人类的科学发展就是这样:每个十年百年就有一个天才振臂一呼,用一个理论解决那个时代的一个问题,同时成为下一个十年百年的天才理论的基石。
目前炙手可热的Transformer既是如此,LSTM、Word2Vec等是它的基石,共同构筑了现在的大语言模型的关键部件和理论基础。
之前发了一个朋友圈,将对大语言模型影响深远的论文,梳理了三条脉络:
- LSTM:在1997年那会儿解决了AI的记忆问题。
- Word2Vec:在2013~2014年解决了将词转换为向量,将"文字游戏"转换为了高维向量空间中的"数学游戏”。
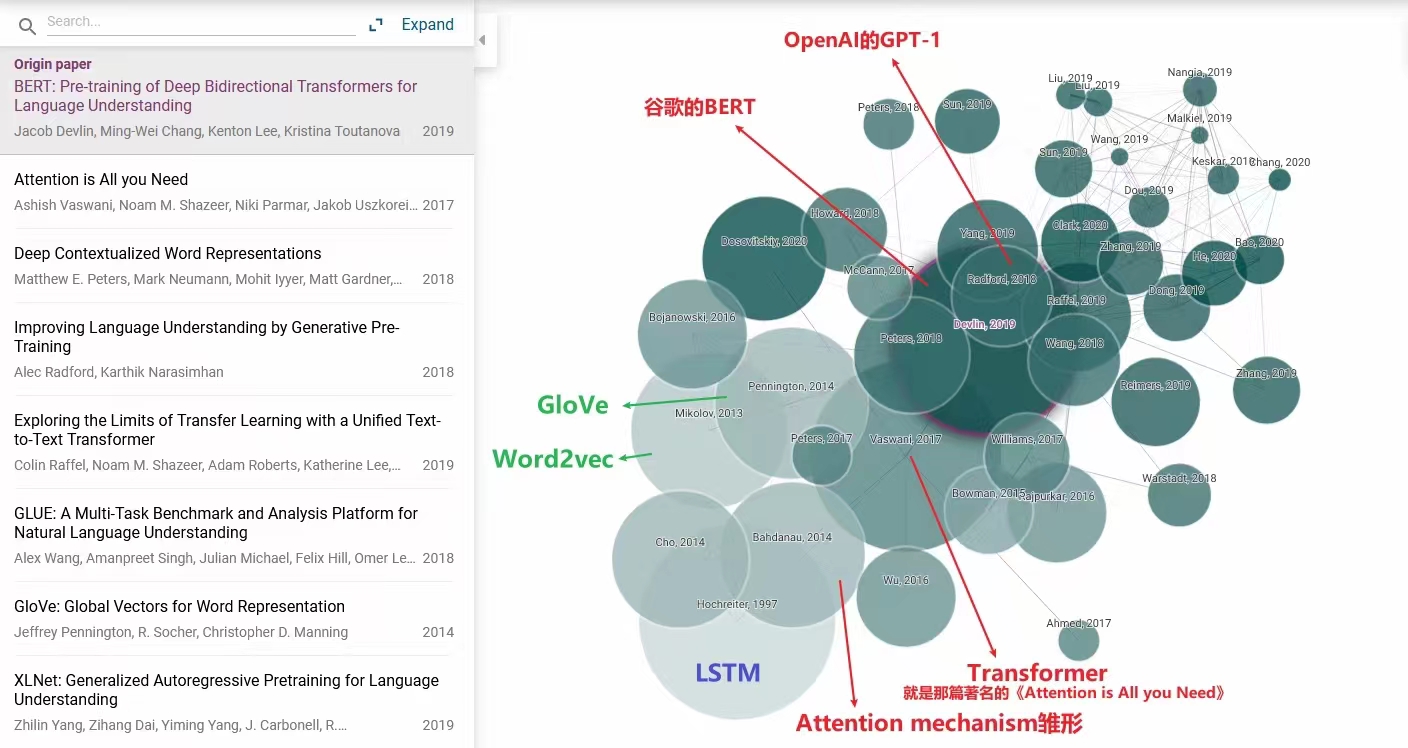
- Transformer:2014年出现了注意力机制雏形,2017年那篇著名的《Attention is All you Need》引出的Transformer,随后是OpenAI2018年的GPT-1、Google2019的BERT。
本文重点阐述第2条技术线:Word2Vec涉及的技术——词的向量化,这也是大语言模型的关键部件之一。
1.什么是表示学习?
