上篇专栏我们讲到,P-Tuning V1通过在预训练模型的输入层加入可训练的连续提示,有效提升了训练效果。但其在复杂NLU任务和小参数模型上表现并不理想。
P-Tuning V2是对P-Tuning V1的改进,使其能在不同规模的模型和各种NLU任务中都能与全量微调相媲美。
本文解读论文**《P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks》**,探究Prompt Tuning V2技术的原理。

1.Abstract(摘要)
首先我们看一下论文摘要,快速理解论文的核心内容:
- 问题:P-Tuning v1的最大问题是不具备普适性(a lack of universality)。
- 不同规模模型的微调效果不稳定:Lack of universality across scales。模型规模超过10B时,P-Tuning v1和Fine Tuning水平相当。模型规模在0.1B到1B时,P-Tuning v1的效果远不如Fine Tuning。
- 不同下游任务的微调效果不稳定:Lack of universality across tasks。实验证明,针对某些下游任务进行P-Tuning v1,效果远差于Fine Tuning。
- 解决方案:论文提出P-Tuning v2技术,采用Deep Prompt Tuning方法,同时针对NLU任务做了一定适配和优化。
- 实验效果:实验证明P-Tuning v2,在不同规模的模型上、在不同下游任务上都可获得较高的稳定性。是一种对P-Tuning v1更好的替代方法。

2.Introduction(介绍)
问题:P-Tuning v1在不同规模的模型下、不同下游任务中,微调效果不稳定。
- 如:当模型大小不大,特别是少于10B参数时,P-Tuning v1的表现不如Fine Tuning。
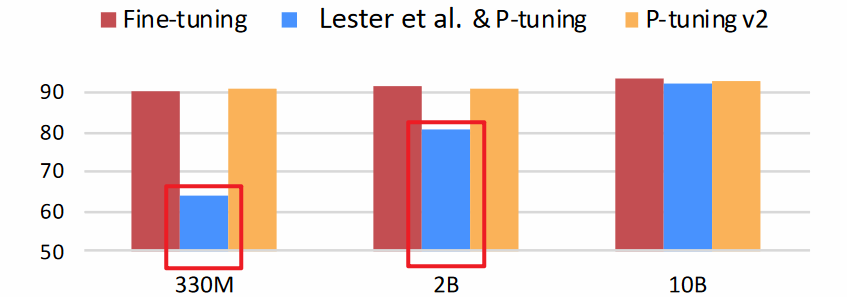
- 如:抽取式问答(extractive question answering),P-Tuning v1的表现不如Fine Tuning。

P-Tuning v2的核心思想:
- P-Tuning v2采用Deep P-Tuning的优化方式,用于探索垂域知识。
- Deep表现于在预训练模型的每一层注意力层增加了一个小模型,作用于每一层的输入。而P-Tuning v1仅在第一层增加了一个LSTM小模型。
- 这种方法的本质是:不同规模的模型对于P-Tuning v1在第一层增加的前缀向量的特征提取能力不同。越大的模型特征提取越强,后续各层都能感知注意到这个前缀向量的特征。反之,小模型特征提取能力弱,后续各层无法感知注意到前缀向量的特征。
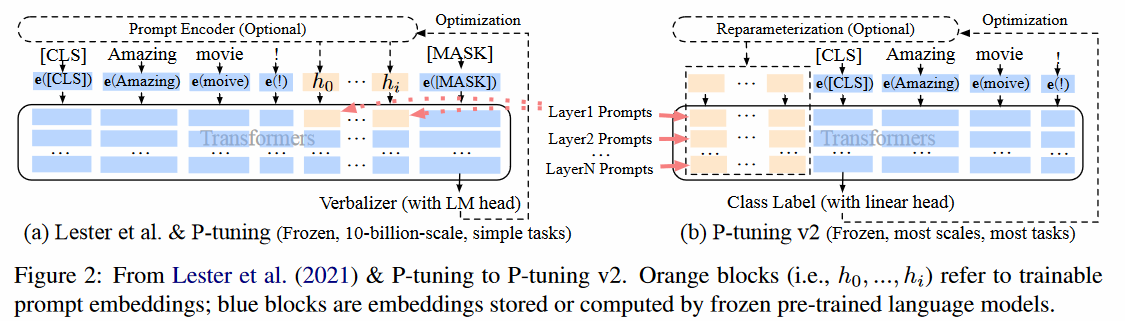
- 实验效果:
- 对300M到10B参数的模型上实验,P-Tuning v2具备很稳定的微调效果。
- 以抽取式问答和命名实体识别为代表的下游任务上,P-Tuning v2具备很稳定的微调效果。
3.Design Decisions(实验设计)
(1)问题域
P-Tuning v1提出了将数学意义上的离散提示词转换为连续可微的提示词,但存在的问题还有2个:
- 不同规模的模型微调效果不稳定。
- 不同下游任务的模型微调效果不稳定。
离散到连续是Soft Prompt技术分支的重要思想、重要里程碑,但P-Tuning v1已经做到连续可微了,还有什么改进空间呢?
