2017年,JEP317中提到了Graal编译器。

Graal编译器来自Oracle Labs更早的实验项目,随后并入GraalVM。
Graal的商业目标是啥呢?Oracle借助Stack Overflow委婉地做了表达:
虽然Stack Overflow随后无情删帖,我们依然记住了关键词——ultimate programming language
什么语言有勇气宣称自己是"宇宙无敌终极编程语言”?“宇宙无敌终极编程语言"又是如何实现的呢?
如果想深入探讨上述问题,我们必须先理解一个重要的知识——JVM的执行引擎。
0x01.执行引擎的3大流派
- 解释型流派:随机应变
Java的早期版本就属于解释型流派,从此也就留下了"Java性能不如C++"的口实。
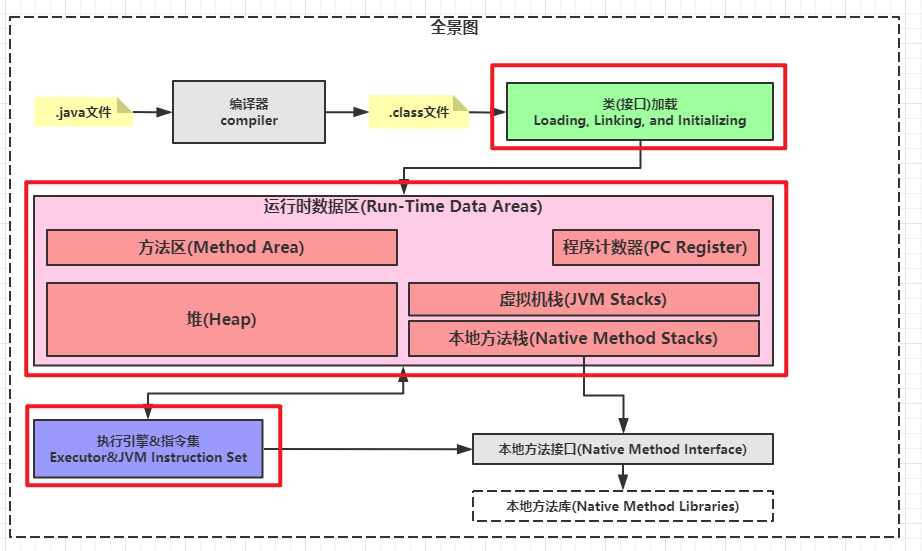
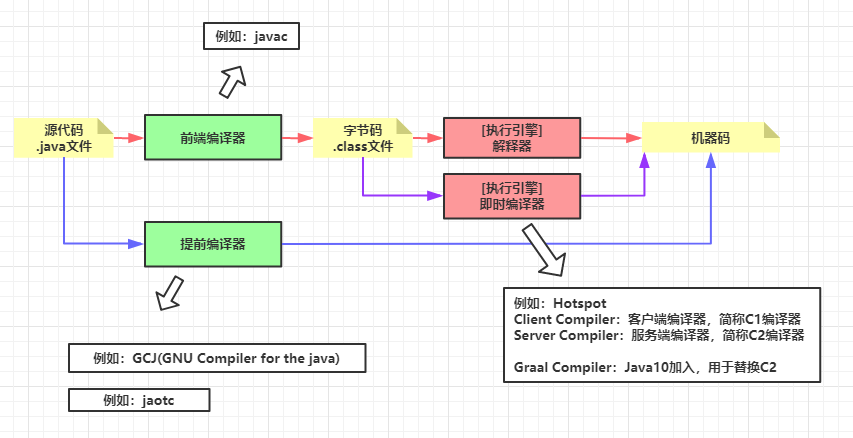
如下图红线所示,源代码通过前端编译器转换成字节码。在运行态,解释器实时理解字节码,将字节码翻译成CPU可以执行的机器码。

- 提前编译流派:有备而来
如下图蓝线所示,如果我们暂不纠结"dll/so不等于机器码"的细节,提前编译器直接将源代码转换为抽象的机器码。
接受这个流派,就意味着要承认**“Compile Once, Run Anywhere”(一次编译,到处去浪)**只是个美好的愿望。
因此,IBM于1996年发布了提前编译器(IBM High Performance Compiler for Java)之后很长一段时间,提前编译流派就没有太多的故事和发展。
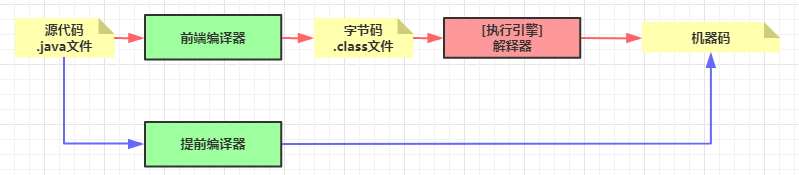
- 即时编译流派:随机应变+有备而来
即时编译流派(JIT)的思路是解释器和编译器协同工作。