我们先看一下表示学习的定义:
- 表示学习:Representation Learning,通过学习算法自动地从原始数据中学习到一种数据表达形式。
- 表示学习的目标是将输入的数据转换到具有良好表现能力的特征空间中。
- 特征空间中的数据有可分性、可解释性、可推理性。
我们来解读一下上述这段话:
- 数据的可表示性,是连接主义的哲学基础:
- 我们知道,人类彼此的沟通介质是:文字、图像、视频、语音等。这些介质的本质是数据。
- 我们还知道,从数据中寻找规律,是连接主义的哲学基础。
- 我们还知道,可以被人类大脑理解的文字、图像、视频等数据,人工智能能理解吗?不能。
- 人工智能无法理解这些数据,人工智能就无法从数据中寻找规律——因此,数据的可表示性,是连接主义的哲学基础。
- 向量化是数据可表示的一种实现:
- 向量化,可以让人工智能理解人类才能理解的数据。
- 向量化,只是数据可表示的一种实现,当然可以有其它的实现方式。
- 如:笔者前一篇《【chatGPT】学习笔记6-手撸一个上古GPT》中实现的N-Gram算法,并未对人类语言向量化,也让人工智能具备理解人类语言以及语言概率的能力。
- 向量化,依然是目前数据可表示的若干种实现中最好的一种。
- 基于N-Gram的人工智能,能力很弱。它的智能停留在人类语言的表面,它并不理解语义。
- 比如:“我去!“这个句子,基于N-Gram的人工智能无法识别,这句话到底想表达"我艹”,还是想表达"我要去某个地方”。
上述对表示学习的解读还是挺抽象。没关系,后文有形象的例子,各位小伙伴可以先看完后文,再回头看这一段,加深对表示学习的理论理解。
2.什么是向量?什么是嵌入?
(1)向量
在NLP领域,无论语言模型的大小,都必须将词先表达为向量,词向量就是语言模型的输入。
在CV领域,无论视觉模型的大小,也必须将图像先表达为向量。
将文字、图像、视频、音频等数据向量化,本质是**将"人类可理解的数据问题"转换为"机器可理解的机器学习问题”**。
我们来看一个向量化的例子:
- 人类小孩儿第一次看到苹果,人类小孩儿是怎么记住这种东西就是苹果呢?

- 人类小孩儿会从不同维度描述苹果的特征(如:纹理、颜色、形状、大小等)
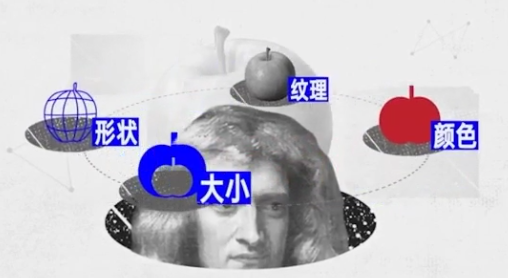
- 假设人类小孩大脑的工作机制,是将不同维度的特征用数字表达并存储,这些维度的特征值就是向量了。

- 当人类小孩看到新的苹果,大脑也会将新苹果的特征提取为向量。
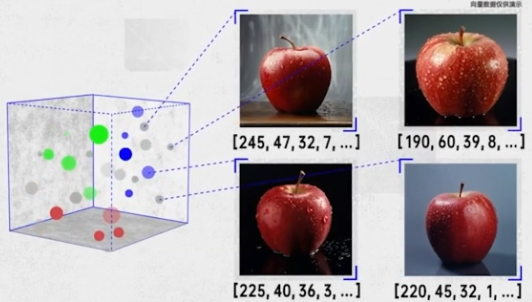
- 大苹果、小苹果,从颜色、大小、形状、纹理等等维度是很相似的,显然,把这些苹果抽象成多个向量,这些向量在向量空间中的距离肯定是很近的。
- 这就是信息向量化,词的向量化就是信息向量化的一种。
上述例子,来自于一段腾讯云介绍向量数据库的视频,各位小伙伴可以通过视频,看到更多形象化理解向量的例子:
(2)嵌入
先看一下嵌入的学术概念:
- 嵌入:Embedding,表示学习的一种形式,用于将高维数据映射到低维空间。嵌入包括:
- 词嵌入
- 图像嵌入
- ……
这里以图像嵌入的一种经典算法t-SNE(t-Distributed Stochastic Neighbor Embedding)为例:
- 图像嵌入的第一阶段是将图像转换为高维向量。
- 图像嵌入的第二阶段是将高维向量映射到低维向量,但是要保证高维向量中邻近的点,在低维空间中也有相同的距离关系。
嵌入本身是一个很抽象的术语,但我们可以简单地认为嵌入就是向量化的过程。
对于嵌入,最关键的信息只有一个:高维映射到低维。
什么是高维向量?什么是低维向量?为什么要从高维映射到低维?
