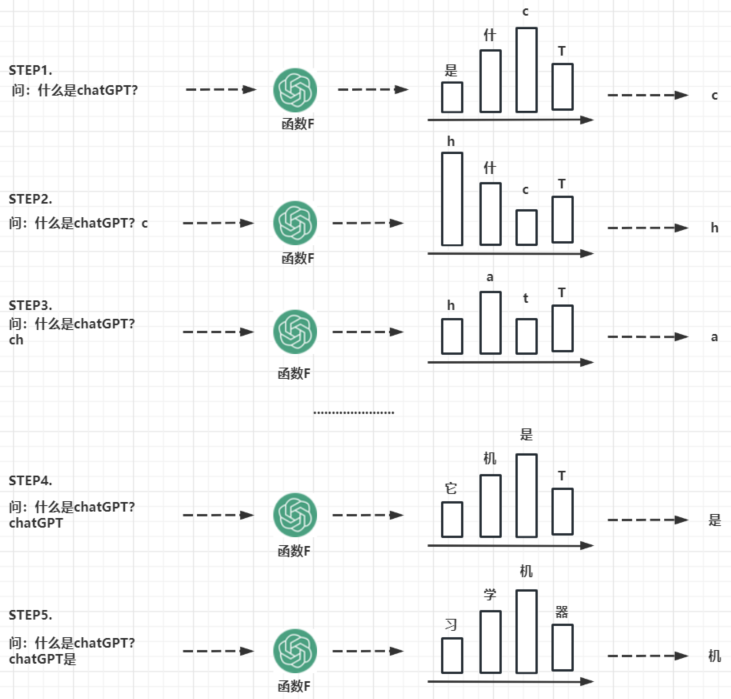
大家都在说chatGPT的本质是成语接龙——基于下一个词出现的概率,生成完整的句子,那么如何实现呢?
今天我们来手撸一个上古GPT,理解一下其中的基本原理。
1.语言模型简介
1.1.什么是语言模型
语言模型是一个用来估计文本概率分布的数学模型。通俗的说,你给它一个词,它能告诉你这个词之后通常大概率会接什么词。
写这篇文章的时候,笔者拉了个人类做测试——我说一个词,他凭直觉补全他这句话:
- 我说:孙悟。他答:孙悟空
- 我说:哪吒。他答:哪吒三太子
- 我说:白龙马。他答:白龙马蹄朝西
- 我说:猪八戒。他答:猪八戒背媳妇
你看,这就是人脑中隐含了一个语言模型,直觉并不是直觉,而是一种文本概率分布。
GPT家族(如:chatGPT、GPT-4)、BERT家族(如:MT-DNN、ERNIE),都是语言模型中的一种。
除了GPT、BERT这些新一代的语言模型,古早的语言模型还有N-Gram、RNN、LSTM、GRU等。
但是,无论是新同志,还是老同志,它们作为语言模型的初心不会变——估计文本概率分布。
1.2.语言模型分类
1.2.1.基于规则的语言模型
1970年,出现基于规则的语言模型。它通过语法树,将人类语言语法的规则描述出来。比如下面描述的最简单的语法树:
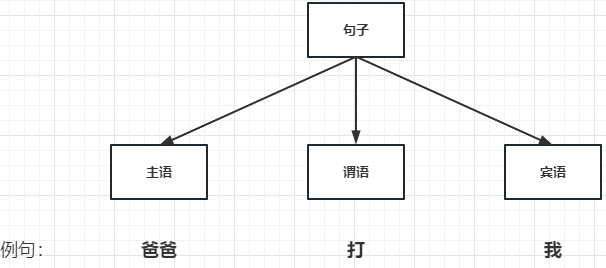
很显然,人类语言的规则复杂且会变化,这种基于规则的语言模型过于死板,不太可能有很好的效果。
1.2.2.基于概率的语言模型
1990年,出现基于数据驱动的统计概率语言模型。
这里不得不敬仰一下语音识别和自然语言处理专家——贾里尼克(Frederek Jelinek)。这位大神学术上极其严谨和务实,在IBM期间极度厌恶夸夸其谈的语言学家,曾经抛出了那句:“我每开除一名语言学家,我的语音识别系统错误率就降低一个百分点"的名言。

