1.问题:词嵌入的局限性
在《【chatGPT】学习笔记7-词的向量化,大语言模型的关键部件》中,我们了解了词嵌入。
获取词向量后,在向量空间中可以获得每个词的向量表示,也可以通过向量了解词和词之间的语义关联性。
似乎,仅通过词嵌入就能解决很多NLP问题了,但词嵌入存在如下局限性:
- 词向量的静态性:Word2Vec,以及后续的GloVe,在训练完成后,学习到的词向量是不会再被更新的。
- 词向量的静态性决定了:
- 词嵌入无法应对多义词:1个词只有1个向量,无法表示多义词。
- 词嵌入无法应对未知词:没见过的词,显然Word2Vec不可能在向量空间中无中生有它对应的向量。
于是,神经概率语言模型NPLM横空出世。
2.对策:神经概率语言模型NPLM
(1)什么是神经概率语言模型?
科学家和大神们,很早就有了引入具有强大表示力和学习力的神经网络的想法。大致思想是:
- 输入海量语料,神经网络学习词语在不同上下文中的概率分布。
- 词最终还是会被向量化,只是这些词向量的学习过程成为神经网络的一部分,词向量表达的人类语言规律(词语、语义等)最终被记录到神经网络的参数中。
接下来,深度学习三巨头之一Bengio,在2003年推出了神作《A Neural Probabilistic Language Model》:
- NPLM:Neural Probabilistic Language Model,神经概率语言模型。NPLM包含输入层、隐藏层、输出层。
- 输入层:将单词映射到连续的词向量空间。
- 隐藏层:通过非线性激活函数学习单词间的复杂关系。
- 输出层:通过Softmax层产生下一个单词的概率分布。
论文链接:https://dl.acm.org/doi/pdf/10.5555/944919.944966
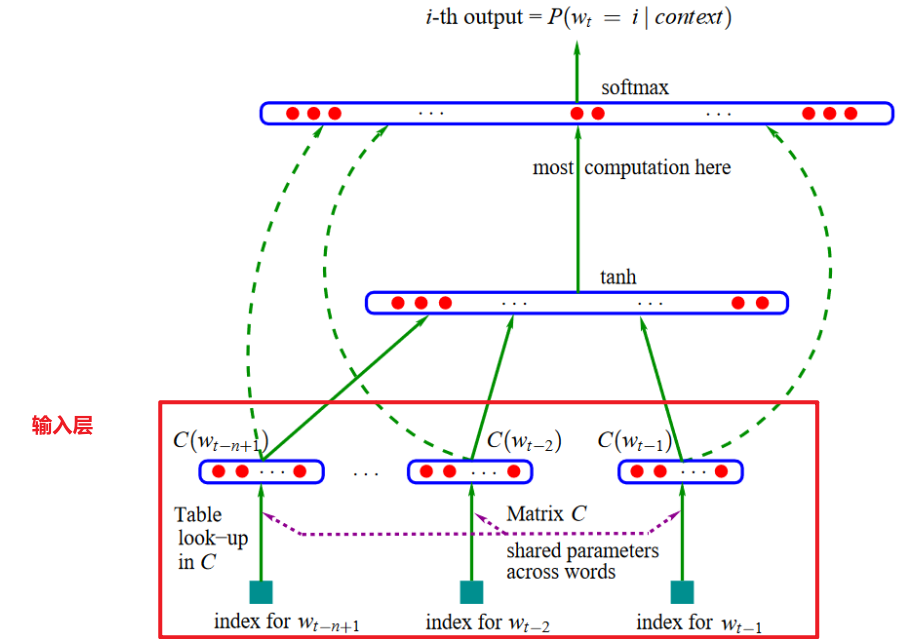
下图是Bengio论文中的阐述的神经概率语言模型的架构,后续NLP方向上的各种技术都是围绕这个架构进行各层的优化!
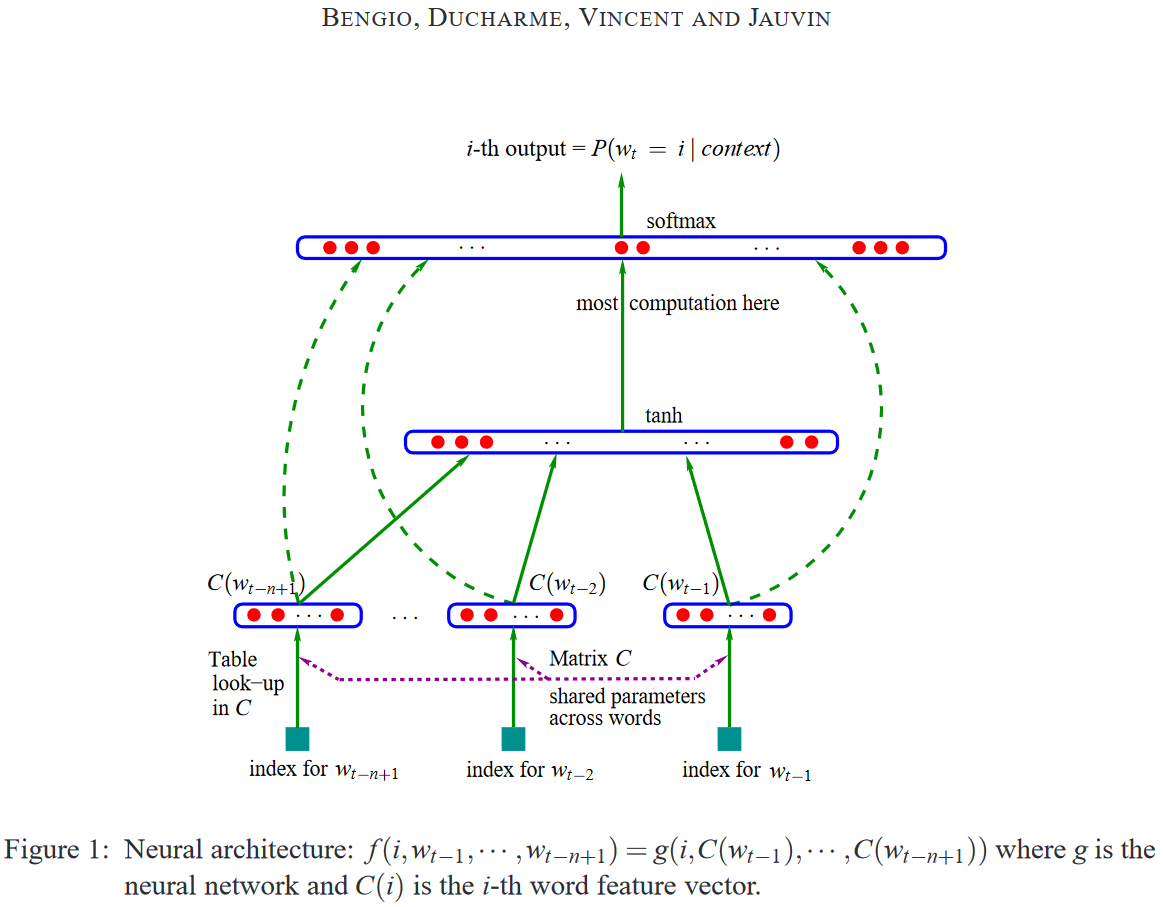
对上图进行细化,笔者标出了输入层、隐藏层、输出层:
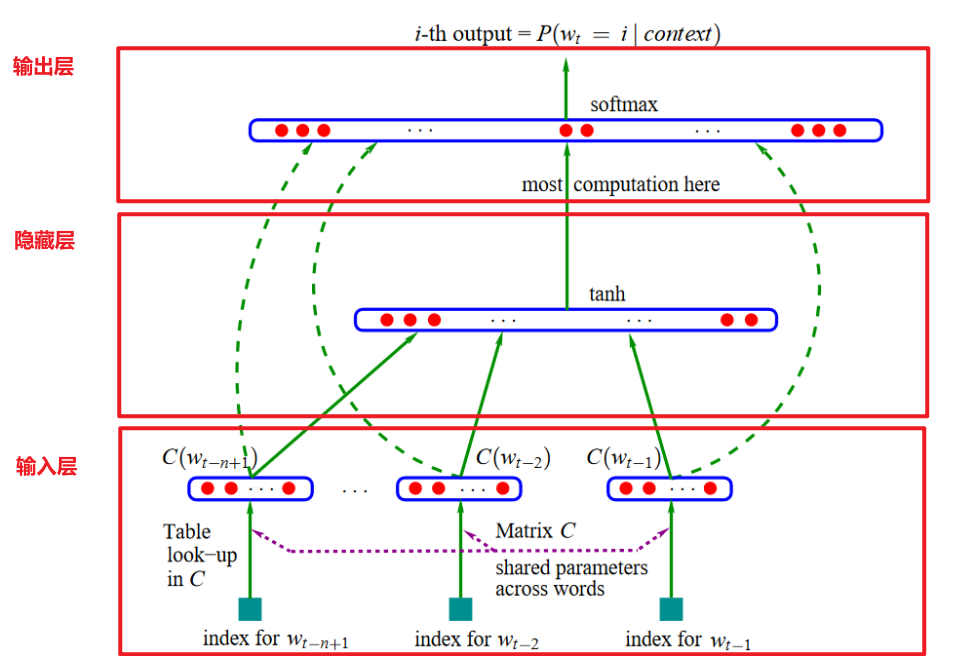
(2)输入层
- 输入层的职责:将输入的词,开展词嵌入,学习到词向量后存储在输入层。因此,输入层也可以叫嵌入层。
- 输入层的输入:词本身
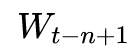
- 输入层的输出:词向量
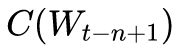
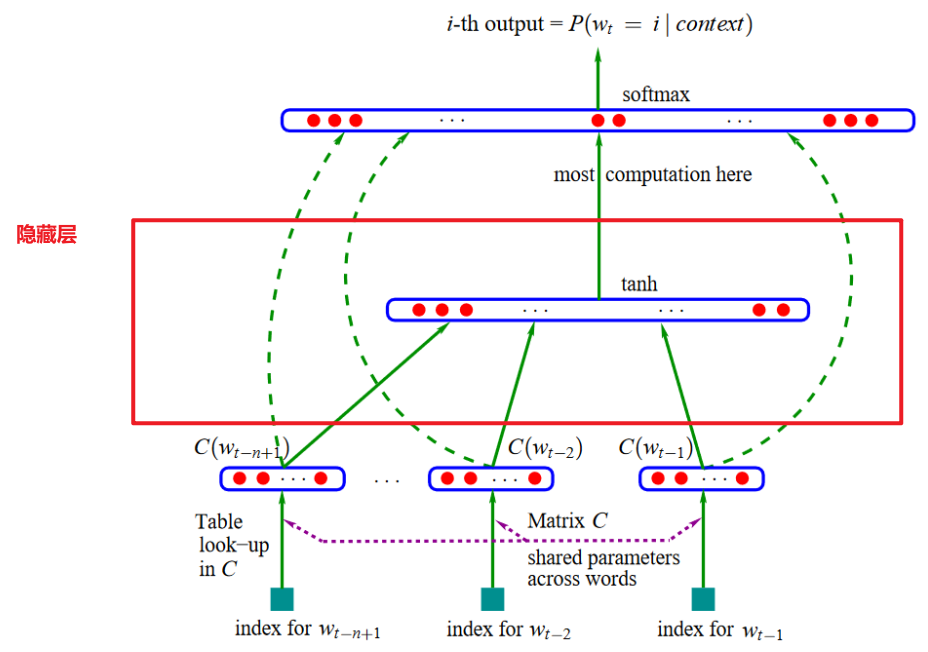
(3)隐藏层
- 隐藏层的职责:学习词与词之间的关系
- 隐藏层采用了非线性激活函数:采用非线性激活函数的本质是让神经网络的**“脑回路”**复杂起来(如:使用激活函数可以将线性层提升为非线性层)
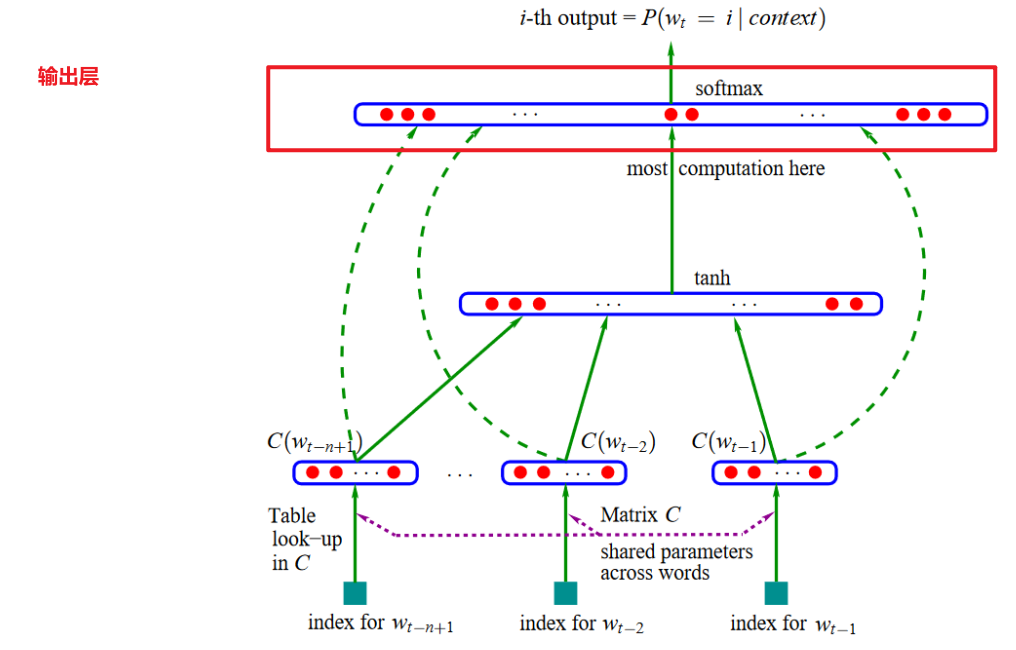
(4)输出层
- 输出层的职责:通过Softmax层,输出下个单词的概率分布
- Softmax:归一化,Softmax层的输入是各个词得到的分数,输出是将这些分数归一化到0~1的值域内。
(4)隐藏层的优化
- 神经网络似乎天生不擅长长序列问题,所以后续很多NLP发展的技术,都是在优化NPLM在长序列上的表现。
- 浅层网络无法捕捉文本中复杂的信息规律。
- 普通的深层神经网络也不能很好处理长距离的依赖关系。
- NPLM的巧妙之处在于:隐藏层可以使用任意的神经网络去替换。
- RNN、LSTM横空出世,在NLPM中长期霸榜:
- RNN,循环神经网络,这种特殊的神经网络结构,可以将网络的输出作为网络的输入,使得神经网络能够处理数据的同时保留了前世的记忆。
- LSTM,是RNN的经典代表作,很长一段时间作为NLP问题的SOTA(state of the art)模型
- 注意:被评为SOTA,而不是benchmark,或者baseline,是一种极高的荣誉。
3.代码:NPLM
接下来,进入代码环节。
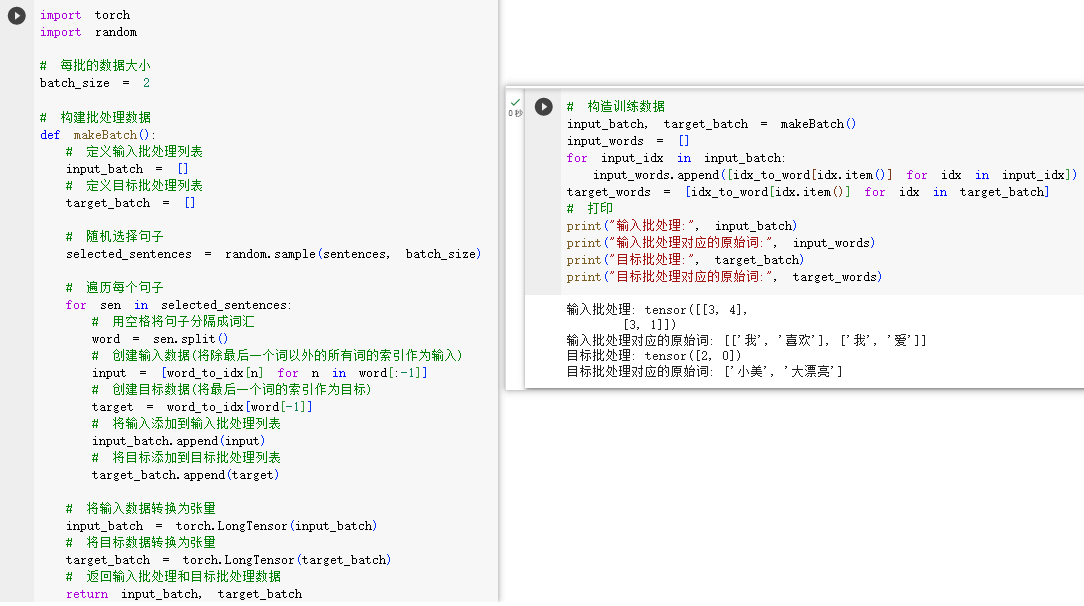
STEP1.1.构建数据集

STEP1.2.格式化训练数据