(2)问题建模
为了寻找突破口,我们还是进行数学建模:
- V、M、e:V表示模型M的词汇表,e表示模型M的词嵌入层。
- 离散到连续的转换:假定离散提示词为序列**[h0, …, hi]**,经过**P-Tuning v1**的**Prompt Encoder**模块转换为向量序列**[e(x), e(h0), …, e(hi)]**。
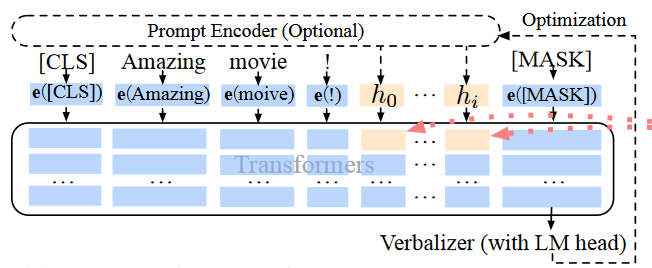
通过问题建模,我们可以看到数学意义上的离散提示已经表示为连续提示。那么不同规模的模型、不同下游任务的微调效果不稳定,很可能源于P-Tuning v1在输入层添加的前缀向量没有起到有效作用,从逻辑上,我们可以有如下猜测:
- 模型规模对前缀向量的影响:不同规模的模型对前缀向量的特征提取能力是不同的,小模型特征提取不足,导致后续预训练模型的各层无法感知注意到前缀向量。
