1.困扰
每一个JEP都会通过Motivation描述改进的目标,通过Summary描述改进的内容,通过Description描述改进的细节与效果。
但,对于StackWalker这类新增、修改API的JEP,往往看完以后会有一种"眼睛会了手不会"的感觉(阅读它们的javadoc,也有同样的感觉)。

以JEP259和StackWalker的javadoc为例:
摘自 JEP259-Motivation章节:
There is no standard API to traverse selected frames on the execution stack efficiently and access the
Classinstance of each frame.There are existing APIs that provide access to a thread’s stack:
Throwable::getStackTraceandThread::getStackTracereturn an array ofStackTraceElementobjects, which contain the class name and method name of each stack-trace element.SecurityManager::getClassContextis a protected method, which allows aSecurityManagersubclass to access the class context.………………
摘自JEP259:Summary
Define an efficient standard API for stack walking that allows easy filtering of, and lazy access to, the information in stack traces.
………………
摘自javadoc:
A stack walker.
The walk method opens a sequential stream of StackFrames for the current thread and then applies the given function to walk the StackFrame stream.
The stream reports stack frame elements in order, from the top most frame that represents the execution point at which the stack was generated to the bottom most frame.
The StackFrame stream is closed when the walk method returns. If an attempt is made to reuse the closed stream, IllegalStateException will be thrown.
大意就是说,如果Java程序猿想获得虚拟机栈,用老的API(Throwable::getStackTrace),即不易用,也不高性能。新的API(StackWalker)已经完美的解决了这个问题。
阅读完JEP,笔者情不自禁地产生了若干疑问:
- 为什么需要获得虚拟机栈?
- 前提:我们已经理解了虚拟机栈的相关基础知识。
- 为啥返回了
Stream就要抛IllegalStateException? - 过滤就能提升性能?——假设被搜索的全集是线性的,那么获得子集和获得全集的性能损耗似乎只有对象的创建。
- 什么是
lazy access? - ……
这可能就是产生"眼睛会了手不会"困扰的根源:
- JEP和javadoc默认我们已经具备了这个API相关的先验知识。
- 比如:
StackWalker的JEP已经默认我们理解了虚拟机栈、虚拟机栈帧等。 - 比如:
StackWalker的Javadoc默认我们理解JIT可能进行的栈上优化的影响。
- 比如:
- JEP和javadoc无法在有限的篇幅展开技术细节,只能描述技术结论。
- 比如:
StackWalker的JEP只能描述它的性能优于老的API,却无法展开阐述它是开展的性能优化,我们不了解完整的性能优化逻辑链,就有可能错误地使用StackWalker的API(甚至,大名鼎鼎的log4j团队也在StackWalker踩过坑,见后文)。
- 比如:
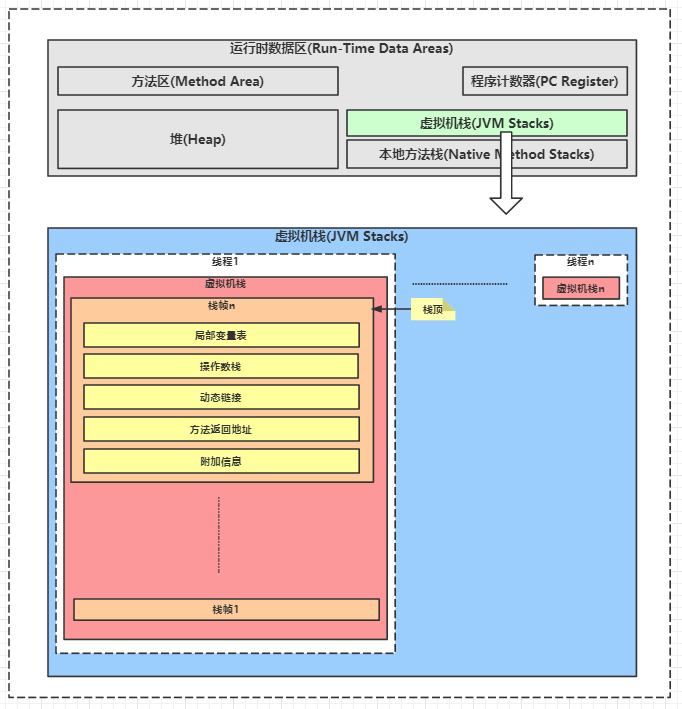
2.基础知识回顾:虚拟机栈
- 在JVM的运行时数据区中,有一块区域叫做"虚拟机栈”
- JVM为每个线程维护一个虚拟机栈。
- 每个虚拟机栈中包含若干栈帧。
- 每个栈帧对应一个方法
- 比如:线程1从函数1开始,函数1调用函数2,那么JVM会为线程1开辟1个虚拟机栈,函数1栈帧和函数2栈帧依次入栈,函数2执行完出栈,函数1继续执行完成后出栈。
- 每个栈帧的最关键信息是操作数栈,每个操作数栈存储的就是这个函数的实现。
- 操作数栈存储的内容是JVM指令序列,JVM就是在执行这个指令序列来执行这个函数体。
3.为什么要获得虚拟机栈?
根据1.基础知识回顾:虚拟机栈,我们知道虚拟机栈可以反应某个线程内,函数的调用链,比如:
- 场景1:业务代码从main函数开始,层层调用了哪些函数?
- 场景2:业务代码启动了某个线程,这个线程内部层层调用了哪些函数?
什么时候需要获得"函数调用链"呢?比如:
- 日志组件log4j,它打印错误日志的时候,就需要打印出"函数调用链”。
- 安全检查的时候,我们可以通过"函数调用链"识别是否有不安全的调用者、不安全的调用链路。
4.How:能用
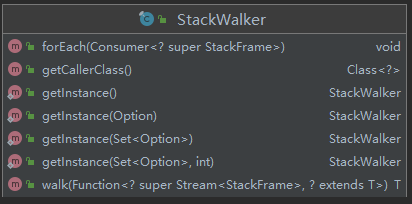
StackWalker提供了4种方法:
- getInstace:获得StackWalker实例
- forEach:遍历栈帧
- walk:通过Stream方式遍历栈帧
- 其它:getCallerClass()
从实战角度,有两种使用方式:
- getInstance + forEach
- getInstance + walk
4.1.getInstance + forEach
先看一下getInstance和forEach结合使用的实例代码:
| |
forEach方法等效于
| |
4.2.getInstance + walk
再看一下getInstance和walk结合使用的实例代码:
| |
通常,面向谷歌编程的我们,都能对StackWalker了解到这个程度。但想在实战中用好它,还需要进一步探索。
5.How:用好
5.1.安全性-walk()为什么禁止返回Stream?
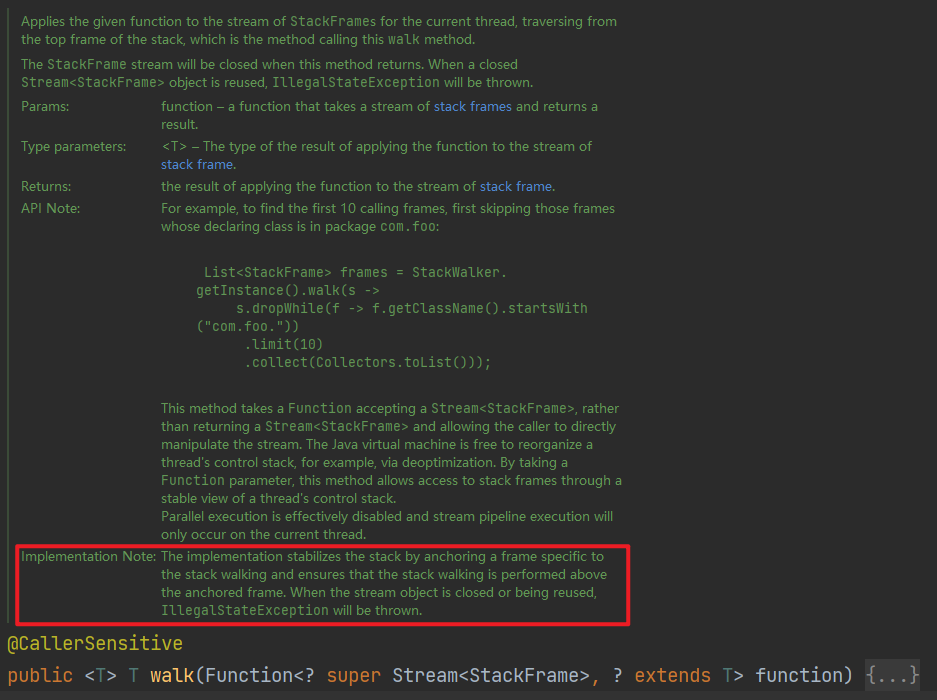
如上图所示,walk方法的入参function,这个回调的输入是Stream<StackFrame>,返回值是T。walk方法的返回值也是T。
从语法上,显然可以通过function将Stream<StackFrame>作为walk方法的返回值保存下来。我们可以对保存下来的Stream继续进行二次操作。但运行结果是抛出了异常IllegalStateException 。
| |
我们很容易这样想:当我们在某个时刻调用walk方法时,walk方法通过调用JVM底层某个API获得此时此刻的调用栈的快照,那么我们将这个调用栈快照以Stream的形式保存下来进行二次操作,似乎是逻辑合理的。为什么这个API要禁止这种行为呢?
然而,逻辑合理不代表安全:基于JVM在运行时的栈优化原理,JVM可能出于性能优化的理由,在任意时刻改变当前的栈结构进行修改。因此,不仅我们保存Stream的行为不安全,每次调用StackWalker#walk()方法时,都要重新调用JVM侧的native方法,重新对本次调用时刻的虚拟机栈进行快照:
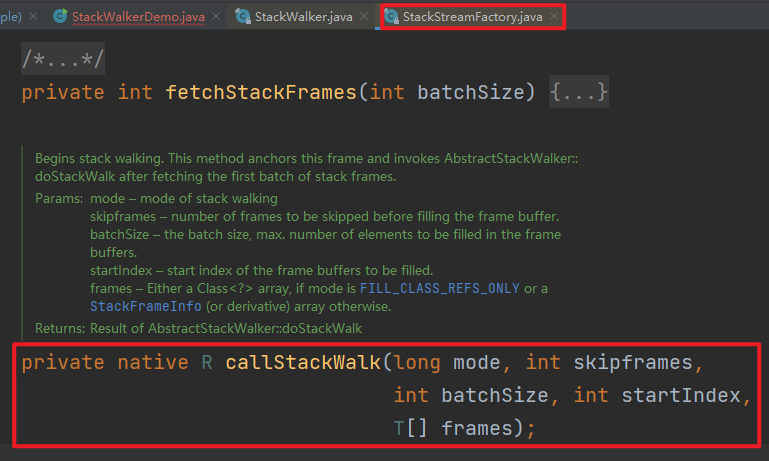
说明:上述截图,来自于StackStreamFactory.java#callStackWalk方法
5.2.易用性-getCallerClass()-简化get方式
在实战中,我们会有这样一种需求:获得调用者的Class对象。
在Java9之前,我们除了通过反射法,还有一种"曲线救国"的手段:
- STEP1.继承SecurityMananger,提供一个
SecurityManager::getClassContext方法的包装接口。SecurityManager::getClassContext方法可以返回调用栈的Class数组。SecurityManager::getClassContext方法是protected类型的方法。SecurityManager::getClassContext方法的内部实现是调用了native方法——protected native Class<?>[] getClassContext()。
说明:反射法就是先通过Thread::getStackTrace方法获得调用者的类标识符,再通过反射进而获得调用者的Class对象
我们通过示例代码来感受一下这种"曲线救国"的手段:
| |
这种方法比反射法的优点就是省略了自行反射,弊端是获取Class<?>[]中第N个元素——因为这个数组表示的调用栈的size会随着调用者不同而变化,确定要获取哪个元素的索引,将会变成隐晦的"业务潜规则”。
在Java9,有了StackWalker,我们再来体验一下新的访问方式:
| |
这样的感觉就很"舒服"了,一行代码就可以获得调用者的Class<?>。
getCallerClass()方法的内部实现,依然是调用了walk方法。
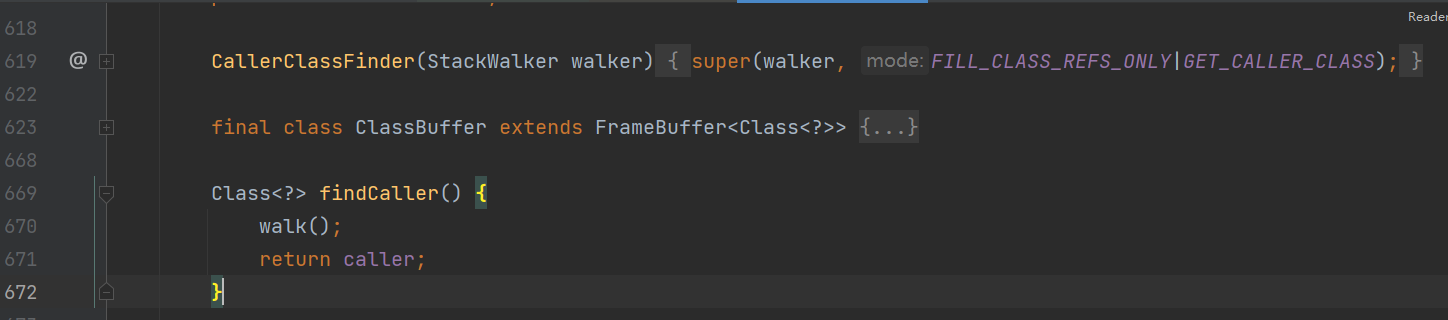
说明:见JDK源码-StackStreamFactory.java
5.3.性能
JEP259中强调了StackWalker提升了获取虚拟机栈的性能,归纳网上各种技术资料的观点:
- 观点1:
getCallerClass()可以提升性能 - 观点2:
limit、estimateDepth、skip可以提升性能 - 观点3:延迟加载
StackFrame可以提升性能
StackWalker的本质是get的过程,
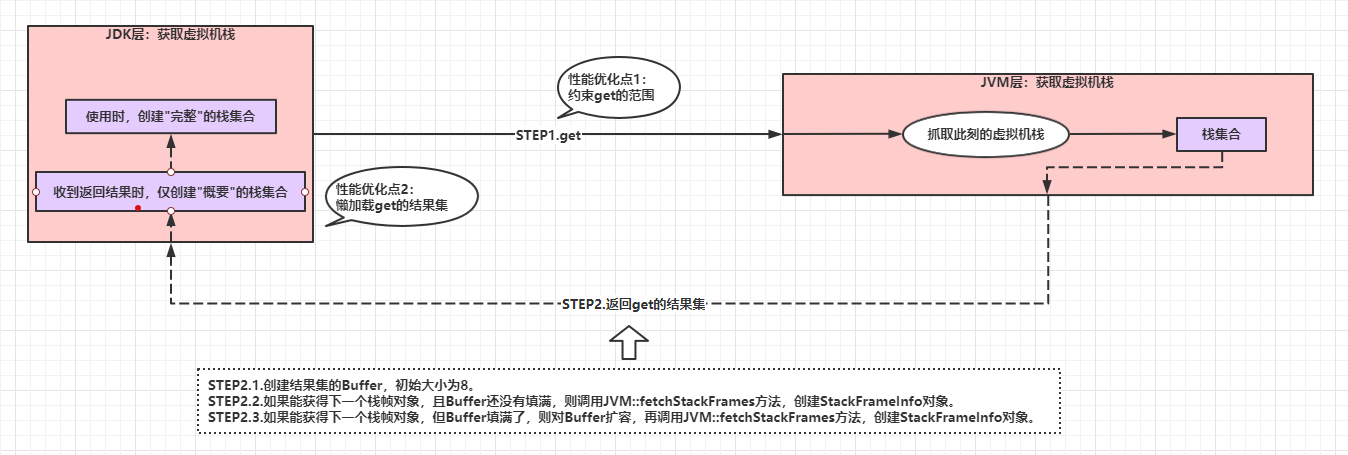
如果我们抽象一下get的过程,可以包括两个步骤:
- STEP1.get:JDK层调用JVM的native接口,获得虚拟机此时此刻的栈帧集合。
- STEP2.返回get的结果集:JVM的native接口返回抓取的栈帧集合。
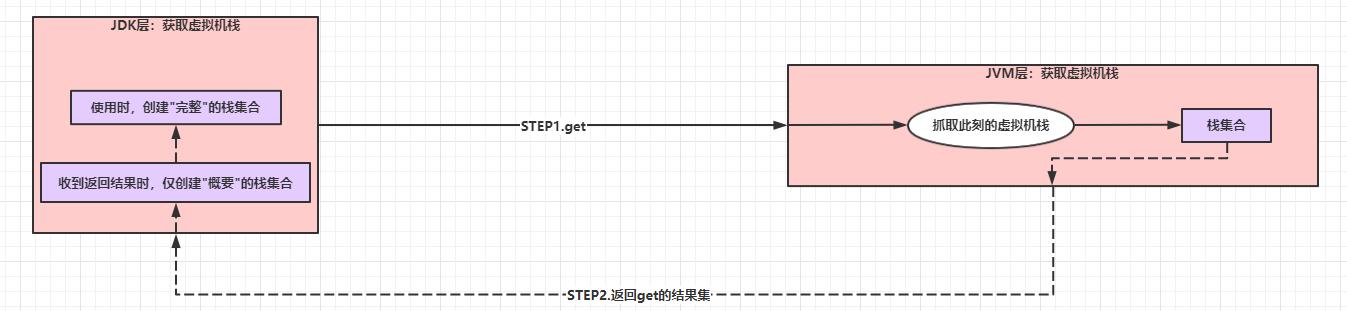
那么,我们可以脑补一下可行的性能优化措施:
- 约束get的范围:支持"分页查找”,限制get的行为是获取部分栈帧集合。
- 懒加载get的结果集:JVM层用C++实现,JDK层用Java实现,获得的栈帧集合需要从C++的内存数据转换为Java的内存数据。如果高频调用
StackWalker提供的接口,频繁地反序列化栈帧集合的数据结构势必造成性能瓶颈。
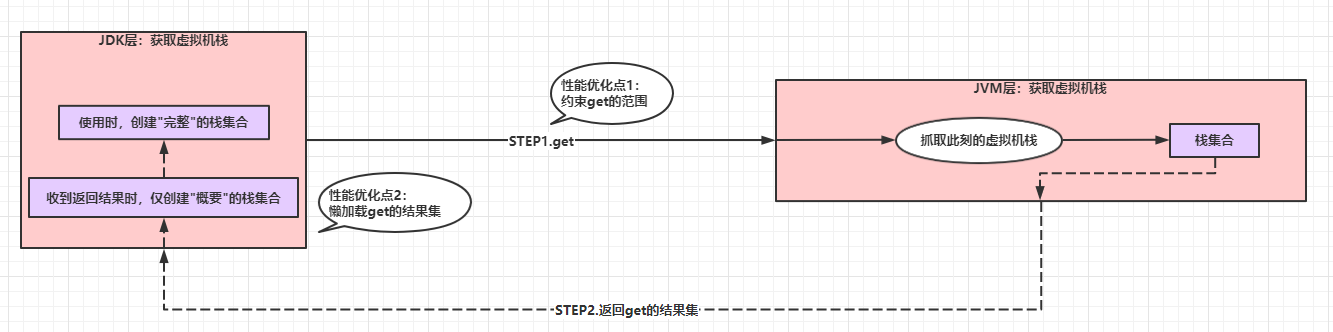
基于上述推理,我们可以进一步猜测网上各种技术资料的3个观点是否有可能逻辑成立:
- 观点1可能没有显著的性能提升:
getCallerClass()仅仅是对walk的包装函数,没有约束get的范围,同时结果集的数据结构也和SecurityManager.getClassContext()的不同,没有同等的可比性。因此,观点1可能是个性能提升的伪命题。 - 观点2可能有性能提升:
limit、estimateDepth、skip本质是在约束get的范围,有性能提升的可能性。 - 观点3可能有性能提升:延迟加载
StackFrame可以提升性能
我们接下来从测试数据和JDK源码,逐一论证。
5.3.1.get的方式-getCallerClass
一些文章说getCallerClass()的性能会优于SecurityManager::getClassContext(),经过实测,并没有太大的差距:
笔者写了一段测试代码:
| |
测试结果如下:
| |
从测试结果看,getCallerClass()并没有性能提升。
进一步对比JDK源码:
SecurityManager::getClassContext()最终调用了
| |
StackWalker::getCallerClass()最终调用了
| |
暂时没有再深入到JVM的源码,但可以脑补一下,JVM层抓取虚拟机栈的机制不可能有极大的变化,即使做了特殊处理,也不可能有极大的性能提升。
综合上述测试结果和源码分析,我们基本可以得到这样的结论:StackWalker::getCallerClass()性能方面没有太大的变化。
5.3.2.get的范围-limit、estimateDepth、skip
先看一下比较常用的对walk的Stream处理:
| |
写到这里,我们只能得到这样一个结论:
- 性能提升的可能性:
StackWalker.walk()方法通过支持业务侧根据需要获得栈帧子集,这只是性能提升的可能性。- 如果业务侧需要获得栈帧的全集,那么也不能说这就是
StackWalker.walk()方法性能提升的根因。
- 如果业务侧需要获得栈帧的全集,那么也不能说这就是
但,我们知道JDK提供的很多集合类,都存在”初始容量“问题,因此采用limit、skip方式限定get的范围可能有不同的性能表现。
5.3.2.1.用limit限定get范围
栈本质是线性结构,如果栈帧数量为N,那么理论上不断增加limit的数量M,查询时间应该是线性递增的。
笔者写了这样一段测试代码:
| |
附LimitTestObj代码:
| |
测试结果如下:
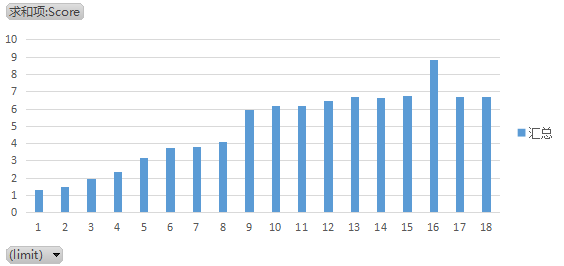
| |