STEP2.构建NPLM网络

STEP3.训练NPLM网络
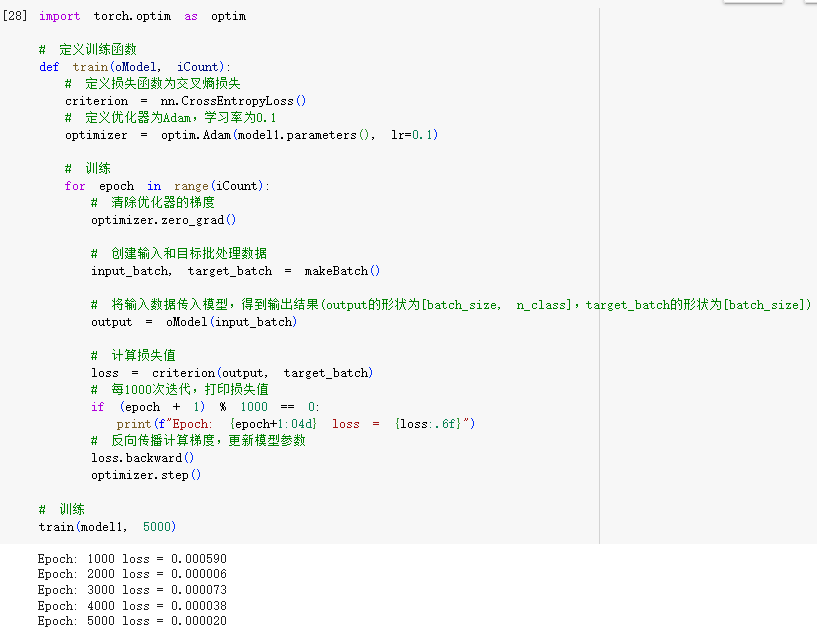
STEP4.测试NPLM
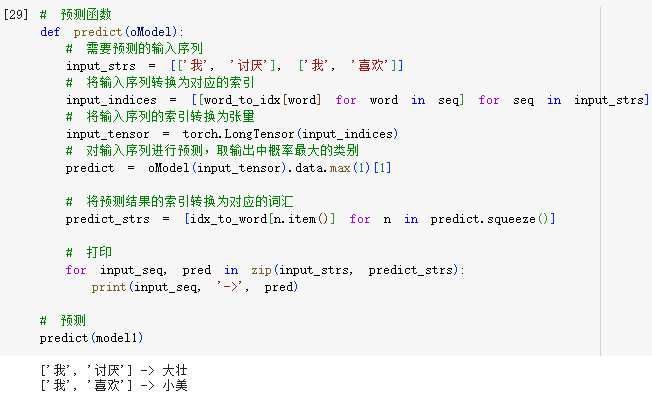
4.代码:NPLM优化
再使用RNN、LSTM优化NPLM架构。
STEP1.1.构建数据集
STEP1.2.格式化训练数据
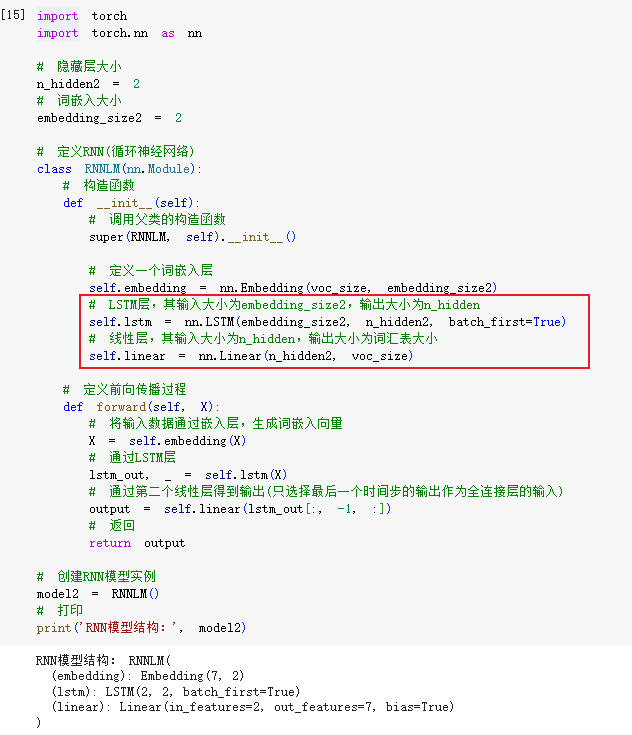
STEP2.构建NPLM网络
- 核心就是在此替换隐藏层和输出层
STEP3.训练NPLM网络

STEP4.测试NPLM

5.小结
最后,我们来做一些对比和小结:
- 从目标看:NPLM是解决词汇出现概率的问题,Word2Vec是解决如何将词转换为向量的问题。
- 从实现看:NPLM和Word2Vec都是基于神经网络的模型,但Word2Vec没有激活函数,属于利用了浅层神经网络。
- 从词向量看:NPLM中的词向量是神经网络的一部分,基于NPLM的目标,人类对它的训练是不会停止的,训练一次,词向量就会变化一次。而基于Word2Vec的目标,人类只会对它训练一次,训练好,词向量就固化不变了。
NPLM可以算作如今大语言模型的祖师爷了,在学界存在极高的地位和价值,后续很多年的RNN、LSTM都只能算作对NPLM的架构优化。
但,NPLM也存在历史局限性,于是才有了后来的大模型的关键部件Transformer,且听下回分解。