- 下游任务类型对前缀向量的影响:从离散提示词看,不同下游任务的提示词是不同的。同理,不同下游任务的连续提示词应该也是不同的。
因此:
- 从数学上,P-Tuning v1的连续可微前缀向量没有太多改进空间。
- 从模型结构上,
- 可以在Transformer的各层添加前缀向量,以抵消小模型对前缀向量的特征提取不足的局限。
- 可以改变前缀向量的长度,以实现不同下游任务有不同的前缀向量。
为了更好地阐述论文的改进思路,我们列出相关源码:
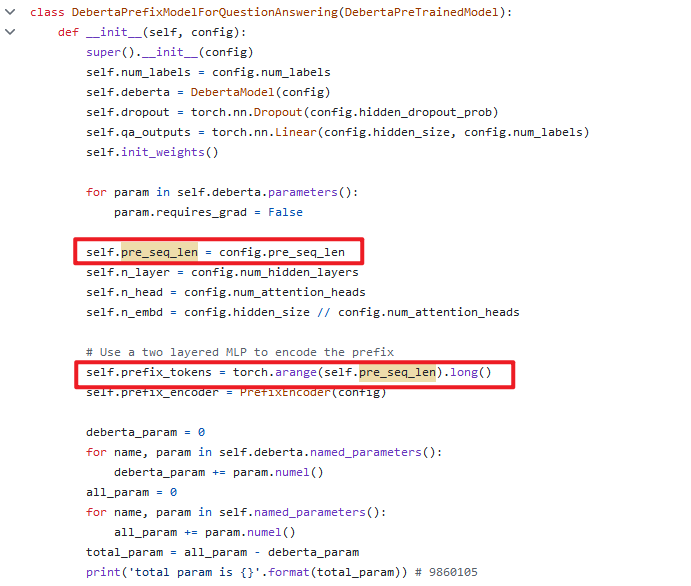
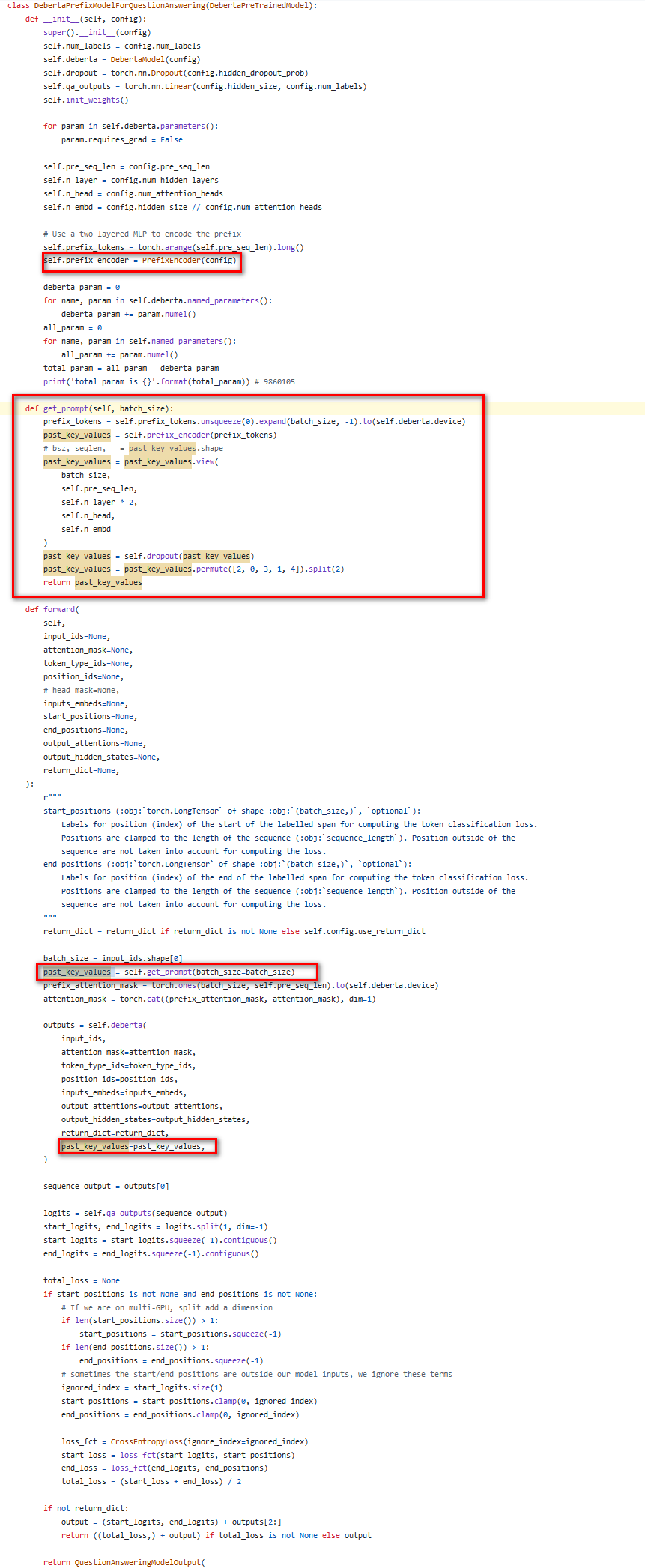
DebertaPrefixModelForQuestionAnswering类,是针对QA下游任务的。
支持通过超参数,设置不同下游任务的前缀向量长度。
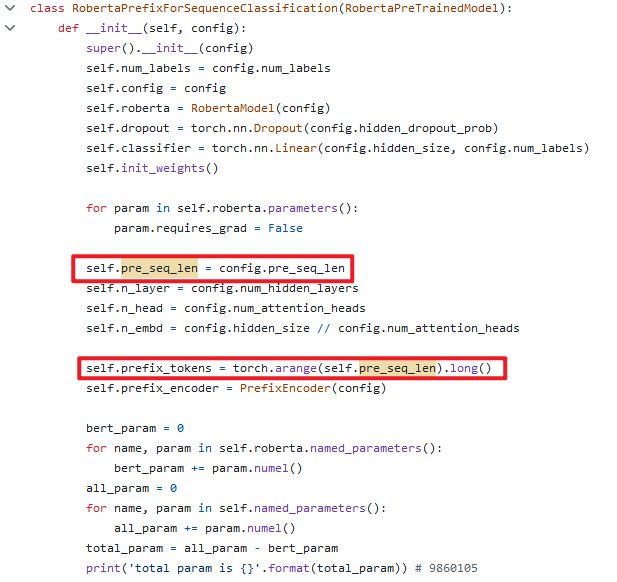
RobertaPrefixForSequenceClassification类,是针对序列分类下游任务的。
支持通过超参数,设置不同下游任务的前缀向量长度。
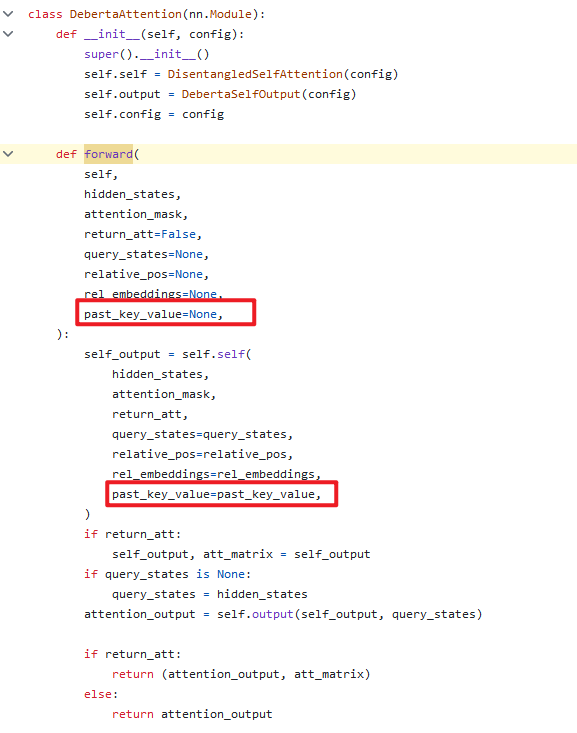
覆写Deberta的注意力层,支持在Deberta各注意力层都增加了前缀向量:
最后,在train方法中,将上述对模型结构的改进串联起来:
- 创建前缀向量编码器对象,根据本下游任务指定的提示长度,生成前缀向量。
- 前向传播时,将前缀向量传入本下游任务对应的各注意力层,实现不同层都能提取到前缀向量特征。
4.Experiments(实验结果)
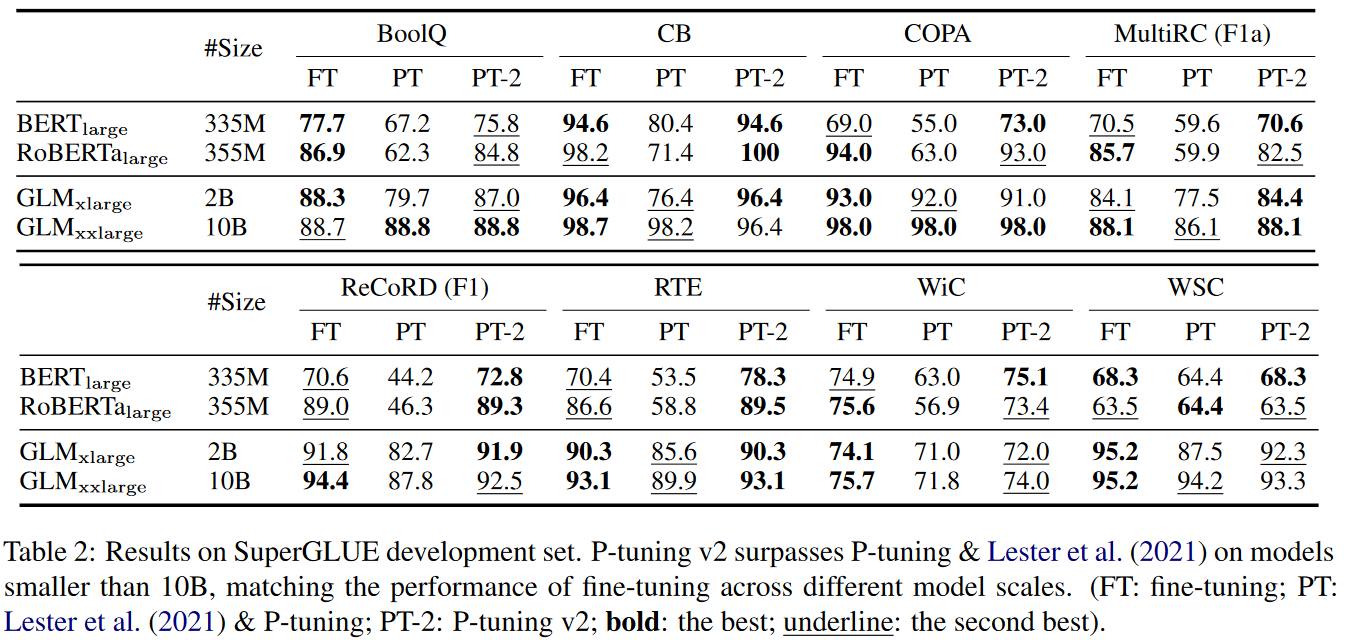