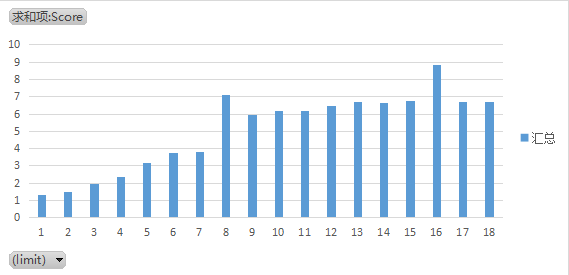
我们可以发现测试结果并没有完全遵循线性规律,而是在limit=8、limit=16出现一个性能跳变。
为什么会出现性能跳变呢?这里细化一下get的调用过程,如下图:
所以,遇到8的倍数,就有可能因为Buffer的扩容出现性能跳变,打破性能的线性化增长。
我们如何消峰呢?根据StackStreamFactory的源码,初始化Buffer时,如果StackWalker.getInstace时设置了estimateDepath参数,Buffer的Size就是以此为准。
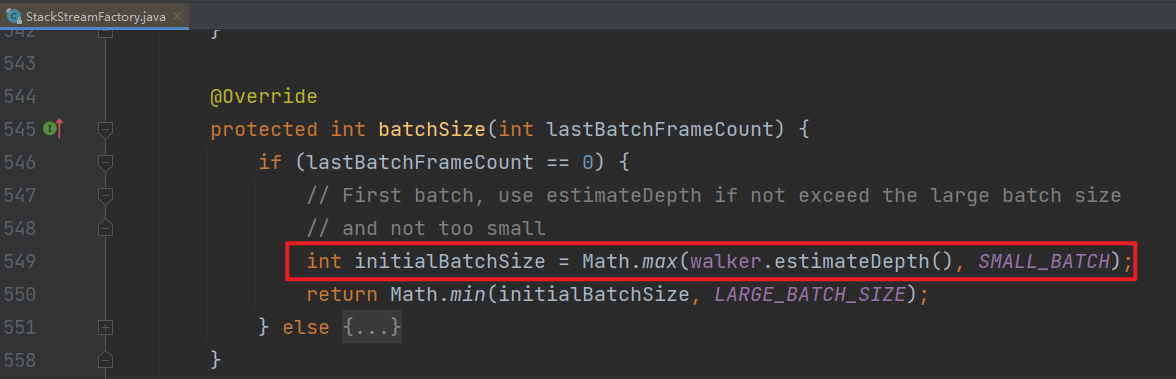
因此,我们可以将limit和estimateDepth结合起来,减少Buffer扩容的影响,示例代码:
| |
基于limit和estimateDepth结合的做法,测试结果中8的峰值被消减掉了:
5.3.2.2.skip
我们编写了这样一段测试代码:
| |
测试结果是skip并不会产生太大的性能差异:
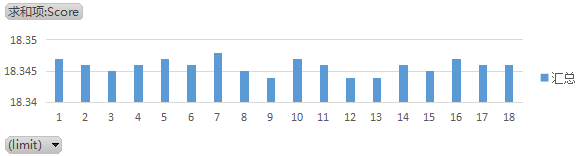
为什么skip并不会带来性能的差异呢?
因为,根据前文细化的get细节,即使设置了skip,StackWalker也是从第一帧开始调用JVM::fectchStackFrame方法。
5.3.2.3.小结
至此,我们可以得到这样的结论:
StackWalker.walk()方法支持业务侧限定get范围,给了业务侧性能提升的可能性。- 在Java9之前,即使业务侧只需要获得1个栈帧,JDK也会获得JVM中的全部栈帧。
StackWalker.walk()方法在限定get范围时,如果可以预估栈帧的size,可以通过limit+estimateDepth降低性能跳变。
5.3.3.get结果的处理-StackFrame
在JEP259中,强调了StackTraceElement类是一个代价不菲的数据结构。
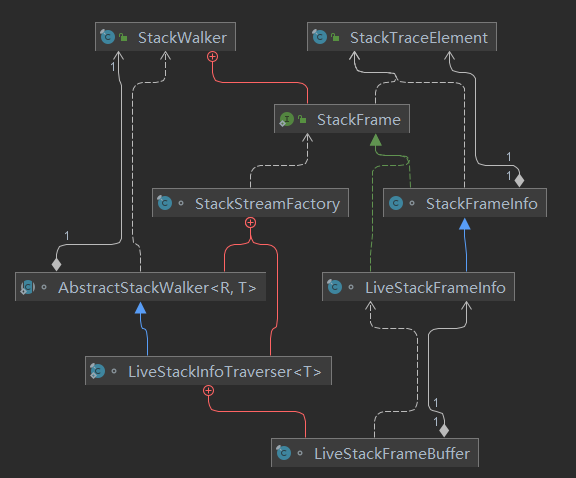
我们来详细解读一下StackFrame、StackFrameInfo、StackTraceElement的关系:
首先,在walk的过程中仅仅会创建StackFrameInfo,它实现了StackFrame接口,StackFrameInfo只有简单的几个属性:
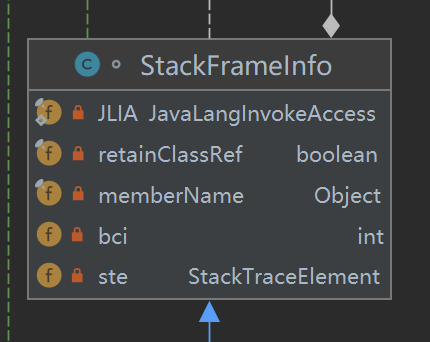
其中,JLIA是JavaLangInvokeAccess类型的,一路跟踪进去,它本质就是对java.lang.invoke包下的一组API的封装。
也就是说,在walk期间构造的StackFrameInfo仅仅通过JVM的native接口获得了一些足够支撑反射的信息,大部分在JDK侧通过反射就能获得的信息,就不用调用性能代价更高的JVM的native接口去获取了。
另外,调用了StackFrameInfo对象的getFileName()、getLineNumber()、toString()方法后,这些方法会调用toStackTraceElement(),这个函数将会生成StackFrameElement对象,在这个对象中,将会调用JVM的native接口,虽然StackeFrameElement具备完整的栈帧信息,但是需要通过JVM的native接口获得,所以性能将下降很多。
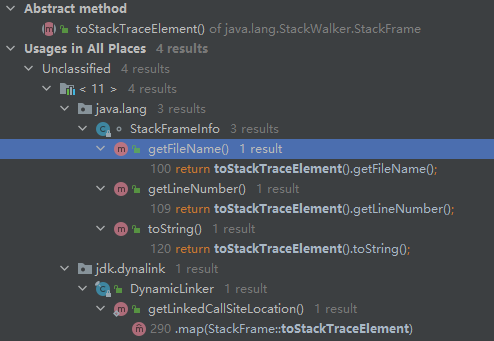
我们可以这样进行对比测试:
| |
测试结果发现:如果在不必要的场景下,触发了StackFrameElement的生成,性能表现还不如Java9之前使用Thread::getStackTrace。
| |
至此,我们可以得到两个结论:
StackWalker性能优化的核心原理:JDK侧通过反射可以获得虚拟机栈中的大部分信息,JVM侧中虽然有虚拟机栈的全量信息,但从JDK侧获取的性能代价非常小,因此StackWalker所谓的延迟加载就是在非必要的情况下绝不去从JVM去获取虚拟机栈的信息。- 慎用
StackWalker的性能敏感方法:getFileName()、getLineNumber()、toString()方法会触发从JVM获取虚拟机栈的信息,如果业务非必要,慎用。
6.思考
在学习StackWalker之初(见第4章节),是模糊的,
