1.编译器的宏观过程
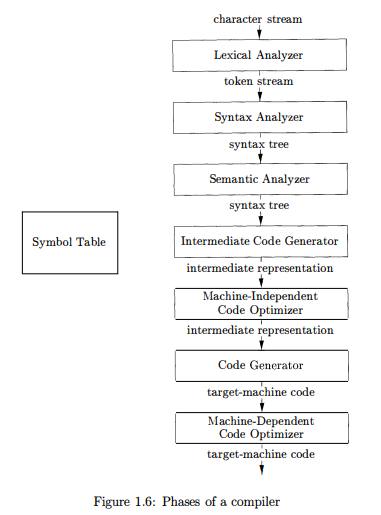
下图摘自《Compilers, Principles, Techniques, &Tools》(后文简称龙书),描述了编译器工作时的宏观过程,每个方块表示编译器内部的一个"模块”,每个箭头表示该模块的"输入"与"输出”:
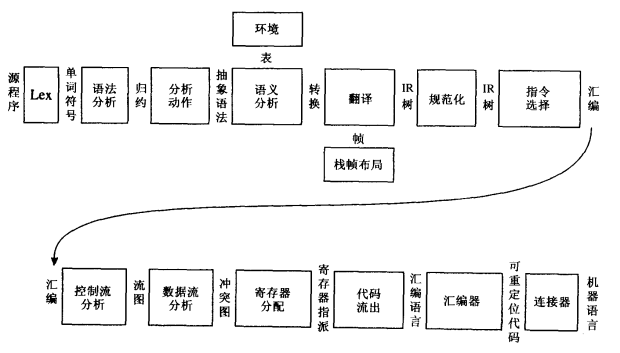
下图摘自《现代编译原理-C语言描述》(后文简称虎书),进一步细化了编译器的宏观流程:
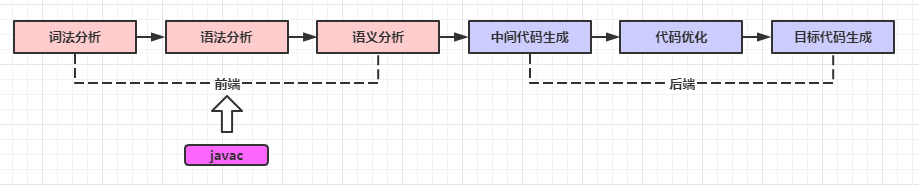
上述环节复杂且技术术语繁多,我们可以结合JVM的特点,以及即将剖析的javac源码,做了部分抽象与精简:

从上图看,笔者做了2个抽象:
- 简化步骤:将涉及
优化、分析的环节简化为代码优化。 - 步骤分组:将6个步骤分为
前端编译和后端编译。
简化步骤比较好理解,重点看看对步骤的分组——在龙书中,对前端编译(frontend)和后端编译(backend)做了定义:
分析部分的环节被称作
前端编译(frontend),综合部分的环节被称作后端编译(backend)。

怎么理解分析部分和综合部分呢?站在JVM的角度看:
- 分析部分:从java源代码生成字节码的过程就属于分析部分,即对
源码进行分析,最终分解为多个组成元素的过程。 - 综合部分:对JVM正在执行的字节码进行JIT就属于综合部分,即从C1、C2等层次进行优化,最终生成CPU可以执行的机器码。
在很多现代编译器中,不仅和JVM一样将编译过程分为前后端,并且一个编译器还可能包含多个前端编译器(frontend)和多个后端编译器(backend),用来应对不同的应用场景。
2.javac在宏观过程中的位置
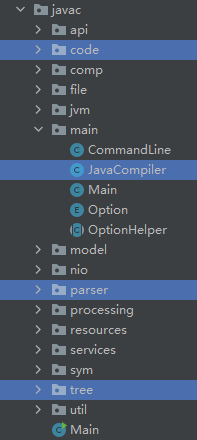
回顾了编译器的宏观流程,javac本质上属于前端编译器。
从javac的源码中,可以看到如下几个核心的package,分别覆盖了词法分析、语法分析和语义分析。
3.词法分析的概念
我们通过解读龙书中这段话,来理解一下词法分析中的几个关键概念:

词法分析(Lexical Analysis):将源代码字符流拆解成一个个的子元素,每个子元素叫做词素(lexeme),进一步将词素转换为词法单元(Token)。
说明1:1个源代码文件会包含N个
词素,每个词素会转换为1个Token。说明2:词法单元最终会存储到
符号表(Symbol Table)中。

