前面给大家分享了Soft Prompt技术分支下的Prefix-Tuning和Prompt Tuning,在这个技术分支下,还有一项需要重点了解的微调技术——P-Tuning。
P-Tuning是清华大学和MIT于2021年联合发布的一项微调技术,在NLU(自然语言理解)任务上有重大突破。
本文解读论文**《GPT Understands, Too》**,我们一起来学习一下P-Tuning技术的原理。
1.Abstract(摘要)
首先我们看一下论文摘要,快速理解论文的核心内容:
问题:Discrete Prompts(离散提示词)会导致大模型性能不稳定。
- 比如:修改提示词中的一个单词,都可能导致大模型的性能大幅下降。
- 本质:根据自然语言形式的提示词进行预测,对于大模型本身从数学上是不可微的(这就是数学意义上的离散性)——不可微就意味着AI无法高效、稳定地提特征。
解决方案:论文提出的
P-Tuning技术,也是一种使用Soft Prompt(软提示)进行迁移学习的方法。将离散提示词向量化为可训练的连续提示词(trainable continuous prompt embeddings)。实验效果:
- P-Tuning通过连续提示词向量,降低了不同离散提示之间的差距,进而提升了模型的稳定性。
- P-Tuning在LAMA、SuperGLUE等NLU任务上,显著提高了模型性能。

2.Introduction(介绍)
- 问题:离散提示会导致大模型的稳定性问题。
- 以手动离散提示为例:提示中改变一个单词可能会导致显著的性能下降,存在很大的不稳定性。
- 一些优化尝试:
- 调整语言模型本身,不稳定性问题有所缓解,但不同提示之间的性能差异仍然很大(特别是在少样本场景下)。
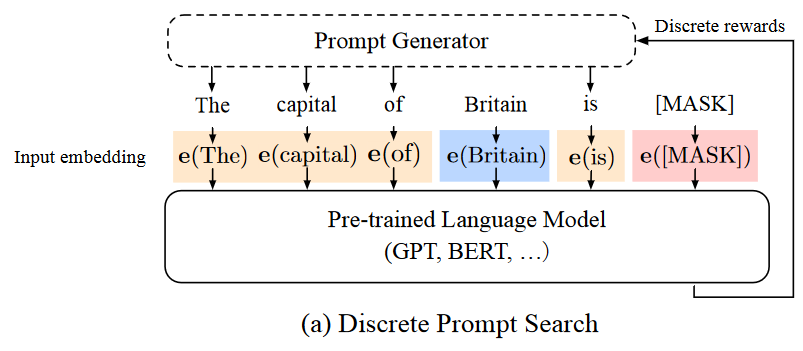
- 自动提示法(automatic prompting):试图为给定任务搜索更好的提示,但这些方法并没有改变离散提示的不稳定本质。
