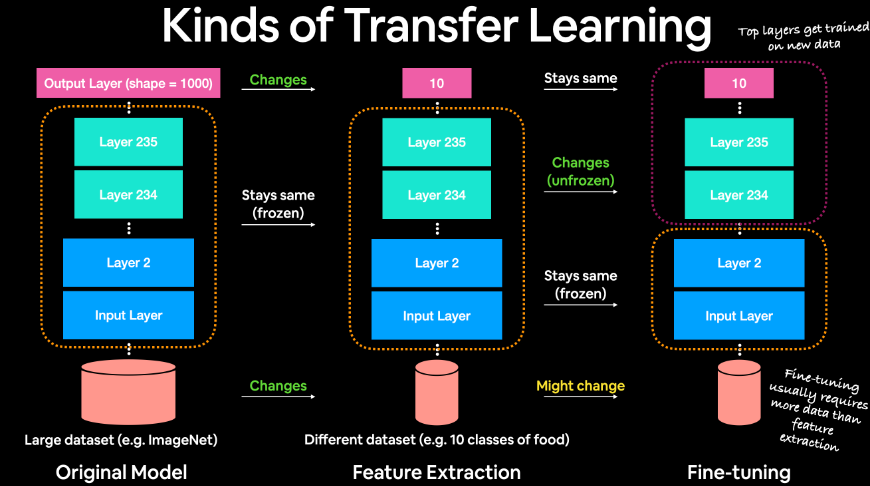
(2)Transfer Learning
Transfer Learning(迁移学习)是人工智能发展过程中的一个重要思想,它的目标是将已经训练好的模型所包含的知识、推理能力迁移到未经训练的新模型上。比如对模型进行压缩、复用开源模型已经具备的能力来新模型,都是基于迁移学习思想。
迁移学习包含很多具体的工程方法:
- Conservative Training
- Multi-task Learning
- Progressive Neural Network
- Domain-adversarial training
- Zero Shot Learning
- ……
无论有多少种工程方法,其核心思想是:已训练的数据和任务与未训练的数据和任务存在因果、关联等逻辑关系。
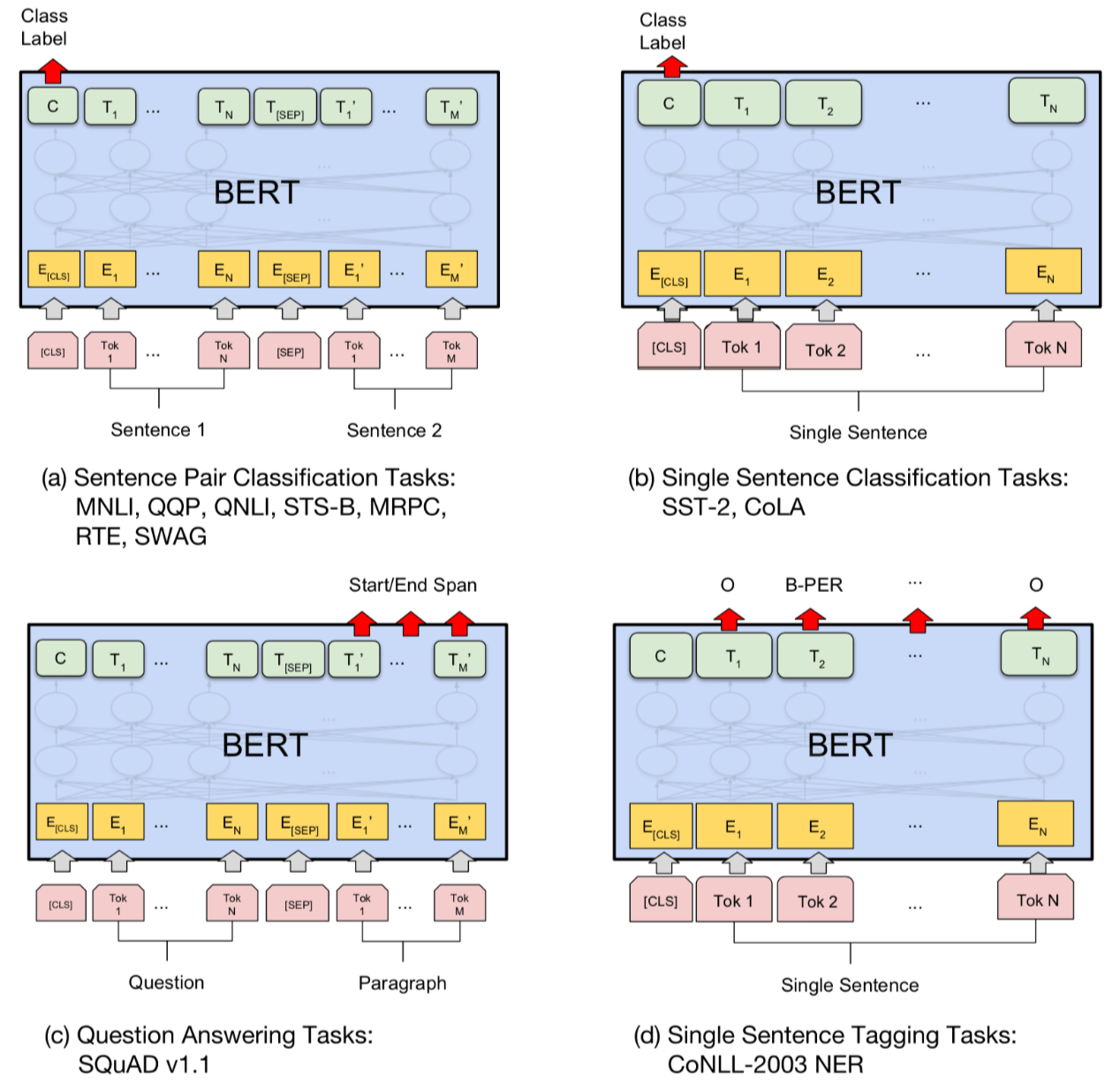
(3)Bert的优秀实践
Bert充分发挥了Fine-tuning的技术优势和特点,在已经训练好的Bert模型基础上,加入少量的task-specific parameters。
- 如分类任务,只需要在Bert模型上加一层softmax网络,然后对softmax网络进行微调。
- 再如情感分析任务,取第一个token的输出表示,喂给一个softmax层得到分类结果输出。
微调Bert之所以成功,其本质原因是由于In-context Learning和Transfer Learning的有效性。
3.大模型微调的技术全景图
(1)大模型微调技术全景
大模型微调技术从大的流派上可分为两类:
- Full Fine-Tuning:简称FFT,全量微调,即全参数微调。
- Parameter-Efficient Fine-Tuning: 简称PEFT,高效微调,即通过某些技术手段选择部分参数微调。

与FFT相比,PEFT是当前业界主流的技术路线,其原因主要是FFT存在如下缺陷:
- 训练成本过高
- 灾难性遗忘
(2)PEFT技术分支
PEFT从微调目标方面可分为两类:
- Supervised Fine-Tuning: 简称SFT,属于有监督的微调。
- Reinforce Learning Human Feedback: 简称RLHF,属于利用人类反馈的强化学习。
其中SFT又具有诸多工程实践,因此产生了很多技术分支:
- Additive: 增量派,在原有模型上增加额外小模型和少量参数。
- Selective: 选择派,从原有模型的海量参数中,选择与下游任务相关的少量参数。
- Reparametrization-based: 数学派,基于重参数化方法,将原有模型参数低秩化,获得小参数矩阵。
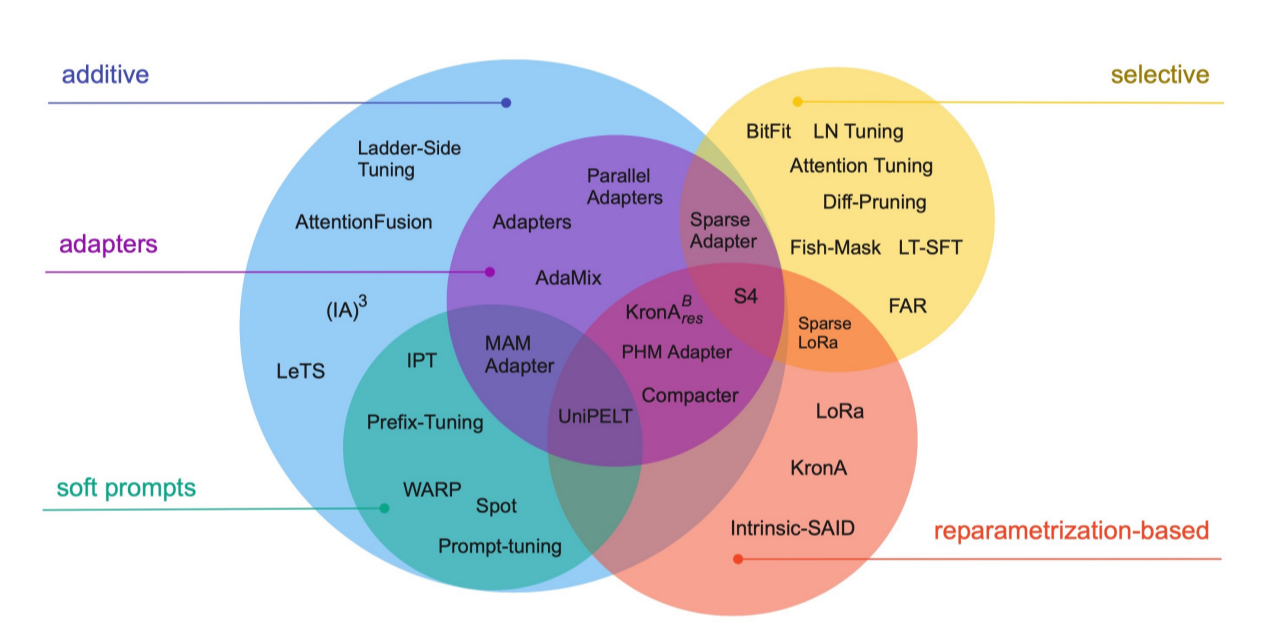
在上述流派中,每个流派都有自己的代表方法,目前在业界广泛使用:
- Sparse Adapter: 稀疏适配器。新增小模型,并从原有大模型中选择一部分参数,对这两部分参数进行微调。
- Prefix-Tuning: 模块化轻量微调。增加prefix模块(Prefix模块会在用户输入前增加虚拟token),训练prefix模块的参数。
- LoRA: Low-Rank Adaption,低秩适配微调。它是目前业界在大语言模型、大视觉模型、多模态模型微调中的热门技术。
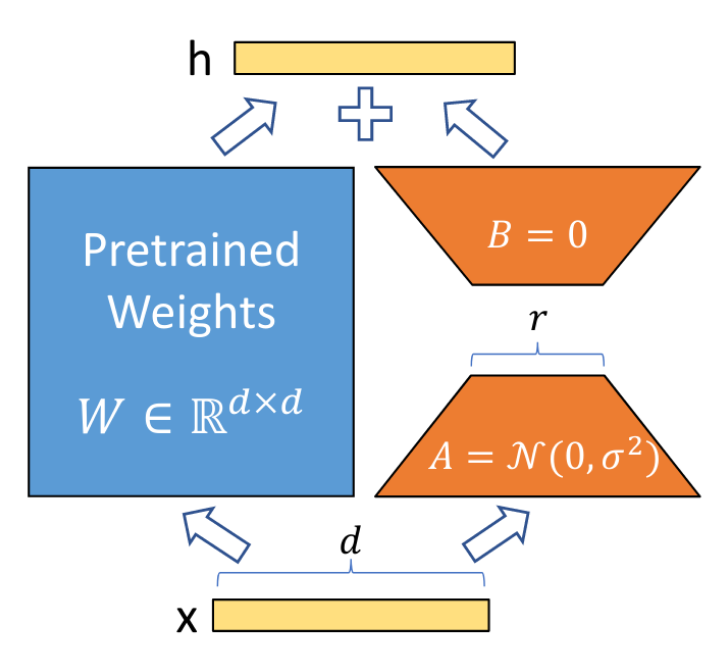
上述技术分支的关系错综复杂,我们可以抽象的概括一下它们的技术思想:
- 基于数据的技术分支:其核心思想是对进入预训练模型的训练语料进行前置处理。
- 如soft prompts中的Prompt-Tuning、Prefix-Tuning、P-Tuning,都是属于此技术分支。
- 基于模型的技术分支:其核心思想是在预训练模型基础上增加额外的模型分层,仅针对增量模型的参数和预训练模型的少量参数进行微调和变换。
- 如Adapter模型属于此技术分支。
- 如LoRA、QLoRA、AdaLoRA也属于此技术分支。
4.小结
本文从宏观上介绍了大模型微调技术的全景图,重点梳理了PEFT微调技术的众多技术分支,旨在帮助大家了解大模型微调技术的全貌。本专栏后续文章会展开阐述PEFT的各类微调技术。
- 大语言模型的技术金字塔
- 大语言模型相关技术可分为四层:提示词工程、Agents、大模型微调、预训练技术。
- 预训练的难度和成本最高;提示词工程难度和成本最低;大模型微调的难度和成本次高,但从效果来看,是中小型公司可落地的折中技术。
- 大模型微调的可行性及理论基础
- In-Context Learning
- Transfer Learning
- Bert的优秀实践
- 大模型微调的技术全景图
- Full Fine-Tuning
- Parameter-Efficient Fine-Tuning