这些问题的有趣之处,和人类的学习过程非常相似:
有一日未死之身,则有一日未闻之道:
- 人类开始学习一门新知识,越学越觉得这个知识领域博大精深。这是人类学习的第一阶段——"把书读厚"。
- 在嵌入过程中,也就是把信息向量化过程中,显然是把一个信息用更高维度的向量去描述,信息越准确。
- 比如:小时候练习看图说话,老师会鼓励小朋友把图上看到的东西从更多角度去描绘出来,这些角度就是向量的维度。
- 再比如:一个哲学思想,不同流派的哲学家会从不同角度、不同立场去阐述、论证和思辨,这些角度、立场也等效于向量的维度。
读书之道,愈进愈简,百卷如一页:
- 人类学习新知识到了一个阶段,会出现顿悟——发现、归纳各个知识点的内在联系。这是人类学习的第二阶段——"把书读薄"。
- 比如:杨过的重剑无锋,大巧不工。比如:老子的大道至简,有言无言。
- 在嵌入过程中,也有类似的过程,虽然单个高维向量有丰富的表达,但是多个高维向量存在某些内在联系,把它们降低为低维向量,不仅抓住了信息的本质,而且更加精炼、大道至简。
这就是嵌入的核心思想——将高维向量降低成低维向量。

3.什么是词向量?什么是词嵌入?
先来看词向量、词嵌入的学术概念:
- 词向量的定义:将词语转换成对应数值向量的表达形式,便于计算机读取和运算。
- 词向量的数学表达:将字典D中的任意词w,设定固定长度的实值向量V(w)。其中:V(w)就是词向量,m表示词向量长度。
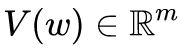
- 词嵌入:Word Embedding,将词映射到向量空间,形成词向量的过程和方法,就是词嵌入。
再来看一个经典的例子:
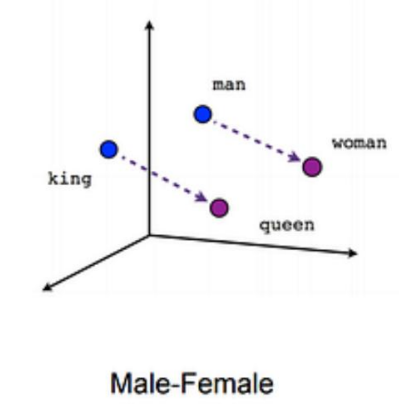
- 对男人、女人、国王、皇后开展词嵌入,它们变成了四个向量,存在与三维的向量空间中。
- 假设词嵌入的具体代码实现没有问题,那么男人和国王的向量距离应该很近,女人和皇后的向量距离应该很近。
- 这样,对人类的文字开展词嵌入后,有两个关键的输出:
- 词以向量的形式存在。
- 有关联的词对应的向量的距离也会很小(如:对两个词向量求余弦相似度)。
4.如何实现词嵌入?