Prompt Tuning的核心思想:
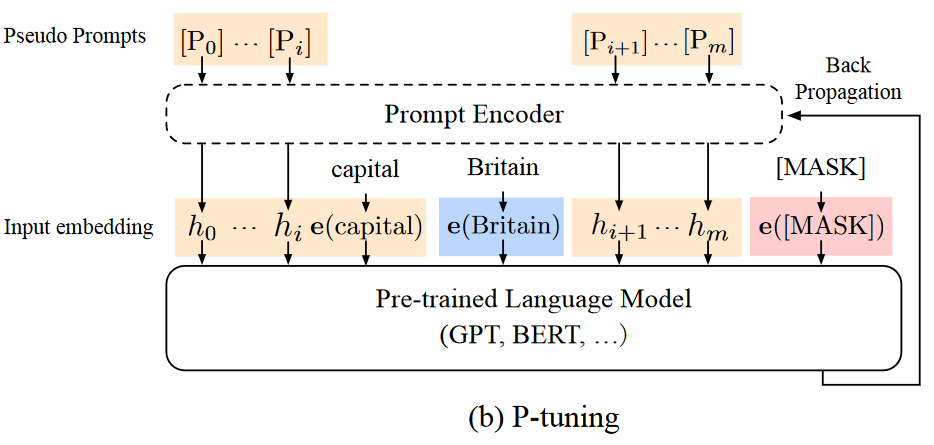
- prompt encoder:论文提到通过prompt encoder(提示词编码器),将输入的离散提示Token,和连续提示Embedding连接起来后,输入给大语言模型。其中,prompt encoder可采用LSTM或MLP来实现。
- backpropagation to optimize…:可以通过反向传播,优化连续提示词,进而将离散提示转变为可微的连续提示。
- P-Tuning的本质:该技术的本质打破离散提示的限制——离散则不便于提特征,连续可微则可学习——因此P-Tuning抵消了离散提示中微小变化对稳定性。
实验效果:
- 在LAMA基准测试中,使用P-Tuning,比手动离散提示(manual discrete prompts)提升了20多分,比搜索提示(searched prompts)提升了9分。
- 在SuperGLUE基准测试中,在全监督和少样本下都优于PET的最佳离散提示(the best discrete prompts)。
- 实验还证明,在更广泛的任务中,P-Tuning降低了不同离散提示之间的差异,进而提升了模型的稳定性。
3.Design Decisions(实验设计)
(1)问题域
提示词是大家耳熟能详的激发LLM能力的技术手段,但是从数学上具有极大的局限性——就是它是数学意义上的离散。
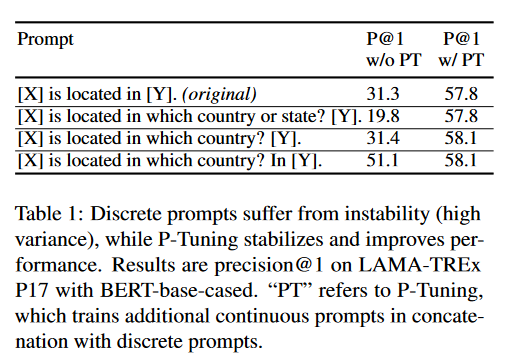
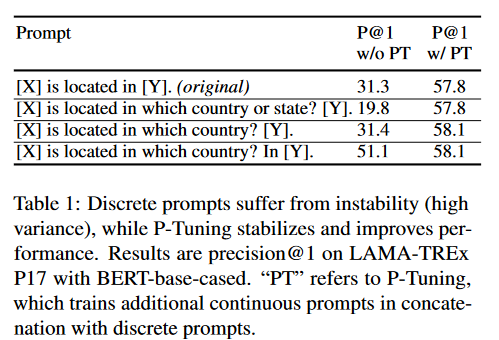
论文作者举了这样的一个例子:
- 表格第三行和表格第四行的两个提示词,只是少了一个单词In,AI猜出来X和Y填什么的准确度就下降了20分。
在本论文发表前,业界还有一些自动化搜索离散提示的优化尝试:
- mining the training corpus:挖掘训练语料库。
- gradient-based searching:基于梯度的搜索。
- using pretrained generative model:使用预训练的生成模型。
这些优化方法的本质就是自动生成提示词,但是用自然语言表示的提示词依然还是数学意义上的离散。
(2)问题建模
论文对问题进行了数学建模:
- M、V、h:M表示预训练模型, 词表大小V,隐藏层大小h。
- {(xi, yj)}i:表示在NLU任务中的数据集。x0:n={x0, x1, …, xn}是一系列离散Token组成的输入,y∈Y表示标签。
- fM(x)=p(y|x):表示预训练模型M的任务,就是预测分类的条件概率。
- [Di]:表示离散提示的Token,每一个离散提示都可以表示为T = {[D0:i, x, [D(i+1):j], y, [D(j+1):k]}。
通俗一点说,上面这一通数学建模,就是描述了一个填字游戏:
- 比如:The capital of is [y]。
- 如果x=Britain,则希望AI输出y=London。
- 如果x=中国,则希望AI输出y=北京。
离散提示T = {[D0:i, x, [D(i+1):j], y, [D(j+1):k]}会被Embedding为{e(D0)…e(Di), e(x0), …, e(xn), …, e(Dk)},其中e ∈ R|V|×d。如下图:
P-Tuning的实现怎么表达呢?如下:
- [Pi]:表示第i个连续提示Embedding,注意论文的表述——连续的提示词嵌入(continuous prompt embedding)。
- T = {[P0:i, x, [P(i+1):j], y, [P(j+1):k]}:基于[Pi]的含义,那么任意一个提示词都能表达为T = {[P0:i, x, [P(i+1):j], y, [P(j+1):k]}。
