1.Seq2Seq,Transformer的雏形
1.1.为什么会出现Seq2Seq?
在神经概率语言模型NPLM出现后的很长一段时间,都是在这种网络架构下进行优化。但,依然面临很多难题(主要是循环神经网络RNNs的局限):
- 如:输入序列长度增加时性能下降
- 如:顺讯处理导致计算效率低
- ……
在2014年,Seq2Seq的提出,给人类一个不错的启发。
随后在自注意力机制的加持下,Transformer就诞生了。
1.2.Seq2Seq架构概览
大神Ilya Sutskever在2014年,以第一作者的身份,发表了论文《Sequence to Sequence Learning with Neural Networks》。
论文地址:https://papers.nips.cc/paper/2014/file/a14ac55a4f27472c5d894ec1c3c743d2-Paper.pdf

顺便说一嘴,大神Ilya Sutskever就是这位大哥,OpenAI联合创始人和首席科学家,各大自媒体都在播放他老人家的演讲视频:

这篇论文的核心就是这张图,阐述了Seq2Seq的编码器-解码器架构:
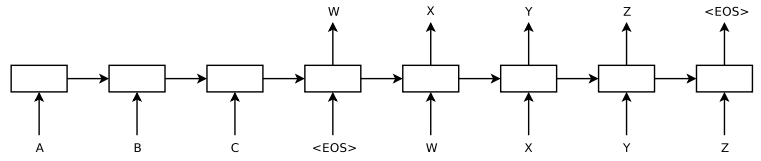
初次理解这张图,需要费点儿脑细胞,我们接下来详细拆解。
1.3.Seq2Seq架构详解
(1)“整体模型"架构
Seq2Seq会将变长的输入序列,转换为变长的输出序列。如下图:

这里举一个例子——将"你是谁"翻译为英文"Who are u”:
- t1时刻:用户输入序列"你是谁"三个字。
- t2时刻:“你"字输入给Seq2Seq。
- t3时刻:“是"字输入给Seq2Seq。
- t4时刻:“谁"字输入给Seq2Seq。
- t5时刻:Seq2Seq输出"Who”。
- t6时刻:Seq2Seq输出"are”。
- t7时刻:Seq2Seq输出"u”。

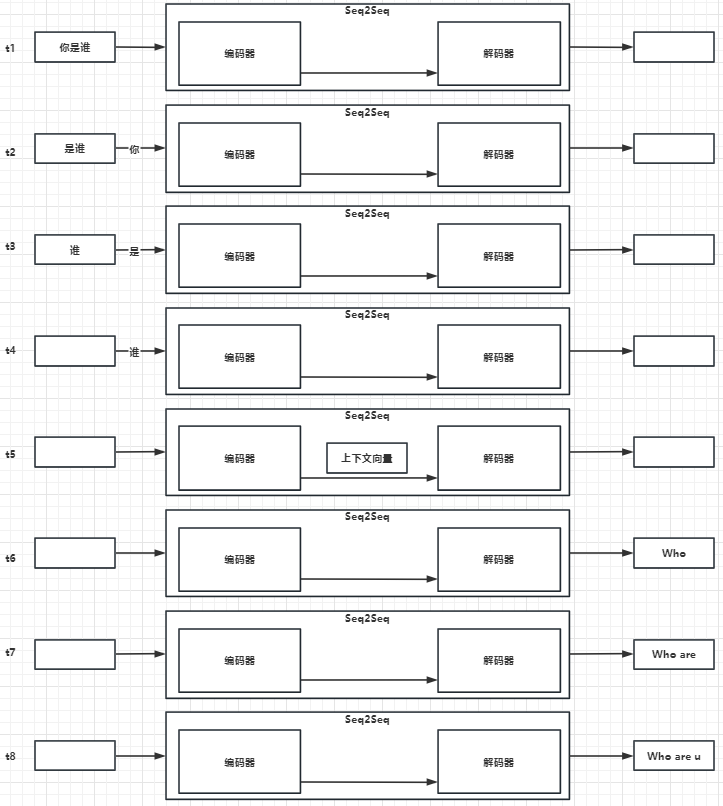
(2)“编码器-解码器"架构
进一步拆解整体模型架构,Seq2Seq由编码器+解码器组成:

这里还是以将"你是谁"翻译为英文"Who are u"例子来解析:
- t1时刻:用户输入序列"你是谁"三个字。
- t2时刻:“你"字输入给编码器。
- t3时刻:“是"字输入给编码器。
- t4时刻:“谁"字输入给编码器。
- t5时刻:编码器将学习到上下文向量,传递给解码器
- t6时刻:解码器输出"Who”。
- t7时刻:解码器输出"are”。
- t8时刻:解码器输出"u”。
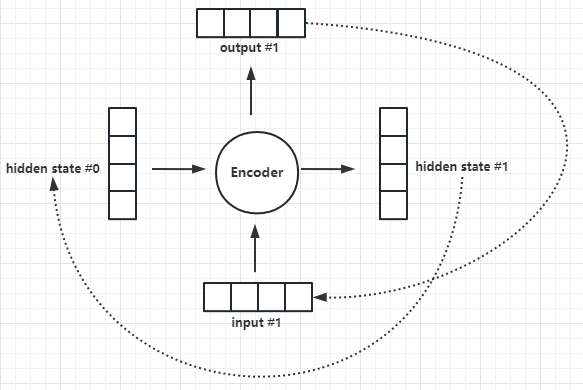
(3)“编码器、解码器"微观逻辑
编码器、解码器的具体实现:在论文中,它们都是采用RNN实现。如下图所示:
- 编码器的输入:0号隐藏层状态向量 + 1号输入词向量
- 编码器的输出:1号隐藏层状态向量 + 1号词输出向量
- 编码器的下一次输入:1号隐藏层状态向量 + 2号输入词向量
- 编码器的下一次输出:2号隐藏层状态向量 + 2号输出词向量
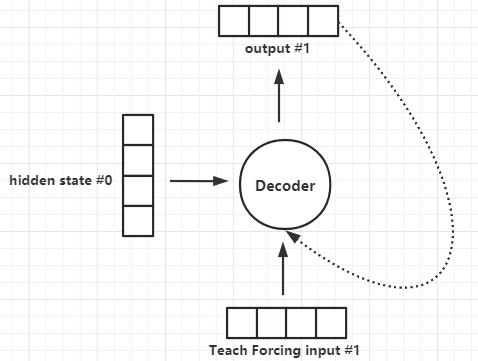
- 解码器的输入:0号隐藏层状态向量 + 1号Teach Forcing输入词向量
- 解码器的输出:1号词输出向量
- 解码器的下一次输入:0号隐藏层状态向量 + 1号词输出向量 + 2号Teach Forcing输入词向量
- 解码器的下一次输出:2号输出词向量
这还是不太直观,我们再把编码器、解码器按时序进一步展开:
- t1时刻:用户输入序列"你是谁"三个字。
- t2时刻:“你"字输入给编码器,编码器输出
1号隐藏层状态。 - t3时刻:“是"字 +
1号隐藏层状态,输入给编码器,编码器输出2号隐藏层状态。 - t4时刻:“谁"字 +
2号隐藏层状态,输入给编码器,编码器输出3号隐藏层状态。 - t5时刻:
3号隐藏层状态+ TeachForcing的"Who"字,输入给解码器,解码器输出Who。 - t6时刻:
3号隐藏层状态+ TeachForcing的"are"字 + 解码器输出who,输入给解码器,解码器输出are。 - t7时刻:
3号隐藏层状态+ TeachForcing的"u"字 + 解码器输出are,输入给解码器,解码器输出u。
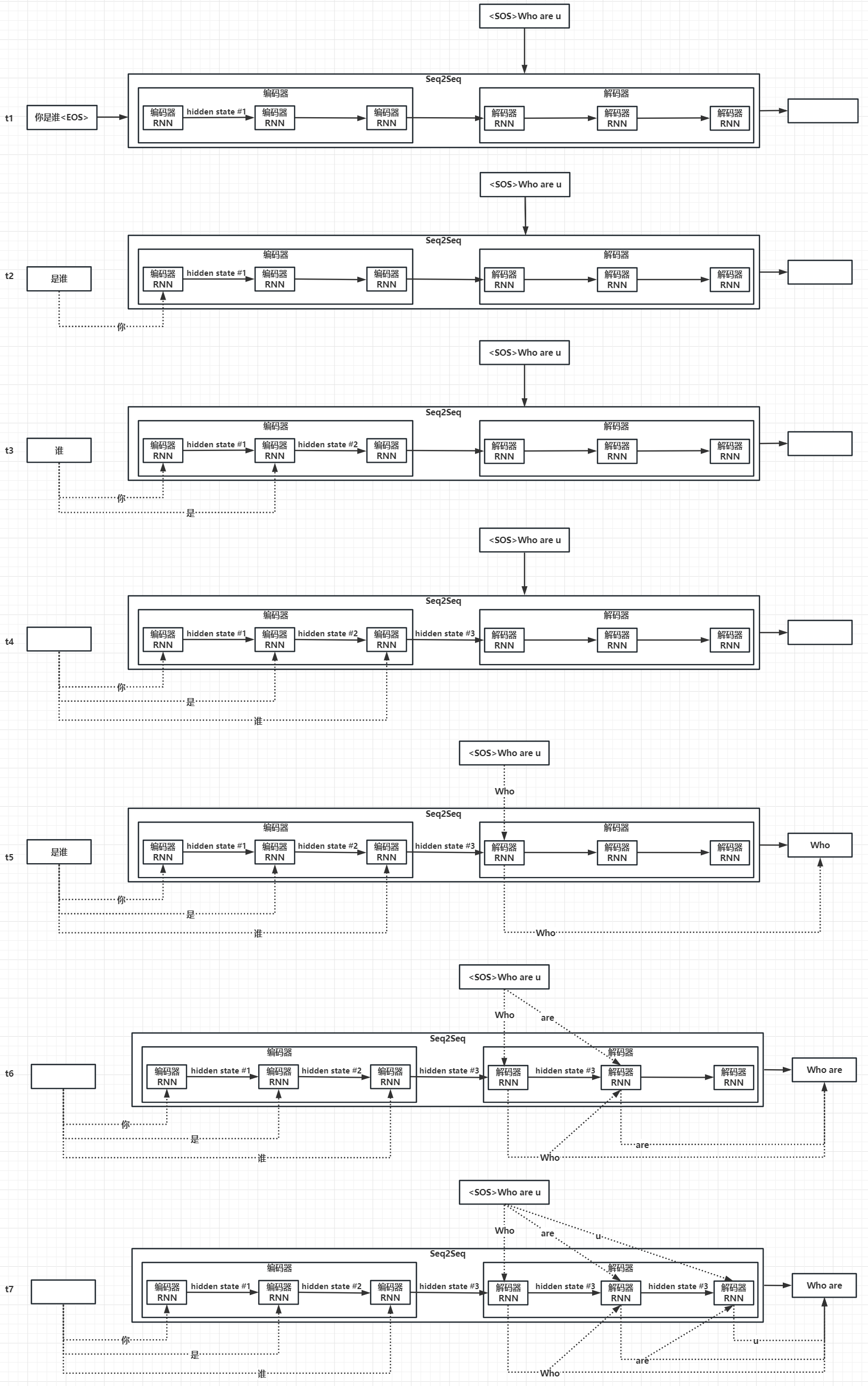
- 这里有一个细节,什么是Teach Forcing?
- 我们可以想象,如果1号解码器的预测错了,那么2号、3号解码器都会错,进而导致学习效率非常低。
- Teach Forcing好像开卷考试,如果1号解码器预测错了,Teach Forcing会纠正预测结果,进而加速学习效率。
(3)优点
- 变长序列:由于编码器、解码器采用RNN实现,所以输入序列可以是变长、输出序列也可以是变长。而CNN、DNN都不支持变长序列。
- 信息压缩:隐藏层状态,或者叫上下文向量,本质上将输入序列进行了信息压缩,转变为含有上下文语义的向量。
(4)劣势
- 长序列信息损失:由于上下文向量为定长,所以当输入序列过长时编码器会出现信息损失。这就是注意力机制的发力点,先埋个伏笔。
- 效率:采用RNN(如:LSTM、GRU)实现编码器、解码器,RNN会面临梯度消失、梯度爆炸等问题。
2.代码
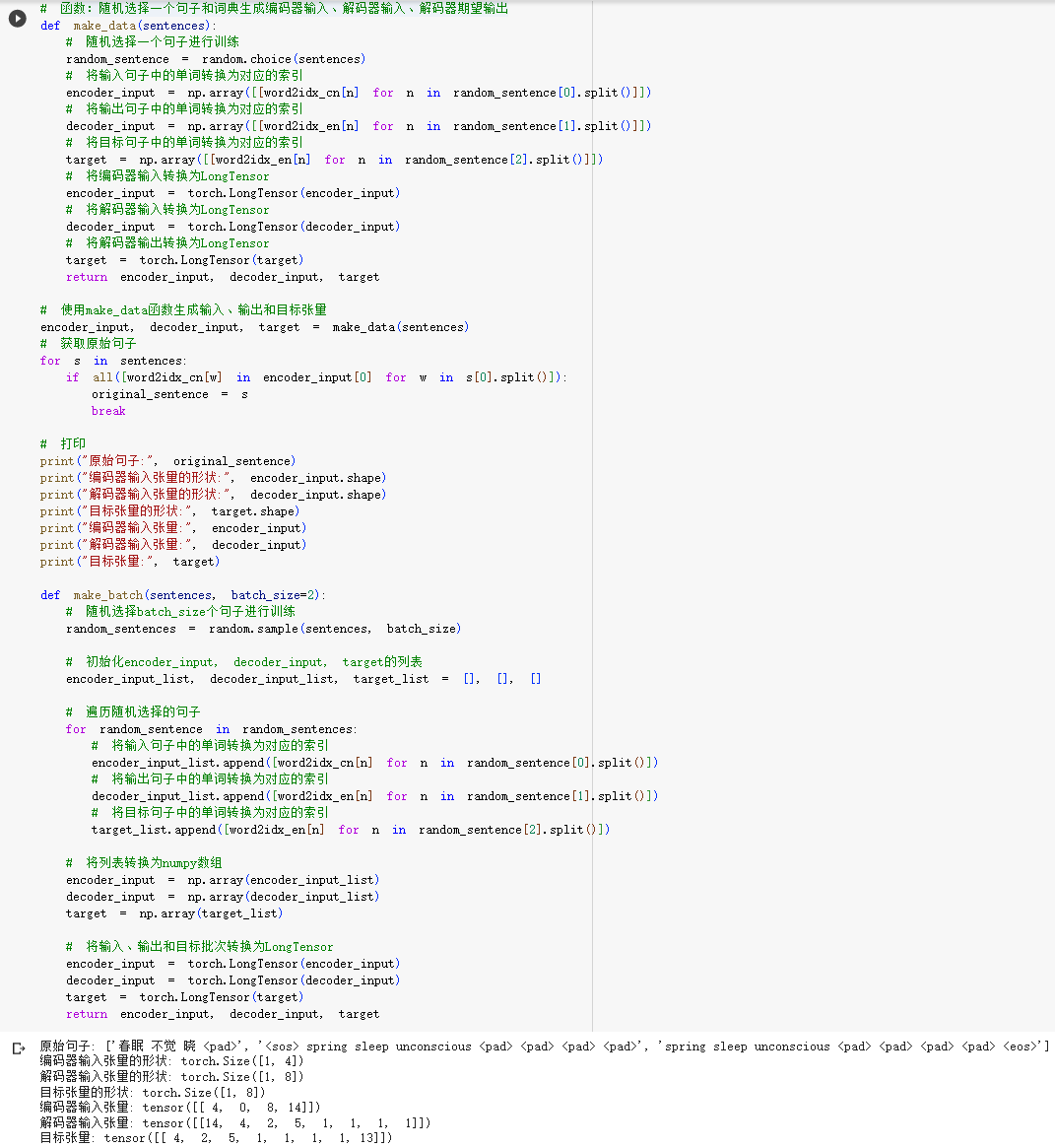
STEP1.1.构建数据集