(1)实验结果1:Across Scales
针对不同规模的模型,P-Tuning v2的微调效果比较稳定。
- 在四种参数小于10B的模型上,P-Tuning v1微调效果远低于P-Tuning v2微调效果,P-Tuning v2微调效果与Fine Tuning相当。
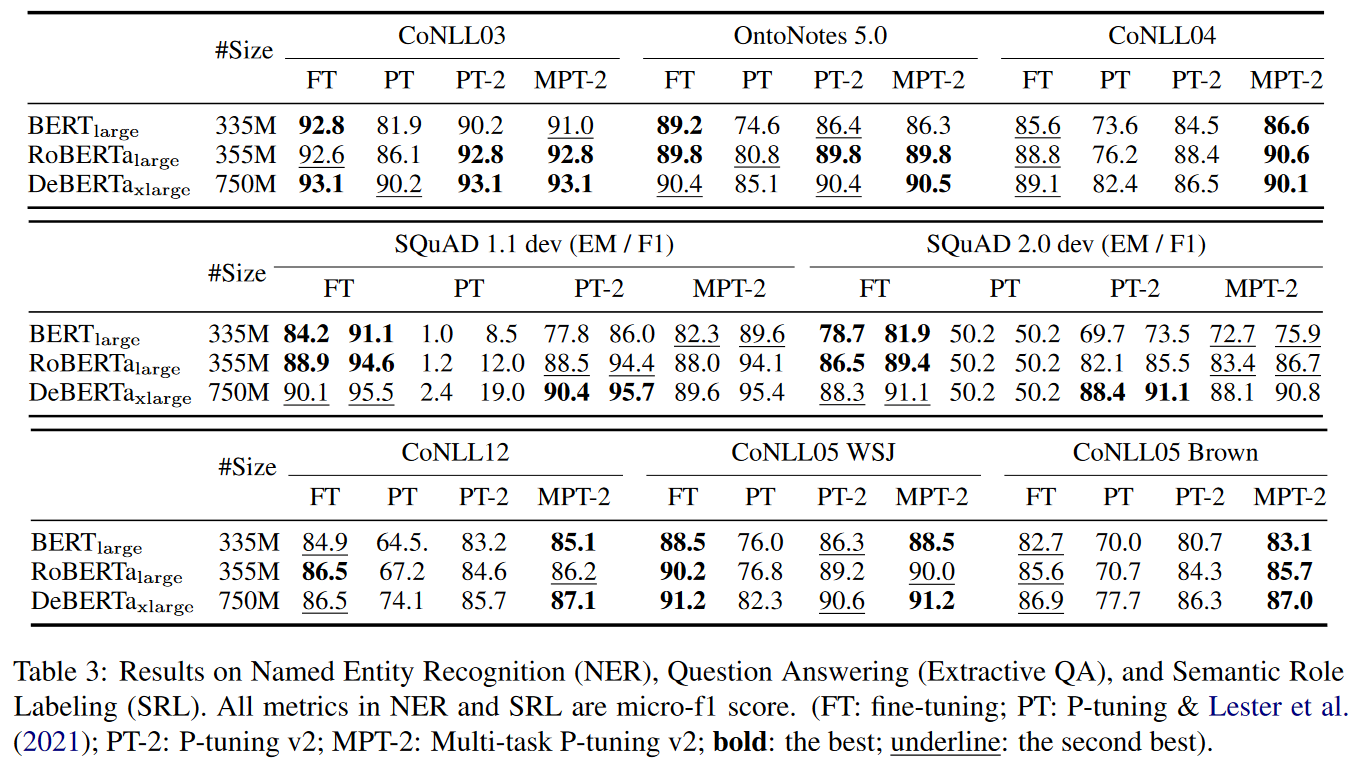
(2)实验结果2:Across Tasks
- 在CoNLL03、OntoNotes5.0、CoNLL04、SQuAD1.1dev、SQuAD2.0dev、CoNLL12、CoNLL05 WSJ、CoNLL05 Brown八种下游任务中,P-Tuning v1微调效果远低于P-Tuning v2微调效果,P-Tuning v2微调效果与Fine Tuning相当。
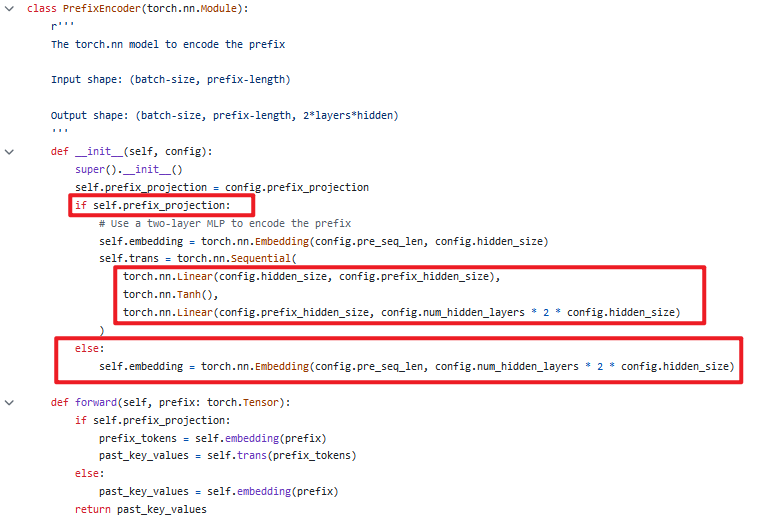
(3)其它重要发现:实现Prompt Encoder的神经网络结构的选择技巧
- 在P-Tuning v1中,采用LSTM+MLP或MLP,其中MLP采用2层线性层、ReLU作为激活函数。
- 在P-Tuning v2中,通过超参数针对不同下游任务选择不同神经网络,其中MLP的一种实现可以采用2层线性层、tanh作为激活函数。
5.总结
从上述论文解读中,我们收获了如下技术观点:
- P-Tuning v1的局限性:不同的下游任务、不同规模的模型,微调结果不稳定。
- P-Tuning v2的核心思想:修改模型结构,在各层注意力层增加前缀处理器网络以抵消小模型对前缀向量特征提取不足的局限,支持不同下游任务选择不同前缀提示长度、选择不同前缀编码器神经网络结构。
论文链接:https://arxiv.org/pdf/2110.07602