- f: [Pi]->hi:一个词嵌入函数,用来将T = {[P0:i, x, [P(i+1):j], y, [P(j+1):k]}转换为{h0, e(x), hi+1, …, hj, e(y), hj+1, …, hk}。
- {Pi}ki=1:表示P-Tuning的目标——反向传播,优化损失值,在预训练模型之前学习到提示词的特征。
不严谨地理解一下P-Tuning的玩法——就是加了个新的神经网络,不断地在学习如下提示词:
- 如果有人说:吾饥矣,你就要说:我给你下面吃啊。
- 如果有人说:吾腹中空空,你就要说:我给你下面吃啊。
- 如果有人说:吾腹鸣如鼓,你就要说:我给你下面吃啊。
它会发现吾饥矣、吾腹中空空、吾腹鸣如鼓的特征,都是在说肚子饿了,于是在调用大语言模型之前,它就把自然语言形态的离散提示词都转变为:
- 如果有人说:我饿了,你就要说:xxx。
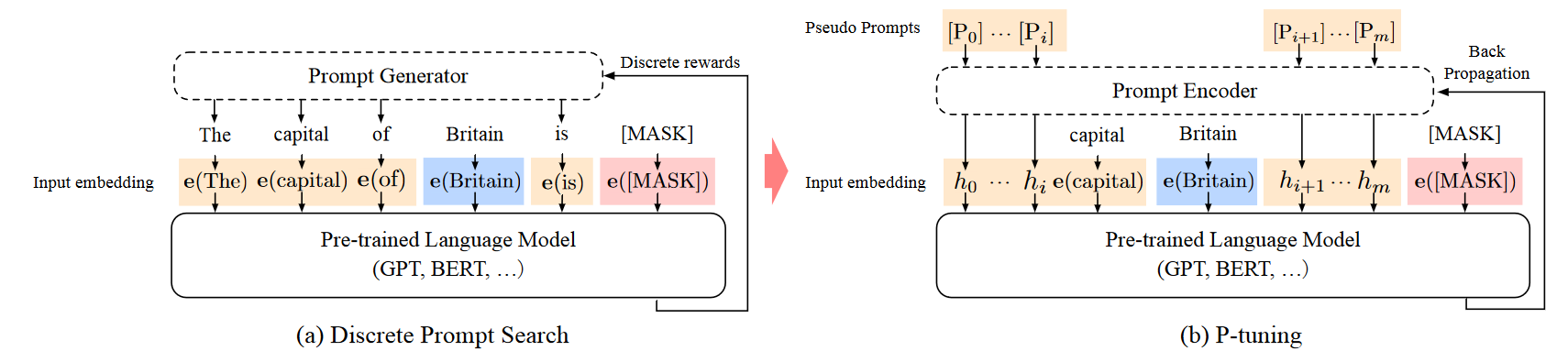
最后,我们来完整地对比一下自动化搜索离散提示法和P-Tuning的差别:
- 自动搜索离散提示用的是Prompt Generator找特征。
- P-Tuning是用Prompt Encoder找特征。
- P-Tuning将数学意义上的离散提示词转换为了连续可微提示词,帮助AI更好地提特征。
- 其实两种思路本质都一样,都是很巧妙的想法。
- 论文还提到Prompt Encoder的实现采用了LSTM、MLPs、identity mapping function(恒等映射函数)。
4.Experiments(实验结果)
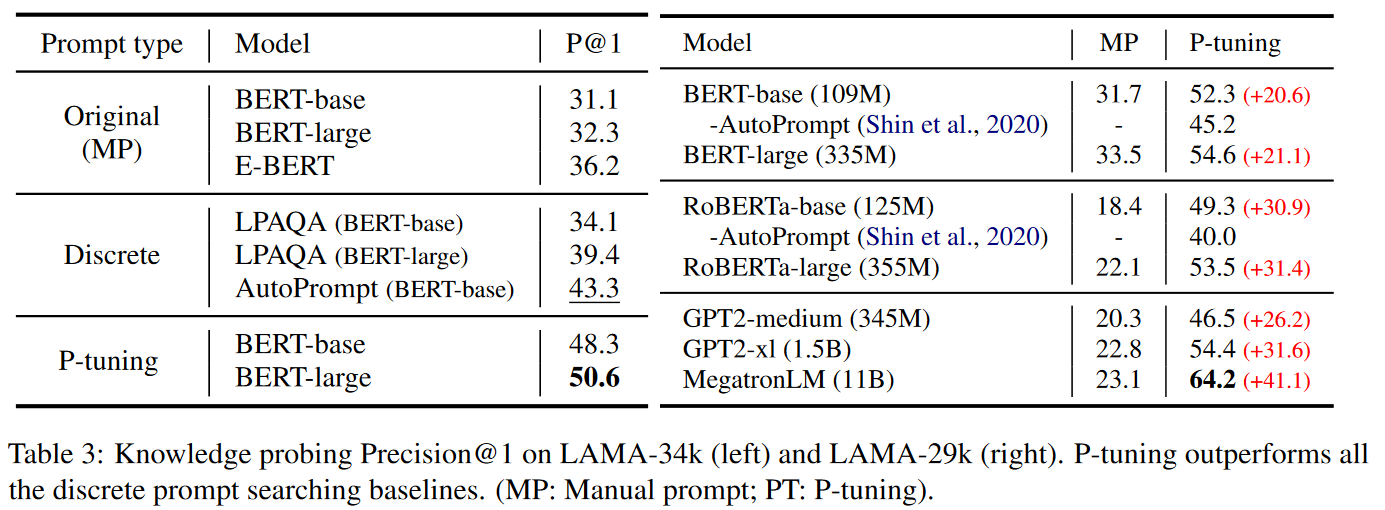
(1)实验结果1:Knowledge Probing
在知识探索(Knowledge Probing)型任务上,实验可以评估出AI获得现实世界知识量。
LAMA数据集创建了三元组形式的完型填空,来实施知识探索评估。
从实验结果上看,P-Tuning显著提高了知识探测的效果。