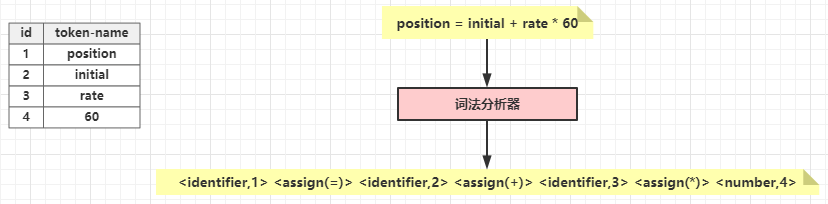
举一个具体的例子(代码片段原子龙书):
| |
在词法分析过程中:
position被提取为1个
词素(lexeme),该词素被映射为1个词法单元(Token)——<identifier, 1>。- 其中,identifier后文简写为id,1是该token在
符号表中的位置。
- 其中,identifier后文简写为id,1是该token在
=被提取为1个
词素(lexeme),该词素被映射为1个词法单元(Token)——<assign(=)>。- 其中,=是一个赋值运算符,因此它对应的
词法单元(Token)没有attribute-value。
- 其中,=是一个赋值运算符,因此它对应的
initial被提取为1个
词素(lexeme),该词素被映射为1个词法单元(Token)——<identifier, 2>。+被提取为1个
词素(lexeme),该词素被映射为1个词法单元(Token)——<assign(+)>。rate被提取为1个
词素(lexeme),该词素被映射为1个词法单元(Token)——<identifier, 3>。*被提取为1个
词素(lexeme),该词素被映射为1个词法单元(Token)——<assign(*)>。60被提取为1个
词素(lexeme),该词素被映射为1个词法单元(Token)——<number, 4>。
最终,词法分析输出:
| |
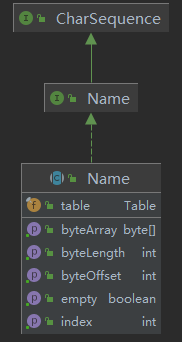
4.javac中对词素的具体实现-Name and Table
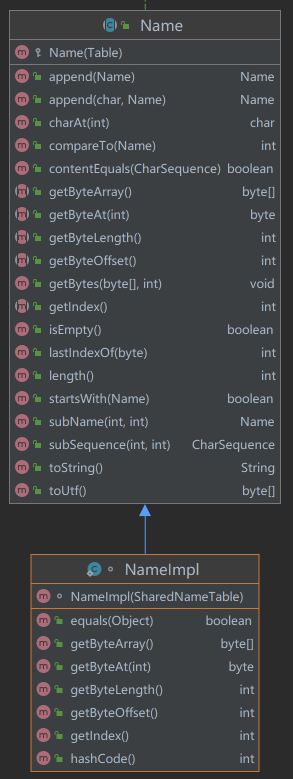
在javac的源码中,定义了Name和Table,基本可以与词素(lexeme)对应:
com/sun/tools/javac/util/Name.javacom/sun/tools/javac/util/SharedNameTable.java#NameImplcom/sun/tools/javac/util/Names.javacom/sun/tools/javac/util/Name.java#Tablecom/sun/tools/javac/util/SharedNameTable.java
4.1.com/sun/tools/javac/util/Name.java
从属性看
Name对象的本质是将源代码中的单词、符号分词了,每个分词就是一个Name对象。
