模型是智能体的"大脑”,帮助智能体实现复杂的自然语言交互和精准的推理决策。
本文为小伙伴介绍AgentScope中模型的部署和调用。
1.AgentScope模型服务
1.1.支持的模型
构建一个多智能体系统,需要根据任务的复杂性和不同子任务的专业领域,用到多种类型的模型和不同厂商的模型。
从模型类型看,多智能体系统可能需要综合运用大语言模型和多模态模型:
- 大语言模型:用于处理复杂的语言任务,促进智能体之间的交流和任务指示的解释。
- 多模态模型:处理图像、视频和语音等多种信息,帮助智能体理解和响应非文本输入。
从厂商看,多智能体系统针对不同下游任务可能选择不同厂商的模型:
- OpenAI:在推理和任务分解上可能需要调用OpenAI的模型,以获得更好的任务分解效果。
- Qwen:在多模态相关任务上可能需要调用QwenVL,以平衡推理成本和推理性能。
基于上述使用场景,AgentScope内置了以下模型服务API,支撑自然语言、多模态等各类任务的应用。
- OpenAI API:对话(Chat)、图片生成(DALL-E)和文本嵌入(Embedding)。
- DashScope API:对话(Chat)、图片生成(Image Synthesis)和文本嵌入(Text Embedding)。
- Gemini API:对话(Chat)和嵌入(Embedding)。
- ZhipuAi API:对话(Chat)和嵌入(Embedding)。
- Ollama API:对话(Chat)、嵌入(Embedding)和生成(Generation)。
- LiteLLM API:对话(Chat),兼容多种模型的API。
- Post请求API:基于Post请求实现的模型推理服务,包括Huggingface/ModelScope Inference API和各种符合Post请求格式的API。
1.2.模型服务
(1)模型服务集成的难点
多智能体系统需要集成多种类型的模型和不同厂商的模型,但不同模型提供的API风格迥异,因此多智能体系统的模型服务层面临多适配的难点:
- API风格差异:不同的模型服务由不同的团队或厂家开发,采用不同的设计理念和技术栈,API的风格差异大,如参数命名、请求格式、响应结构等。
- 功能特性差异:不同的模型服务专注于不同的功能或应用场景,需要根据功能需求来设计API。例如,一些模型专注于文本生成,而另一些可能专注于图像识别。
- 性能模式差异:不同的模型服务可能针对不同的性能要求进行优化。例如,一些模型可能需要更快的响应时间,而另一些可能需要处理更大规模的数据。这些性能差异可能导致API设计上的不同。
- 安全性和权限管理差异:不同的模型服务可能有不同的安全要求和权限管理机制。例如,一些服务可能需要更复杂的认证流程,而另一些可能提供更细粒度的访问控制。这些安全差异也会影响API的设计。
- 版本迭代导致的差异:模型服务版本迭代和更新的过程中,API可能会产生变化,这导致不同版本的API之间存在差异。
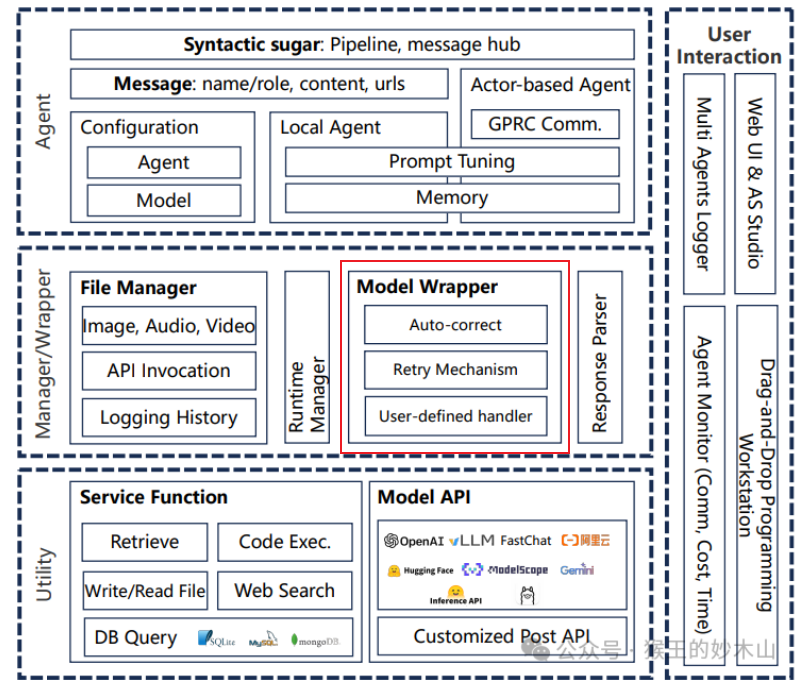
(2) AgentScope模型服务的解耦设计
AgentScope通过解耦设计,让模型的集成和维护变得灵活、简单:
- 统一的接口抽象:AgentScope定义了一个统一的接口抽象,即
ModelWrapper基类。所有的模型服务API都必须实现这个基类,从而确保了接口的一致性。这样,无论底层API如何变化,上层的应用代码都可以保持不变。 - 模型配置的灵活性:AgentScope允许用户通过模型配置来指定使用的模型服务。这些配置可以是字典、字典列表,或者是指向模型配置文件的路径。这种灵活性使得用户可以轻松地切换不同的模型服务,而不需要修改代码。
- 子类化和多态:AgentScope通过子类化和多态来支持不同的模型服务API。每个模型服务都有一个对应的