- LAMA-34k数据集:从43.3%提高到50.6%
- LAMA-29k数据集:从45.2%提高到64.2%
- 相较于离散提示搜索方法:P-Tuning优于离散提示搜索方法。
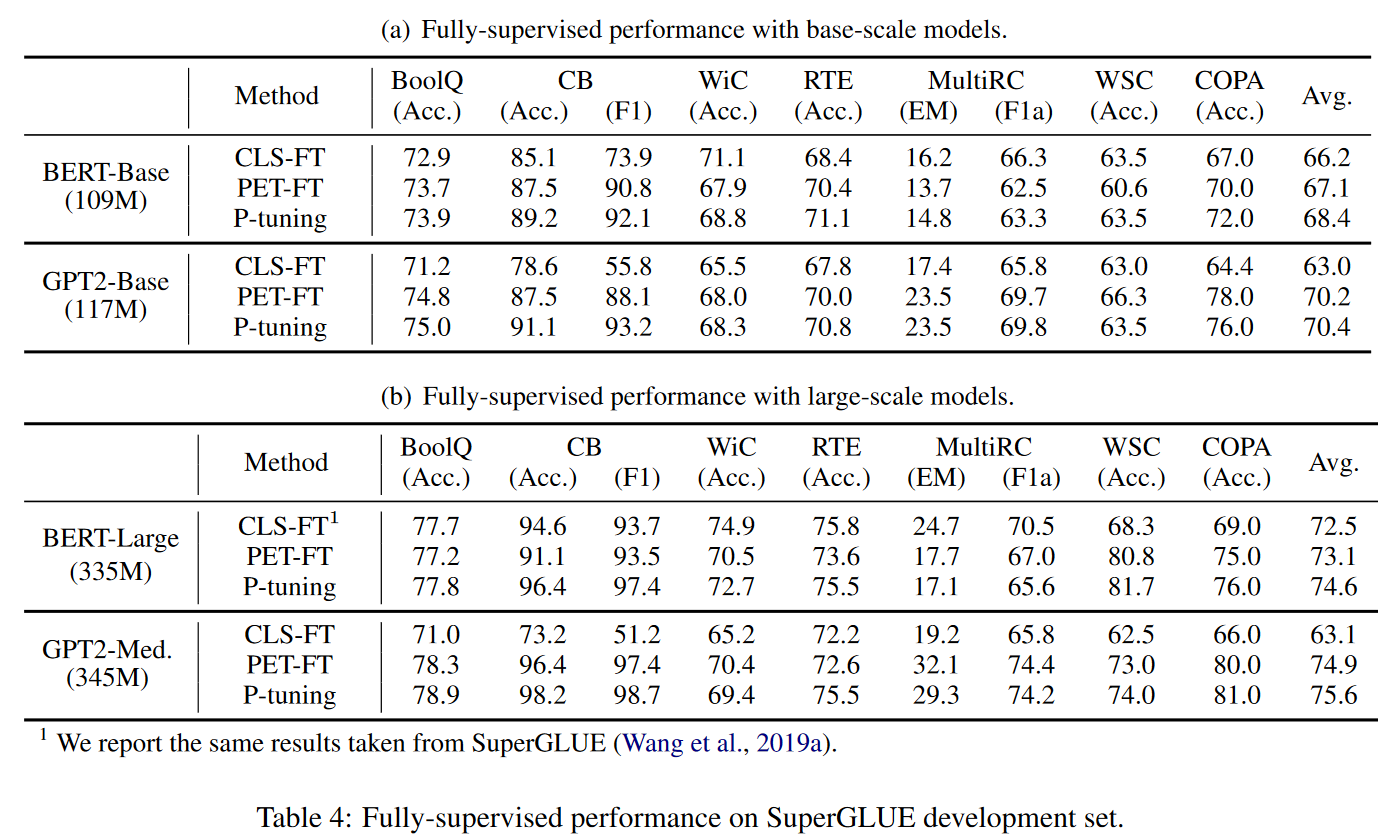
(2)实验结果2:Fully-supervised Learning
实验采用了SuperGLUE基准测试,测试了7个自然语言理解任务(NLU)。包括:
- 问答、MultiRC、文本蕴含、RTE、共指消解、因果推理、词义消歧。
实验使用了四个版本的预训练模型:
- GPT2-Base
- GPT2-medium
- BERT-Base
- BERT-Large
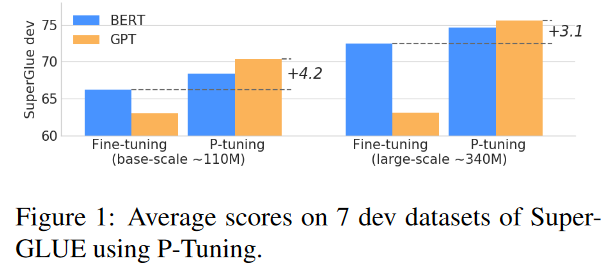
实验证明P-Tuning可以提高 BERT和GPT上的全监督学习性能:
- 在 BERT-Base上,P-Tuning在5/7任务上实现了最佳性能。
- 在 BERT-Large上,P-Tuning在4/7任务上超越了其他方法。
- 在 GPT2-Base和 GPT2-Medium上,P-Tuning 在所有任务上始终是最佳性能。
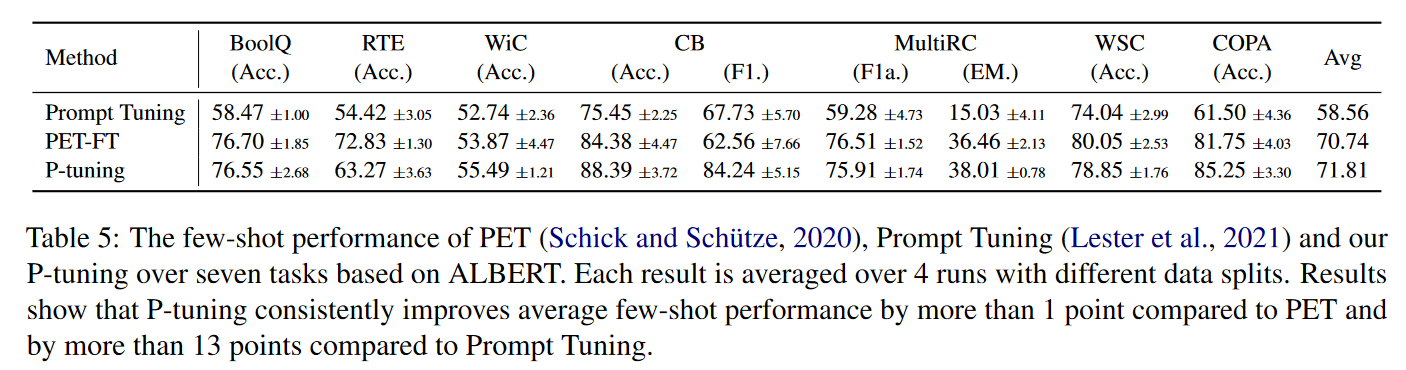
(3)实验结果3:Few-Shot Learning
实验使用了少样本SuperGLUE基准测试,就是FewGLUE数据集。
实验证明了P-Tuning有一定的提升:
- ALBERT上,比PET平均高出1个点、比Prompt Tuning高出13个点。
5.总结
从上述论文解读中,我们收获了如下技术观点:
- 离散提示的问题:数学上离散,不便于AI提特征。
- P-Tuning的核心思想:将离散提示词转换为连续可微提示词,微调的目标是用LSTM这类网络学习提示词特征。
论文链接:https://arxiv.org/pdf/2103.10385