有2个关键点需要注意:
- 源代码字符流在javac是中是以
byte[]存储的,所以Name对象包含了1个byteArray属性,该属性存储了当前Name对象对应的源代码子字符流。 - 相同
内容的分词是同一个Name对象。
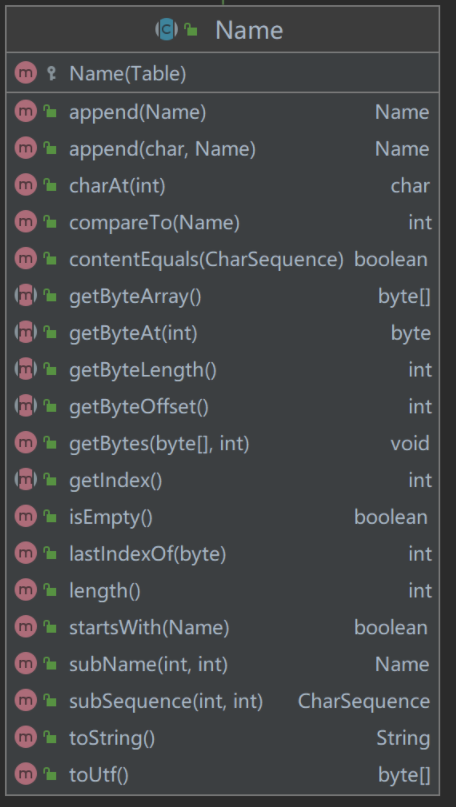
从方法看
Name对象提供了对Name对象本身、Name对象之间的各种操作。
有1个关键点需要注意:
- Table对象将源代码字符流转换成了byte数组,为了提升性能,实现了
输入缓冲和哨兵标记(详见龙书,后文解读JavaCompiler#readSource方法也会展开)。因此,Name对象中提供了诸如getByteArray()、getByteAt()等方法,从该Name对象所属的Table对象中反查对应的源代码字符流。
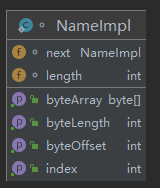
4.2.com/sun/tools/javac/util/SharedNameTable.java#NameImpl
从属性看
NameImpl类是SharedNameTable类中的内部类。
疑惑:笔者没有理解为什么要如此设计。
其中,有1个关键点:
NameImpl对象中维护了next属性,这就要说到Table对象的实现——Table对象按照HashTable实现,HashTable的Key是每个Name对象的hashCode,Value是对应的NameImpl对象。当1个新的NameImpl对象准备加入到HashTable时,如果Key发生hash冲突时,就会将这个新的NameImpl对象加到这个Key对应的已经存在的NameImpl对象的next属性中,形成一个单链表。
从行为看
从行为上看,只是具体实现了Name基类的getByteXxx方法。
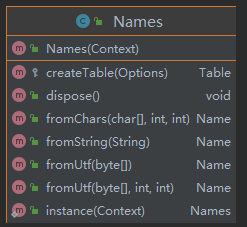
4.3.com/sun/tools/javac/util/Names.java
从属性看
Names对象维护了N个Name对象,这些Name对象就是Java中定义的关键字、保留字。
Names对象还维护了Table对象。
这里也有2个关键点:
- 这些关键字、保留字类型的
Name对象在JavaCompiler初始化时就会被创建出来。 - 当正式开始词法分析的时,在解读源代码字符流时,会去获取已经缓存的这些关键字、保留字
Name对象,而不需要动态创建。

从行为看