STEP1.2.结构化训练数据
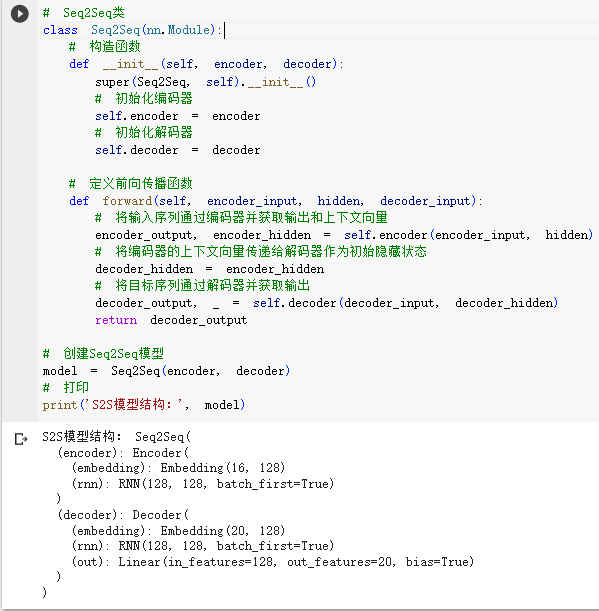
STEP2.1.定义编码器和解码器类

STEP2.2.定义Seq2Seq模型
STEP3.训练Seq2Seq模型

STEP4.测试Seq2Seq模型

3.小结
- 本文解析了Seq2Seq的内部实现,理解下图的关键是——按照时序,分析清楚每个编码器or解码器有几个输入、几个输出。
- 理解了Seq2Seq,我们接下来就可以逐步实现完整的Transformer了,且听下回分解。