著名的贾里尼克假设(一个句子是否合理,就看看它的可能性大小如何,至于可能性就用概率来衡量)奠定了基于概率的语言模型。
举个例子:小美同学听到一句英文The apple and 「pear」 salad is delicious.,由于pear和pair发音很类似,那么到底是在这个句子中是pear还是pair呢?按照贾里尼克假设,pear显然可能性更多,或者说概率更大。
我们进一步将这里再展开一点:假设Y是一个有意义的句子,由一连串特定顺序排列的词X1、X2、X3…Xn组成。如何求Y在自然语言中出现的可能性呢?
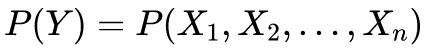
首先,根据条件概率进行转换:
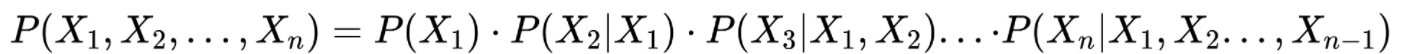
然后,根据马尔科夫假设进一步简化:
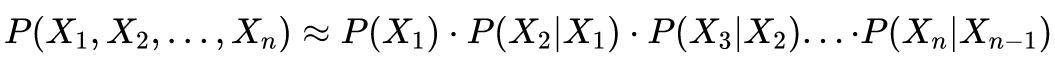
最终,就可以得到一个简化的语言模型Bi-Gram:每个词称为1个Gram,当前词由前一个词决定。
这就是笔者在《【ChatGPT】ChatGPT学习笔记2-不是什么?是什么?有何方向?》中提到的GPT基础原理:
1.2.3.基于深度学习的语言模型
基于深度学习的语言模型的侧重点是学习工具,即强调使用神经网络进行学习。而基于概率的语言模型的侧重点是数据,即强调从数据中寻找规律。
因此,基于深度学习的语言模型没有突破基于概率的核心思想。
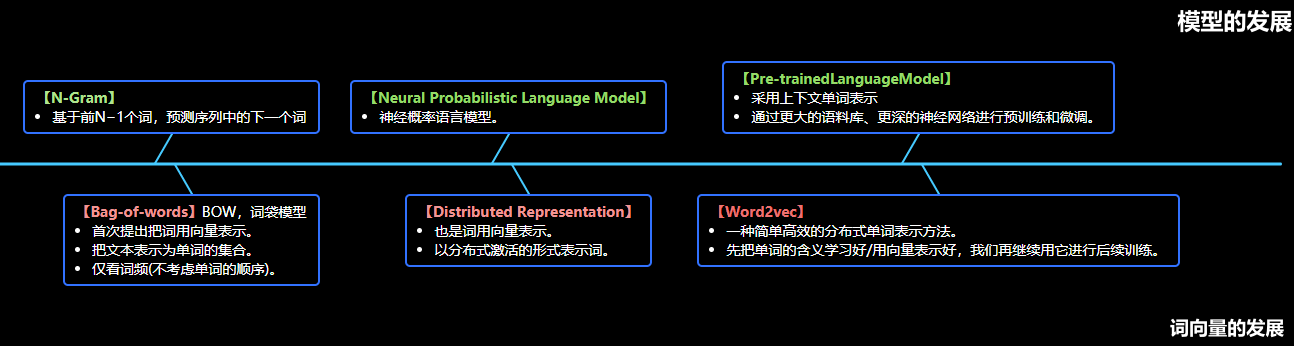
1.3.语言模型的关键里程碑
从模型本身的发展看:
- N-Gram:基于前N−1个词,预测序列中的下一个词
- Neural Probabilistic Language Model:神经概率语言模型。
- Pre-trained Language Model:通过更大的语料库、更深的神经网络进行预训练和微调。
从词向量表示的发展看:
- Bag-of-words:BOW,词袋模型。首次提出把词用向量表示,把文本表示为单词的集合,仅看词频(不考虑单词的顺序)。
- Distributed Representation:以分布式激活的形式表示词,也是词用向量表示。
- Word2vec:先把单词的含义学习好、用向量表示好,我们再继续用它进行后续训练。
2.上古语言模型N-Gram
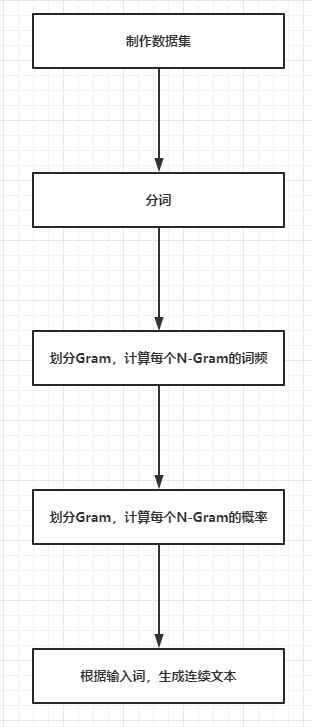
2.1.五步实现N-Gram
- 制作数据集
- 分词
- 计算每个N-Gram的词频
- 计算每个N-Gram的概率
- 根据输入词,生成连续文本
2.2.制作数据集
- 我们录入了三首唐诗作为数据集。实战中会录入更多的数据。
- 看一下代码:

- 看一下结果:

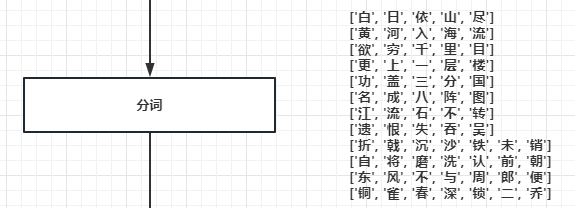
2.3.分词
N-Gram模型会将数据集中每一条语句,拆分成N个词。每个词就是一个Gram。
分词本身不是N-Gram的重点,因此本文没有使用JieBa等分词三方件,直接按照单字来拆分。
分词时有个细节是子词,为了解决错别字等问题。
看一下代码:

- 看一下结果:
2.4.划分N-Gram,计算词频
- 我们会根据N的具体数值,去计算N个字之后紧跟的字出现的词频。
- 看一下代码:
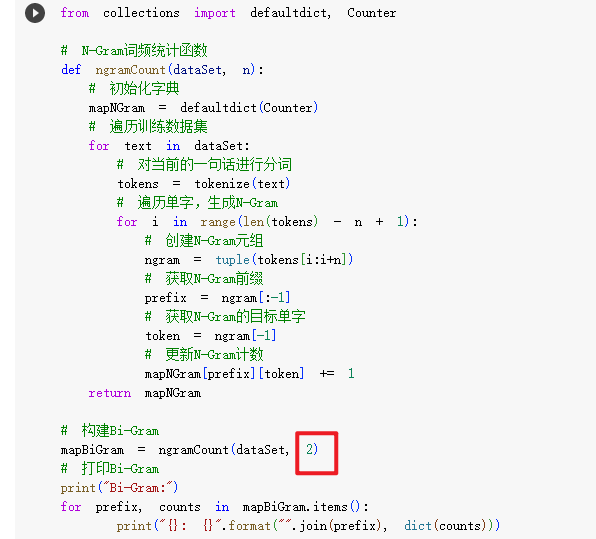
- 看一下结果(当N=2时,就是看每个字后紧跟的字出现的词频):

- 看一下结果(当N=3时,就是看每两个字后紧跟的字出现的词频):
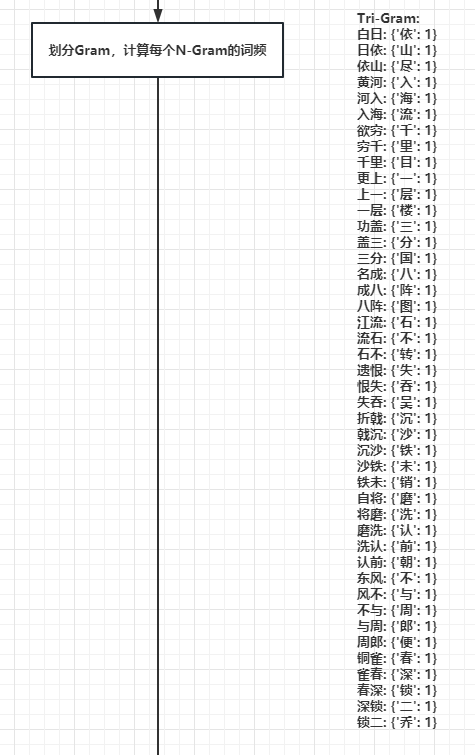
2.5.进一步计算概率
- 我们会进一步计算N个字之后紧跟的字出现的概率。
- 看一下代码:

- 看一下结果(当N=2时,就是看每个字后紧跟的字出现的词频):

- 看一下结果(当N=3时,就是看每两个字后紧跟的字出现的词频):

- 走到这里,我们会有一个重要发现:当N越大,后面紧跟的字的概率越趋于确定!
2.6.使用N-Gram模型,生成文本
- 当我们有了N-Gram模型,就可以根据输入词,预测生成完整的文本了。
- 看一下代码:
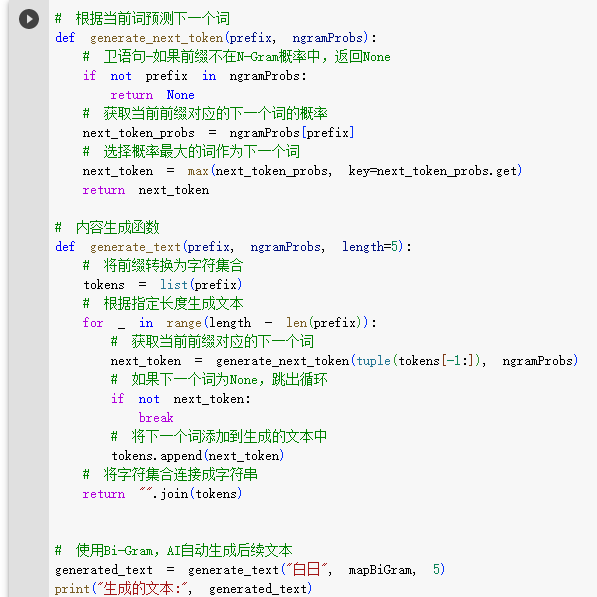
- 看一下结果:

3.总结
- 语言模型本质是一个文本概率统计模型
- 语言模型分为:基于规则的语言模型、基于概率的语言模型、基于深度学习的语言模型
- N-Gram是最古老的语言模型,通过分词,统计出每N-1个词后紧跟的词的概率,进而形成了文本概率统计模型。
- N-Gram的理论基础是: