1.起于累土:为什么要阅读字节码
笔者最近的一项工作是设计一套课程,用于辅导新员工如何做好性能优化。
这项工作很快遇到了问题:
讲内存泄露/溢出的定位工具,就要求听众先对JVM的运行时数据区有基本理解。
讲运行时数据区,又要求听众先大致理解类加载子系统如何一步步地将字节码加载到内存中。
讲类加载子系统,又要求听众先理解字节码表示了哪些"静态信息”。
….
性能优化是一个复杂的系统化话题,性能优化的手段分为3个级别:
倔强青铜级:时空转移
当计算效率不足时,用空间换时间。例如:将需要频繁使用的数据,提前缓存在内存中。
当内存空间不足时,用时间换空间。例如:将不需要的缓存数据去掉,动态计算。
在这个层次上解决问题,优点是朴实,缺点是此消彼长、绵绵无期:
因为时间换空间与空间换时间本质是互逆的手段。
一个软件产品可能在迭代1暴露出了计算效率不足,采用了空间换时间。
到了迭代2又因为迭代1的性能优化导致空间不足,又要将大量的缓存替换为实时计算。
……
笔者的一位程序猿朋友,在多次时间换空间、空间换时间的性能优化工作之后,发出了一句颇有哲理的感慨:
时间是不可能被消灭的,只能被转移

永恒钻石级:业务裁剪
能用这个级别手法的,一般是老程序猿。
凭借多年的业务领域经验,深刻理解了业务流程中哪些步骤是冗余的。
无论是时间瓶颈或者空间瓶颈,删掉冗余代码,一招搞定。

在这个层次上解决问题,优点还是朴实,缺点是比较依赖业务专家,无法批量复制与推广。
最强王者级:底层优化
使用这种手法,就要求程序猿对于JVM、操作系统、网络有比较深刻的认识,大部分程序猿都止步此。
通过对静态逻辑(字节码)的理解和动态逻辑(运行时)的理解,精确找到空间瓶颈和时间瓶颈,进而采用更加具有通用性的手段开展优化工作。
如果说性能优化是九层之塔,那么阅读字节码就是累土中的重要基石之一。

2.编程界的通天塔:字节码的宏观意义
知乎上有一个趣帖全世界为什么不能统一语言?(https://www.zhihu.com/question/22133387)
有一个有趣的回答:“你想造通天塔就直说”。
通天塔,也叫巴别塔,传说人类想建造一个通往天堂的天梯而触怒了神灵,于是神灵将人类的语言隔绝,导致人类种族语言不通。

编程界也存在多种编程语言,任何VM类型的语言(含编译、执行)都存在如下流程:
前端编译器:将源代码转换为字节码
字节码加载模块:将字节码加载到运行时数据区(就是内存)
解释执行器:根据内存中的VM栈,执行字节码
后端编译器:将频繁执行的字节码直接生成为机器码缓存下来,提升执行效率
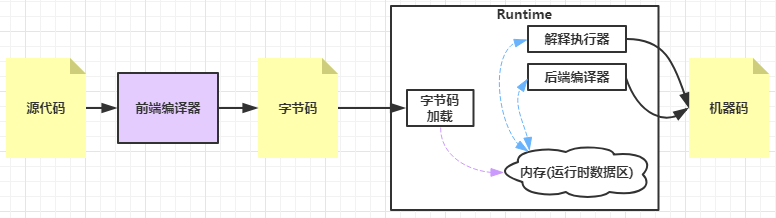
我们会发现,字节码加载、运行时数据区似乎大同小异,于是进一步简化上述流程:
字节码加载取决于运行时数据区
运行时数据区的理论主要是分代理论、回收理论等
从简化的流程中,我们可以看到,一种编程语言的源代码语法无论多么"花哨”(满足不同领域的程序猿不同的编程风格),最终都要回归到朴实的字节码。

在Java这种语言中,JVM提供了javac和javap两种工具实现前端编译和前端反编译的互逆操作:
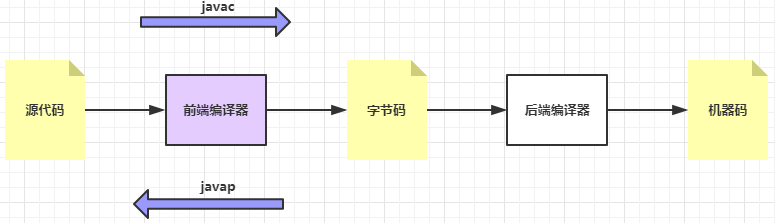
试想一下,如果字节码是一种规范,“类加载子系统、运行时数据区、解释执行器、后端编译器"就有可能做成VM内置的标准件,那么开发一种新的编程语言只需要关注2点:
1.如何设计一种新的语法,满足新编程领域的特征、风格?
2.如何将新的语法源代码,转换为标准的字节码?
设计一种新的编程语言,上述2点并不是很困难,而真正的技术门槛、技术成本是那些VM内置的标准件。
这将是一种可怕的效率提升革命,于是Java之父Gosling强调:
JVM能支持各种符合字节码规范的新兴编程语言,Java只是JVM上能运行的编程语言之一。
Java并不牛逼,JVM才是最牛逼的。
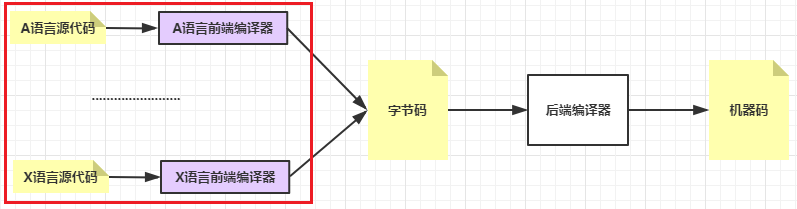
字节码就是统一的机器语言:
从程序猿的视角看,无论使用怎样不同的编程语言,都能被前端编译器转换为标准的JVM字节码;
从CPU的视角看,无论是怎样不同的CPU架构,后端编译器都能将标准的JVM字节码转换为不同的机器码;
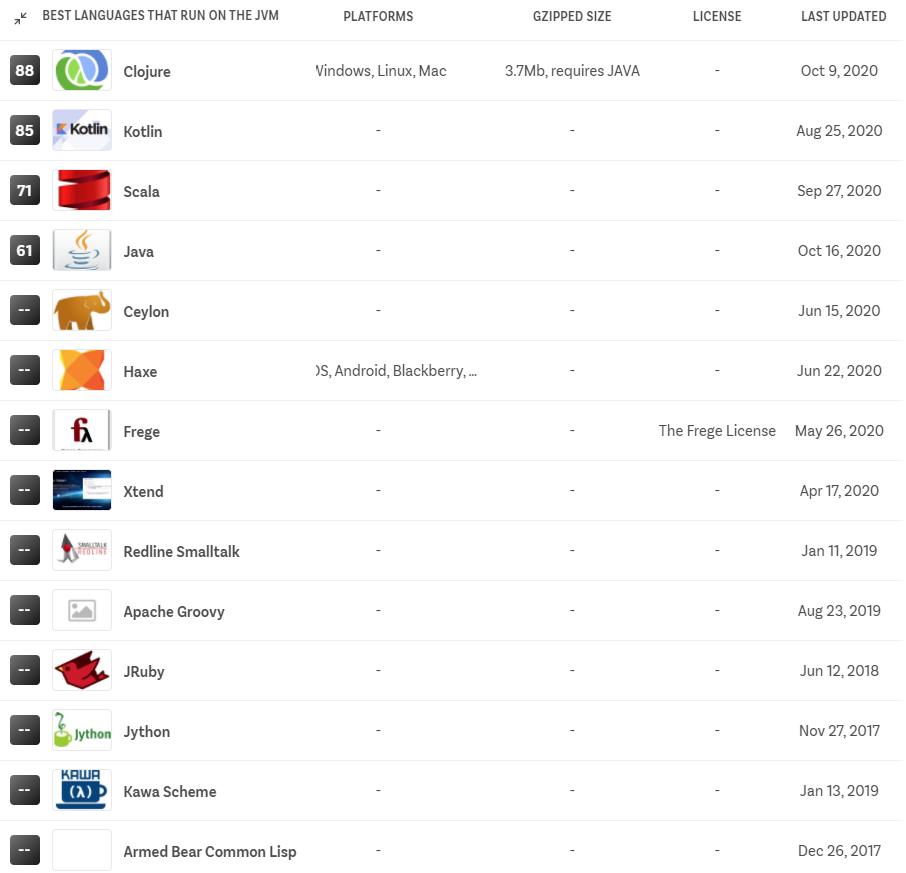
目前,JVM支持了很多编程语言,其中包含了注入Kotlin这种热度很高的新型语言:
数据来源:https://www.slant.co/topics/397/~best-languages-that-run-on-the-jvm
3.引用地图:字节码的微观逻辑
JVM字节码的规范很复杂,在深入细节之前,最好先理解字节码的微观逻辑。
首先写一段简单的代码Demo4.java:
这个类只有一个无参构造函数
再通过前端编译器,从Demo4.java生成Demo4.class:
用16进制编辑器打开
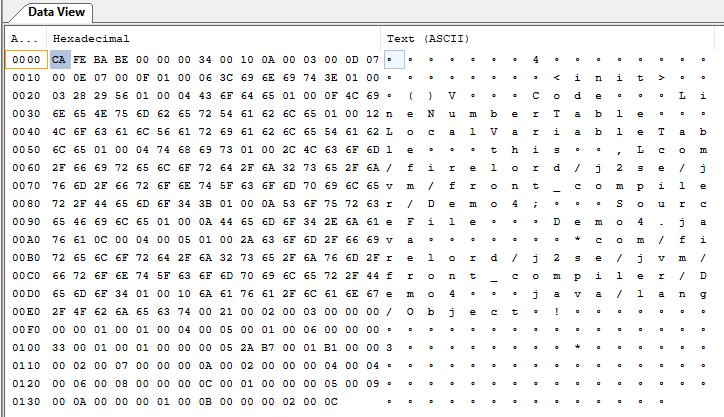
Class文件分为2个部分:常量池和方法区
红色框:常量池区域
橙色框:方法区区域
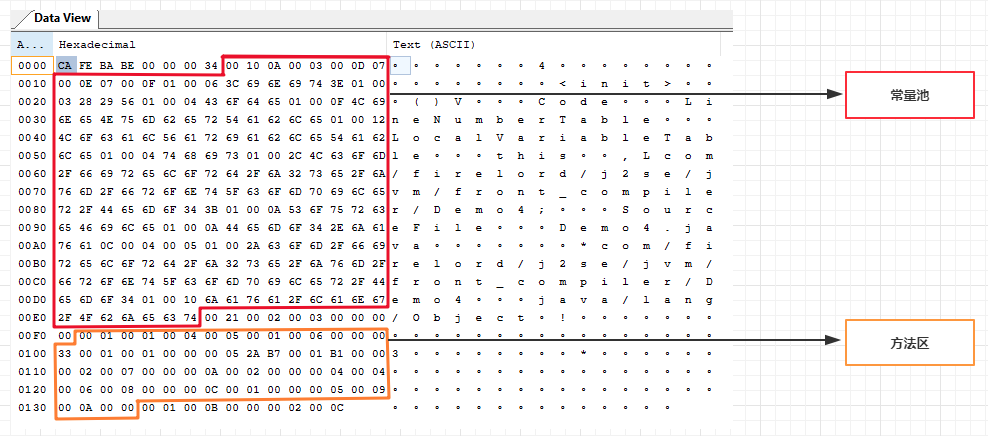
这里的常量、方法,不是Java语法中的常量、方法,而是站在VM的角度看到的常量和方法。
例如:“Demo4"这个字符串,在Java源代码中出现了2次:
JVM将"Demo4"这个字符串放在了常量池中:
蓝色框:Demo4字面量