ModelWrapper子类,这些子类实现了与特定模型服务交互的具体逻辑。当用户通过配置指定使用某个模型服务时,AgentScope会动态地创建相应的ModelWrapper子类实例。 - 自定义模型包装器:AgentScope允许开发者自定义自己的模型包装器。开发者可以通过继承
ModelWrapperBase类并实现必要的方法来创建自定义的ModelWrapper子类。这样,即使AgentScope原生不支持某个模型服务,开发者也可以通过自定义包装器来实现支持。 - 脚本和工具的支持:AgentScope提供了一些脚本来帮助开发者快速搭建和部署模型服务。这些脚本和工具可以简化部署过程,使得开发者可以更容易地集成不同的模型服务。
(3)AgentScope Model Wrapper解耦设计的优势
- 易用性:用户不需要了解模型服务的具体实现,只需通过配置和统一的接口来使用模型。
- 灵活性:如果需要更换模型服务,用户只需要修改配置文件,而不需要修改调用模型的代码。
- 可维护性:模型服务的更新和维护在
ModelWrapper内部进行,无论底层模型服务如何变化,只要ModelWrapper接口保持不变,用户代码就不需要修改。
2.搭建自己的模型服务
在上一篇“AgentScope解读之概述”中,我们已经尝试过用AgentScope的API快速构建一套模型服务。
如果想使用已有的本地模型搭建自己的模型服务,如何操作呢?下面我们就动手实操一下。
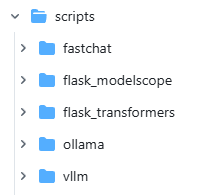
AgentScope内置了一些脚本来帮助开发者快速搭建自己的模型服务,在AgentScope的scripts目录下,包括:
- CPU推理引擎ollama
- 基于Flask + Transformers的模型服务
- 基于Flask + ModelScope的模型服务
- FastChat推理引擎
- vllm推理引擎
我们以vllm为例,来搭建一套本地模型服务。
STEP1.安装vllm
在python环境中安装vllm,可通过2种方式:
- pip直接安装:
| |
- 从源码编译安装(如果pip安装遇到问题):
| |
STEP2.启动大模型
- 本示例使用Llama模型,从 ModelScope 平台下载模型文件,上传到服务器"meta-llama/Llama-2-7b-chat-hf"目录下。
- 直接使用AgentScope提供脚本,命令如下:
| |
STEP3.AgentScope的模型配置
在AgentScope中,模型的配置是通过model_configs参数来指定的。
用户通过提供模型配置来指定要使用的模型。这些配置可以是字典、字典列表,或者是指向模型配置文件的路径。
模型配置中包含了模型的类型(
model_type)、名称(model_name)、API密钥(api_key)、组织名称(organization)以及其他可能的参数(如生成参数generate_args)。在vllm/model_config.json中,配置模型服务信息:
| |
STEP4.初始化AgentScope模型服务
- 使用agentscope.init初始化模型服务,模型配置使用上一步配好的文件。
- 然后就可以使用该模型服务创建agent去执行任务了。
| |
3.总结
本文要点如下:
- AgentScope内置支持多种模型服务API,包括OpenAI、DashScope、Gemini、ZhipuAi、Ollama、LiteLLM和Post请求API等。
- AgentScope通过
ModelWrapper实现模型的部署和调用解耦,实现对不同模型的灵活部署和调用。 - AgentScope支持自定义模型服务,并内置了服务部署脚本。
参考:https://arxiv.org/pdf/2402.14034