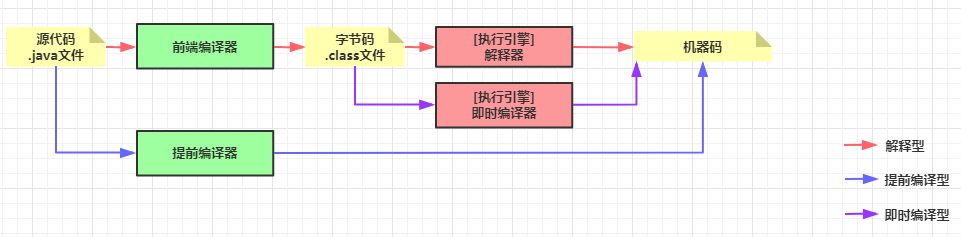
如下图红色线和紫色线所示,解释器先工作,过程中会发现某些字节码被频繁解释,于是即时编译器开始工作,即时编译器将这些热点代码转换为机器码,当热点代码需要再次执行时就不用解释了。
0x02.为什么历史选择了即时编译流派?
解释型流派有点像吃铁板烧,顾客根据当时的心情,跟厨师说:“来一份马粪胆搭配牡丹虾、北海道带子、鳕场蟹”,厨师理解了顾客意图,现场制作美味。

随机应变的执行过程,给我们带来一些好处:
- 减少准备工作的等待时间
如果是订酒席,我们就需要提前点菜、厨师提前做好。现场的就餐过程,只是把做好的菜端上来。
稍大型的C++项目,将源代码编译成机器码,就是个漫长的过程。这个过程就像提前点菜、厨师提前把菜做好。
- 具备运行时修正的可能性
吃铁板烧的顾客点完菜,可能随后改了主意:“北海道带子换黑毛和牛吧”。如果是订酒席,厨师已经把菜做好了,顾客显然不能修改了。
边解释边执行,就具备了**“动态性”**,这也是Java、Python、Ruby等语言的动态性的理论基础。
随机应变的执行过程,也带来了弊端:
- 慢
现场点菜,厨师越慢逼格越高,因为吃铁板烧不是个赶时间的事。但程序执行截然相反,执行效率堪比压榨CPU的性能极限。
从宏观上看,随机应变相较于有备而来,少了准备过程,应该会慢。
从微观上看,为什么解释型相比于提前编译型慢呢?关键点在于编译优化。
例如:源代码中有一段空循环,编译器会发现这段无用功,输出机器码时进行抹除,然而解释器只是无脑地循环10万次。
| |
本文无法展开编译优化这个更大的课题,但至少我们可以获得如下认知:
解释型流派与提前编译流派是天平的两端
即时编译流派本质是,在"边解释边执行"的基础上,实现了动态编译
0x03.为什么即时编译器不止一种?
前文,我们提到了编译优化,优化手段有的很常规,有的却很激进。本文摘录了一些激进的优化:
Dead Code Elimination:无用代码消除
Loop Unrolling:循环展开
Loop Expression Hoisting:循环表达式外提
Common Subexpression Elimination:消除公共子表达式
Constant Propagation:常量传播
Basic Block Reordering:基本块重排序
Range Check Elimination:范围检查消除
Null Check Elimination:空值检查消除
Guarding Inlining:守护内联
Branch Frequency Prediction:分支频率预测
如下图所示,Hotspot虚拟机的即时编译器就包含了C1和C2,同时在Java10加入了C2的替代者Graal。
C1的职责只是常规的编译优化,C2则承担了更多激进优化的任务。
0x04.解释器与多种即时编译器的配合关系
即时编译流派,首先还是解释器工作,热点代码触发即时编译器,即时编译一旦出现激进优化失败,就把执行权还给解释器。
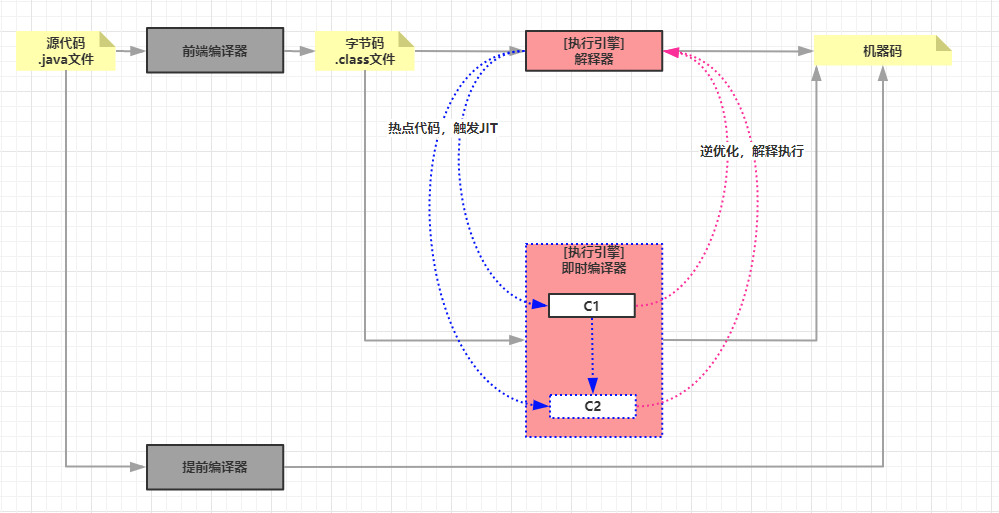
以Hotspot为例,我们进一步打开解释器与即时编译器的配合过程:
- Java 6以前,1个解释器+1个即时编译器
通过JVM的参数配置,我们只有2种选择:要么用**“解释器+C1即时编译器”**,要么用**“解释器+C2即时编译器”**。
这种做法的缺点就是把选择困难症留给了Java程序员——我怎么知道这段代码适合激进优化还是保守优化呢?
实际上,大部分情况是适合激进优化和保守优化的代码是纠缠在一起的。
- Java 7以后,1个解释器+动态选择即时编译器
Java7以后,引入了”分层编译“的理念,进而支持了动态选择即时编译器。
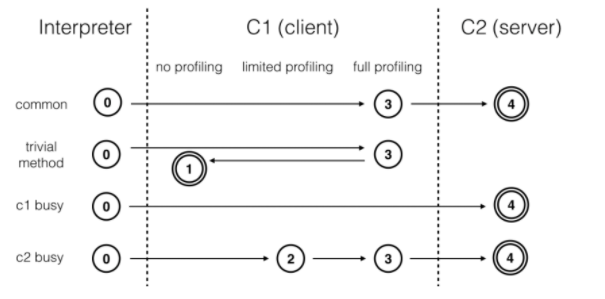
理解"分层编译”,先看"层”:
第0层:程序解释运行。解释器不开启性能监控功能。
第1层:C1编译。进行简单和可靠的优化,不开启性能监控。
第2层:C1编译。仅开启方法及回边次数统计等有限的性能监控。
第3层:C1编译。开启全部性能监控,进一步收集分支跳转、虚方法调用版本等信息。
第4层:C2编译。启用更多耗时较长的优化,还会依据性能监控信息进行不可靠的激进优化。
再看"分”——分是指**“分场景”**:
普通场景:此场景下,热点代码触发C1,C1逐步开启全量性能监控,就会触发C2。
简单代码场景:此场景下,热点代码触发C1,C1逐步开启全量监控,发现没必要C2,则关闭全量监控。
C1繁忙场景:此场景下,C1繁忙,热点代码直接触发了C2。
C2繁忙场景:此场景下,C2繁忙,热点代码触发C1,先开启有限的监控,随后进行全量监控,最后进入C2。
分场景触发的过程,周全且精细化地逐级开启性能监控,充分体现了JVM设计的精巧。这种精巧的设计其实也可以移植到性能敏感的产品中。
参考:https://www.infoq.cn/article/java-10-jit-compiler-graal
0x05.总结
本文的目标是宏观阐述JVM执行引擎的全貌:
1.JVM执行引擎的3大流派
2.如何看待即时编译流派的利与弊
3.解释器与即时编译器的配合方式——分层编译
结合笔者另外两篇文章《【类加载机制】从一道面试题开始》、《【运行时数据区】用仓库管理员的视角理解运行时数据区》,我们已经从宏观上看到了JVM的三大构成,笔者将在后续文章中,与读者们继续深入与探索个中细节。