在Java源代码中第一处表达类名时,JVM只需要用1个字节,最终指向常量池中"Demo4"的位置:
最终指向:此处简化了从ClassInfo常量逐级指向Utf8_info常量的过程
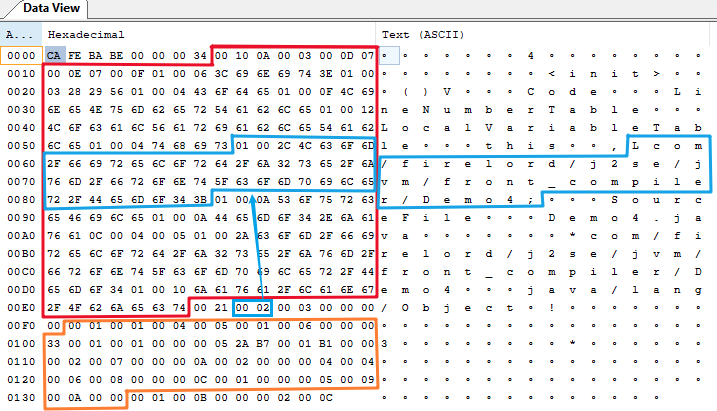
从上述例子可以看到,JVM字节码的微观逻辑就是引用,引用的目的就是复用,复用的目的就是用最小的字节数表达信息。
4.总结
本文主要内容:
- 论述阅读字节码对于深入理解编程语言特性的意义
- JVM字节码规范对于设计新的编程语言的价值
- JVM字节码如何通过引用地图,实现最小字节数表示最大的信息量。
下一步,笔者将通过一段代码实例,深入Class文件结构的细节。
5.参考文献
https://www2.slideshare.net/RednaxelaFX/jvm-a-platform-for-multiple-languages
https://www.slant.co/topics/397/~best-languages-that-run-on-the-jvm