Names对象提供了fromXxx方法,这些方法的实现会去调用Table对象的接口,这些方法更新Table对象(如:更新Hash表,解决Hash冲突等),并返回Name对象。
4.4.com/sun/tools/javac/util/Name.java#Table
从属性看
Table对象维护了Names对象,前文已经描述了Names对象中维护了多个关键字、保留字的Name对象。
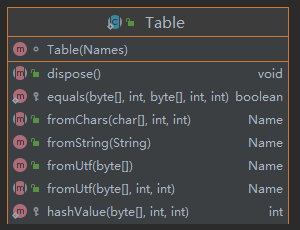
从行为看
提供了给Names对象调用的fromXxx方法,这些方法更新Table对象(如:更新Hash表,解决Hash冲突等),并返回Name对象。
4.5.com/sun/tools/javac/util/SharedNameTable.java
从属性看
SharedNameTable是Table的具体实现类。
SharedNameTable对象维护了hashes属性,是Hash表的具体实现,其中NameImpl[]的数组索引是每个NameImpl对象的hashCode。
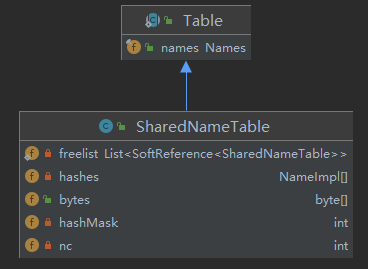
从行为看
关键点还是Hash表的具体实现,具体以fromChars方法的代码注释:
| |
5.javac中对词法单元的具体实现-TokenKind and Token
在javac的源码中,定义了TokenKind和Token,基本可以与词法单元(Token)对应:
com/sun/tools/javac/parser/Tokens.java#TokenKindcom/sun/tools/javac/parser/Tokens.java#Tokencom/sun/tools/javac/parser/Tokens.java#Tokens
5.1.com/sun/tools/javac/parser/Tokens.java#TokenKind
从属性看
TokenKind是一个枚举类,定义了Java中的关键字、保留字、运算符等。
每个枚举值对应词法单元(Token)的token-name。

5.2.com/sun/tools/javac/parser/Tokens.java#Token
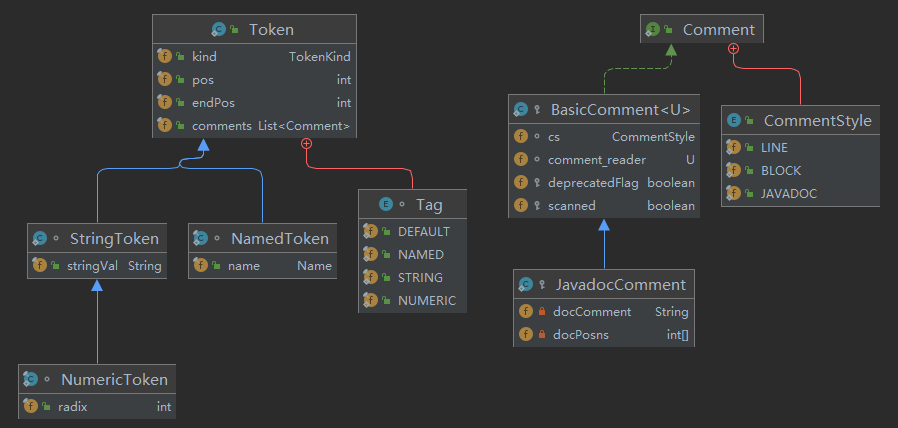
从属性看
从3.词法分析的概念中可以知道,词法单元(Token)有多种类型,如:标识符Token、运算符Token、字面量Token等。
因此,javac实现了如下Token继承关系:
其中,Token的各个子类除了有kind属性外,还有各自特有的属性。
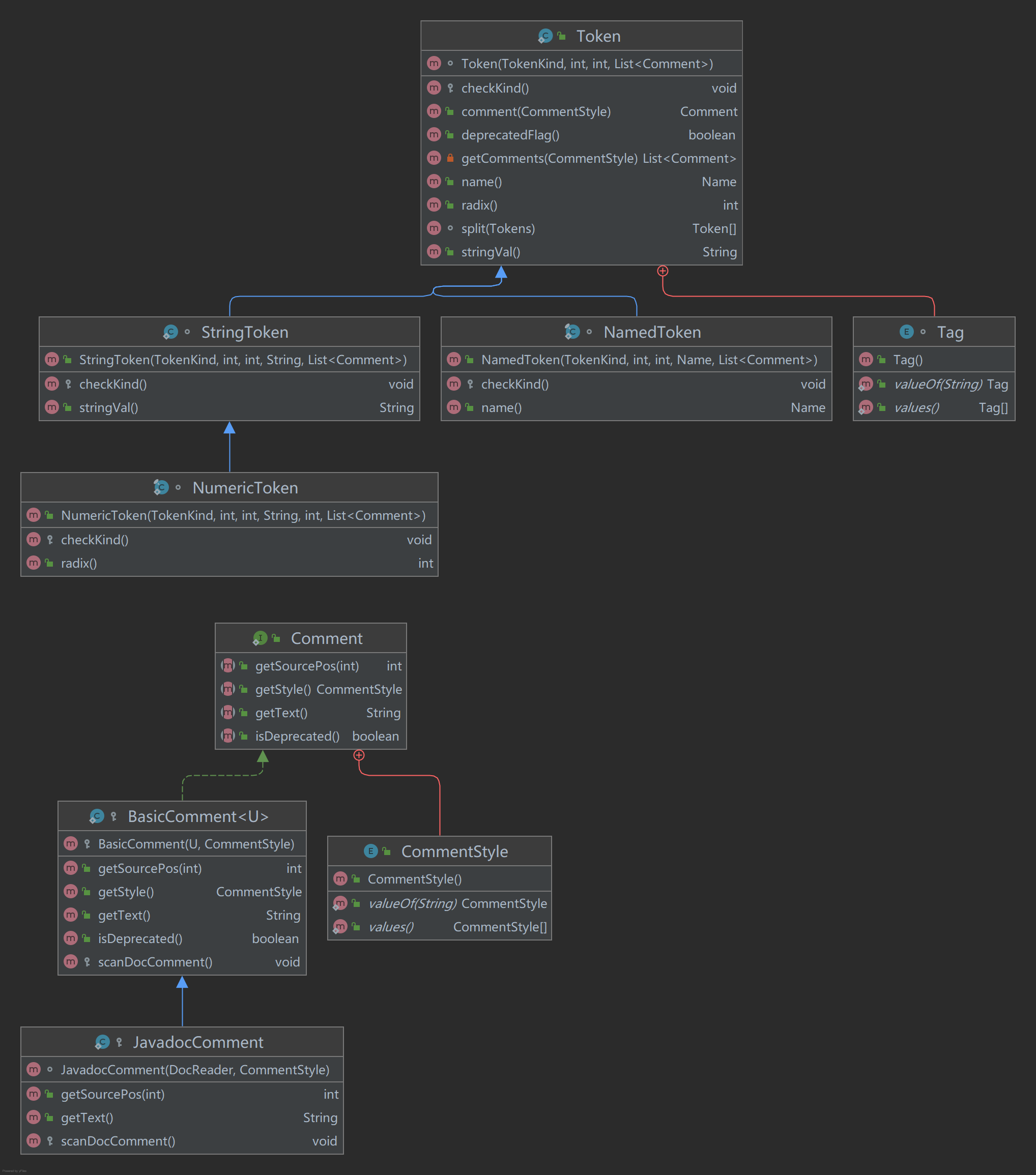
从行为看
Token对象提供了各种get方法,表达Token对象的<token-name,attribute-value>。
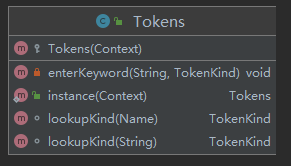
5.3.com/sun/tools/javac/parser/Tokens.java#Tokens
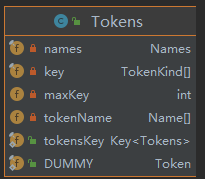
从属性看
Tokens对象维护了2个关键的属性:
key:数组索引是Name对象在Hash表中的index,value是TokenKind对象。tokenName:数组索引是TokenKind对应枚举值的序号,value是Name对象。
从行为看
从Tokens对象提供的方法看,有2个关键点:
- 调用链1:创建
JavaCompiler对象时,会触发Names的构造函数,- 进而触发
SharedNameTable的构造函数。 - 进而触发
NameImpl的构造函数,继而触发了Names对象的初始化。
- 进而触发
- 调用链2:创建
ParserFactory对象时,会触发Tokens的构造函数,- 进而触发了
Tokens的构造函数,继而在Tokens对象中建立了Name到Token、Token到Name的双向映射。
- 进而触发了
6.一些感慨:理论、产品化
有一次讨论LLVM的时候,一位老前辈感慨过:老美的下一代在玩编译器,我们的下一代还在捣腾CRUD。
感兴趣的读者,可以去搜索一下LLVM的作者在研究生阶段的论文以及他的职业经历。
包括笔者引用的三本编译器领域圣经:龙书、虎书、鲸书以及其中我们现在还要反复咀嚼的编译理论,距今也有几十年多年的历史。
能够透彻理解JVM原理的程序猿并不多,真的阅读JVM源码的更少,这或许就是我们在技术上还需要弥补的巨大差距。
另外,通过阅读javac在词法分析部分的源码,我们就可以发现:
- 编译器理论是指导产品化的灵魂(如:词素、词法单元、有限状态机等)。
- 产品化却在实践中会考虑更多因素(如:输入缓冲和哨兵标志、词素Hash表等),高于编译器理论。
7.下一步
接下来,笔者会继续分析javac在词法分析环节,如何实现有限状态机。
z.参考
龙书:《Compilers, Principles, Techniques, &Tools》Second Edition
虎书:《现代编译原理-C语言描述》