词嵌入,或者说词的向量化过程分为两个阶段:
- 文本变为One-Hot编码。
- One-Hot编码变为低维词向量。
(1)One-Hot编码
One-Hot编码:One-Hot Representation,也叫独热编码。
比如:对于男、女两个词,One-Hot编码可以表示为:
- 男:[1, 0],女:[0, 1]
再比如:对于初一、初二、初三三个词,可以表示为:
- 初一:[1, 0, 0],初二:[0, 1, 0],初三:[0, 0, 1]
如果说One-Hot编码算得上广义的向量,那么它明显的缺点是:
- 过于稀疏:在各个维度上,只有1个维度是1,其它维度都是0。
(2)Distributed表示
Distributed表示:Distributed Representation,分布式表示,它是表示学习中的一种。
- Word2Vec、GloVe、fastText等都是其中一种具体实现。
分布式表示的核心思想是:
- 通过训练,将词典里每个单词转换为固定长度的低维向量。
- 这些向量之间可以通过余弦相似度之类的数学工具,表示向量之间的距离。语义越接近的向量之间,距离越近。
Distributed表示才算得上真正的向量,它明显的优点是:
- 从过于稀疏的One-Hot编码,变为了密集向量。
(3)Word2Vec,Distributed表示的一种实现
Word2Vec是Distributed表示的一种具体实现:
- Word2Vec将词汇表中的每个词表示成固定长度的向量。
- Word2Vec的核心思想本质是——近朱者赤,近墨者黑:
- 一个词可以根据它的的周边词,推测出自己的语义。
- 一个词也可以通过自己的语义,推测出它的周边词。
Word2Vec的实现算法有两种:
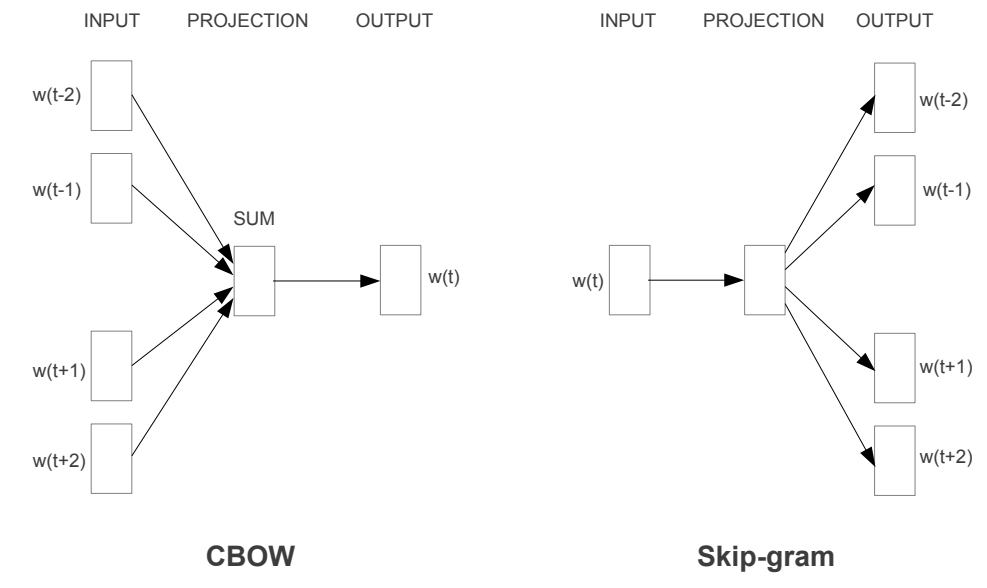
- CBOW:Continuous Bag of Words,连续词袋,输入是周围词,输出是中心词。
- Skip-Gram:跳字模型,输入是中心词,输出是周围词。
Word2Vec基于神经网络实现:
- 但,无论是CBOW,还是Skip-Gram,都属于浅层神经网络。
- 一说浅,显然就不那么高级。浅层神经网络的效果可以参考Word2Vec的原始论文:https://arxiv.org/pdf/1301.3781.pdf
5.代码实例:手撸Word2Vec
STEP1.构建语料库
- 首先,以四个句子作为训练语料
- 然后,形成词+索引的Map和索引+词的Map

STEP2.生成Skip-Gram数据
- 根据句子中的各个词,将相邻的词形成词对。
- 如:(小美,是)、(是,小美),(美女,小美),(小美,美女)等

STEP3.对Skip-Gram数据进行One-Hot编码
- 将STEP2的各个词对进行One-Hot编码

STEP4.定义Skip-Gram模型
- 我们复现出论文描述的神经网络结构
- 一个线性层学习出词向量
- 一个输出层验证学习到词向量作为中心词,是否能够预测出周围词。
看一下具体的代码实现:

STEP5.训练Skip-Gram模型
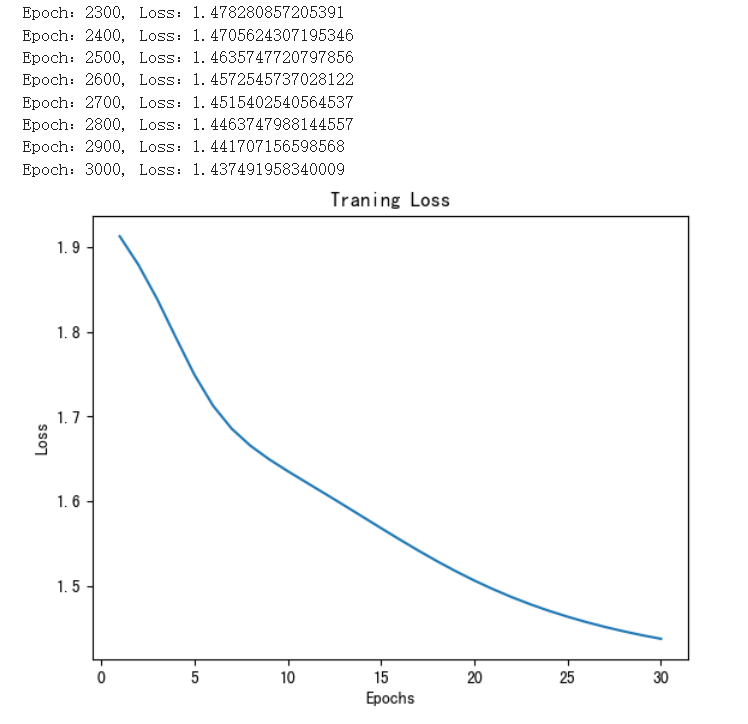
- 训练3000次,每一次都会从输出层触发反向传播,更新线性层的参数,最终确定本次学习到的词向量。

- 这是损失函数曲线,经过3000次的训练,损失逐渐降低。
STEP6.显示词向量
- 将词向量打印出来,并绘制在向量空间中
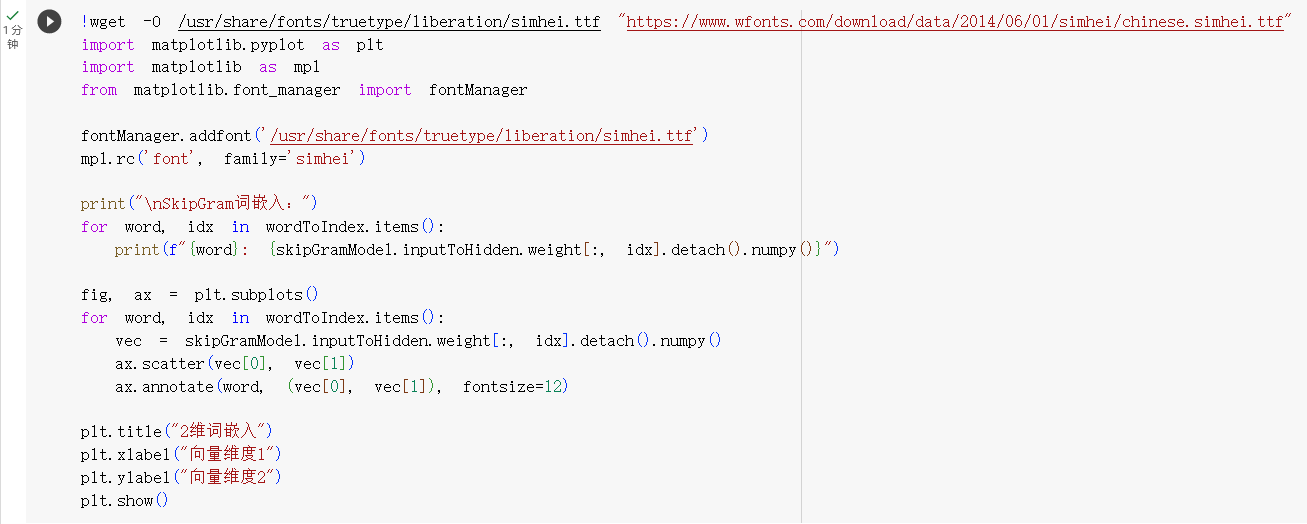
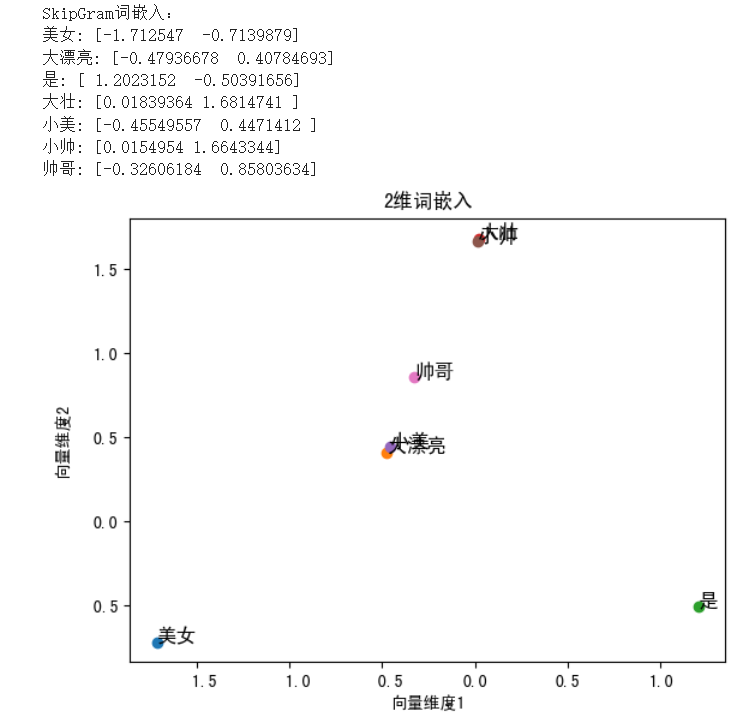
- 绘制出来的向量空间,结果如下:
- 小美和大漂亮的词向量分别为: [-0.45549557 0.4471412 ],[-0.47936678 0.40784693]
- 小帅和大壮的词向量分别为:[0.0154954 1.6643344],[0.01839364 1.6814741 ]
- 小美和大漂亮两个词关系密切,甚至重合,说明这两个向量有关联性。
- 小帅和大壮两个词也关系密切,甚至重合,说明这两个向量有关联性。
- 但,美女、帅哥两个词向量学习的不好。小美、大漂亮更接近于帅哥,出现了不一定斩男但是一定斩女的现象。。。
6.再看表示学习、嵌入
笔者在第5章以Word2Vec的Skip-Gram的代码实现,给大家阐述了词嵌入的实现过程和训练过程。
回头再来看1~4章出现的各种概念和理论,可以归纳词嵌入的几个关键知识点:
- 自然语言问题转换为数学问题:将文字向量化的本质是将信息转换为向量,所以文字的语义关系巧妙地转换为了向量距离的数学问题。
- 自动化的学习过程:获得文字的向量是一个自动化的过程,通过神经网络这种工具自动学习得到词向量。
- 词向量的降维技术:对于词嵌入,学界有很多种降维技术,Word2Vec的CBOW和Skip-Gram都是实现了降维的具体算法。
再看第1章的表示学习,我们可以重新理解一下表示学习的三个特性:
- 可分性:不相关的向量距离会很远,不相关的向量之间应该会有明显的分界线。这就体现了可分性——不同类别之间的向量样本应该有明显的边界或区别。
- 可解释性:为什么提到唐伯虎,人类会立刻联想到秋香?向量空间中相关的向量距离就会很近,这就体现了可解释性。
- 可推理性:给出小美,我们可以联想到大漂亮、帅哥,进而可能就会联想到小帅、大壮,说不定小美和小帅之间就一段故事,这就体现了可推理性。
写到这里,我们可以看到:
- 以Word2Vec为代表的词向量化技术极大地推进了语言模型的进步
- 词嵌入也成为了如今大语言模型GPT、LLama、Bert的核心组件之一。
在了解了词嵌入相关技术之后,我们下一步就来看大语言模型的另一个核心组件的起源:神经概率语言模型。