Adapter Tuning是LLM微调技术中一个重要的技术分支,于2019年由Google的Neil Houlsby等研究员提出。
Adapter Tuning方法证明了:微调少量参数即可获得与全参数微调接近的大模型性能。
本文解读Neil Houlsby的论文**《Parameter-Efficient Transfer Learning for NLP》**,与小伙伴们一起学习理解Adapter Tuning思想和方法。

1.Abstract(摘要)
首先我们看一下论文摘要,快速理解论文的核心内容:
问题:基于迁移学习思想,需要针对特定的下游任务,对预训练模型进行全参数微调。但针对每个下游任务都要做一次全参数微调,成本高效率低。
解决方案:论文提出的
Adapter Tuning,是一种使用Adapter(适配器模块)进行迁移学习的方法。Adapter(适配器模块)仅需要微调少量参数,就可以支持不同的下游任务。实验效果:在GLUE基准测试中,用
Adapter Tuning方法仅需在预训练模型基础上增加并微调3.6%的参数,即可达到BERT Transformer模型全参数微调的效果。
通过上述摘要的内容,我们可以想象一下,在2019年绝大多数人还在采用全参数微调这种高成本方案时,Adapter Tuning仅需微调3.6%的少量参数,会产生多大的生产效率差异。

2.Introduction(介绍)
- 背景技术1:基于特征的迁移和微调(
feature-based transfer and fine-tuning)是迁移学习思想中的重要工程方法,它也是BERT模型的重要理论基础。论文中:Fine-tuning involves copying the weights from a pre-trained network and tuning them on the downstream task,表达了BERT模型的训练范式——复用1个BERT的预训练模型的参数(基于特征的迁移),再针对不同下游任务进行微调(基于特征的微调)。 - 背景技术2:历史上,已证明针对预训练模型的网络结构中的高层(
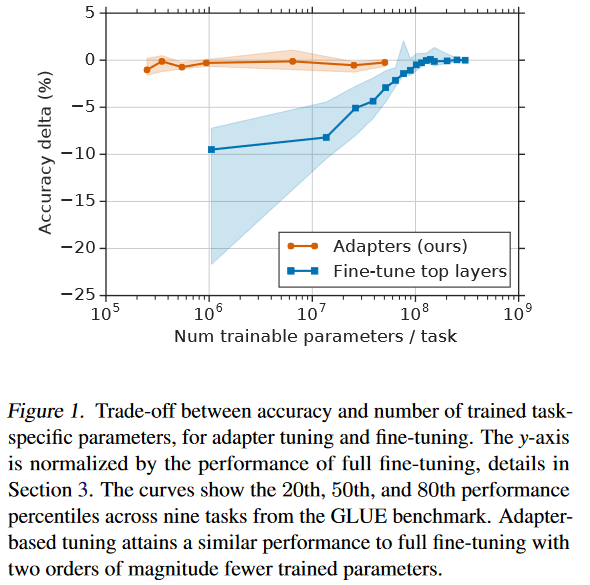
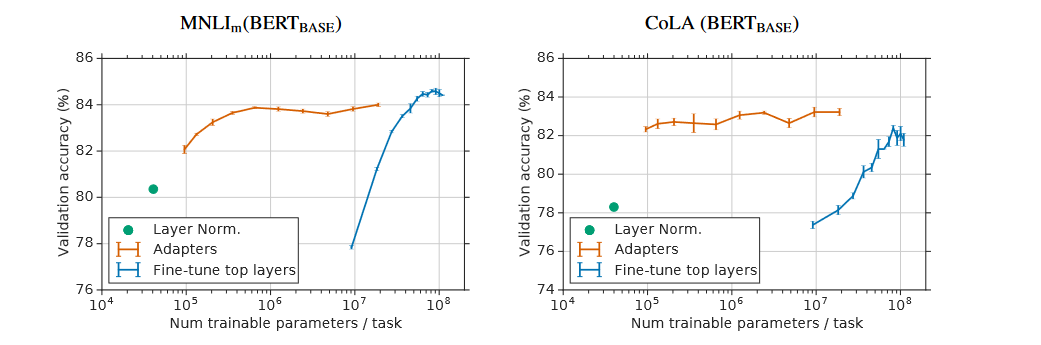
top layer)进行基于特征的微调,相较于基于特征的全参数微调,更具有性价比。 - 实验效果:对比Adapter Tuning、Top Layer Fine Tuing、Full Fine Tuning在多任务微调场景下的效果:
- 在小参数模型上的表现:Adapter Tuning可达到Full Fine Tuning的效果,Top Layer Fine Tuing达不到。
- 在稳定性方面的表现:Adapter Tuning的训练效果很稳定,Top Layer Fine Tuing在小参数模型上波动大、只有在大参数模型上才能保证稳定的训练效果。
- 在性价比方面的对比:Adapter Tuning可以微调少量参数,即可达到Full Fine Tuning的训练效果。
- Adapter Tuning的核心思想:
- 基于特征的迁移和微调的思想是将预训练模型抽象为
f(w),对下游任务微调抽象为g(v, f(w)),微调的过程是不断学习修改参数w和v,这样就导致预训练模型的参数w被修改,进而导致极高的训练成本。 - Adapter Tuning的思想是将预训练模型抽象为
f(w),对下游任务微调抽象为g(v, w),微调的过程是不断学习修改参数v,直接复用预训练模型的参数w而不是修改它,又因为参数v的数量级远小于参数w,因此训练成本极低。另外,针对新的下游任务n只需要增加新的Adapter,训练对应的参数vn。 g(v, w)的具体代码实现等效于,在原有预训练模型的网络结构中,插入一些Adapter层,预训练模型参数w作为Adapter层的入参,训练的目标是学习并修改Adapter层的参数v。
- 基于特征的迁移和微调的思想是将预训练模型抽象为

- 容易与Adapter Tuning混淆的其它训练方法:
- 多任务学习:multi-task learning,也会在预训练模型的网络结构中增加新层,最终也是修改了新层的参数。但多任务学习的训练,是将所有下游任务作为训练新层参数的输入。
- 持续学习:contiuanl learning,是将N个下游任务组成任务流后逐一学习,这样就要求训练
任务m时,预训练模型的网络结构能够记住之前已经训练过的任务1~任务m-1得到的参数。这将对预训练模型的记忆能力产生巨大的挑战。

3.Adapter Tuning(原理)
Adatper Tuning具体是如何实现的呢?论文中详细解释了Adapter层的网络结构,以及如何在原始的预训练模型上插入这些Adapter层:
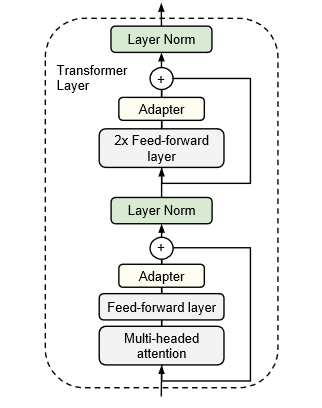
- Adapter层的插入位置:在Transformer的多头注意力+前馈网络层之后,2x前馈网络层之后,分别插入了Adapter层。另外,在每个Adapter层之后还插入了一个Layer Norm层。
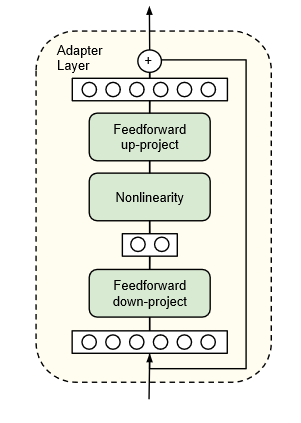
- Adapter层的内部结构:Adapter层包含3层
- 前馈网络的向量降维层:用于将前一层预训练模型输出的高维向量,降维为低维向量。
- 非线性处理层:对下游任务微调时,学习参数
v。 - 前馈网络的向量升维层:用于将Adapter层输出的低维向量,升维为高维向量。
- Adapter层的参数数量计算公式:
count(v)=2md+d+m- d:前一层预训练模型输出的高维向量的维数。
- m:Adapter层降维后的低维向量维数。
- 实践经验:当m远小于d时,Adapter层的参数量会很小。论文给出的经验数据是可以通过控制m的数值,将Adapter层的参数量控制为预训练大模型参数量的0.5%~8%。这样,可以精准控制微调成本。
4.Experiments(实验结果)
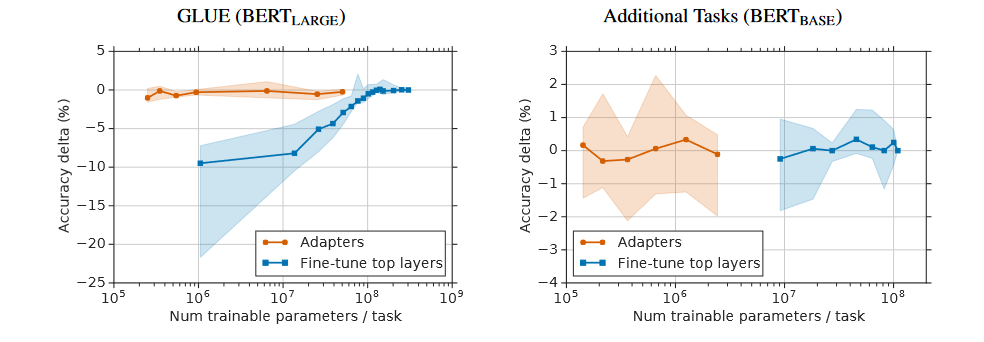
论文至此就一个实验结论:Adapter Tuning就是香,具体如下:
- 在GLUE基准测试和其他17个公共文本分类任务上,适配器调优效果,优于全参数微调。
- 适配器调优在参数数量大幅减少的情况下,仍能保持与全参数微调相近的性能。
5.总结
从上述论文解读中,我们收获了如下技术观点:
- Adapter Tuning的价值:追求微调少量参数,仍能达到全参数微调效果。
- Adapter Tuning的核心思想:增加一个新的小模型,微调小模型的少量参数,冻结预训练模型的海量参数。
- Adapter Tuning的具体实现:改变预训练模型的网络结构,通过高维向量到低维向量的转换,训练不同下游任务的Adapter层。
论文链接:https://arxiv.org/pdf/1902.00751.pdf