在理解了StackWalker的内部实现(见第5.3.1~5.3.3章节),我们形成了JDK完整的”性能提升逻辑链":
- 性能优化的主要措施:
StackWalker主要是使用轻量级对象StackFrameInfo,降低调用JVM的native接口的性能消耗,这才是性能消耗的大头。 - 性能优化的辅助措施:
StackWalker通过支持业务侧限定查询结果的范围,辅助降低了性能消耗。
有了完整的"性能提升逻辑链”,我们才能得到用好StackWalker的实战经验:
- 缩小get的范围:业务侧可以根据需要,通过limit+estimateDepth,提升获取虚拟机栈的性能。
- 尽量使用轻量级结果对象:业务侧可以尽量避免调用
getFileName()、getLineNumber()、toString()方法。
笔者在查阅StackWalker相关资料的时候,还发现了一个有趣与Log4J有关的案例:
Log4J有这么一个问题单,大致意思就是升级为Java11之后,Log4j会导致CPU得到100%,这个结果将会相当严重。。。
Log4J的程序猿最后定位的原因是业务侧没有使用private static final修饰logger对象,同时业务侧采用的是ZGC,
而logger对象记录日志时又调用了StackWalker,StackWalker调用JVM::fetch接口时在C++的代码中产生的栈帧对象又不会被ZGC回收(ZGC的Bug),而C++代码中的栈帧对象又是以Map的形式存储,当Map中的对象越来越多,Hash冲突就越多,于是越查找越慢,最后JVM不断消耗CPU。。。
这也是触动笔者较大的感触:学习标准库的初级境界是”能用",高级的境界是”用好",“用好"的关键有依赖于程序猿的基本功与探索力:
- 基本功:面对一种编程语言,基本功往往是先验知识。
- 不要以"实战中用不到"给自己设限(仅停留在语言语法层面),最好能深入到底层(API的源码->JVM->操作系统->硬件)。
- 探索逻辑的完备性:不要盲目接受新特性"宣称"的优点,特别是一些性能敏感的API。通过JDK/JVM源码推理出完备的逻辑链,避免在产品中踩坑。
- 探索细节背后的故事:不要忽略javadoc里的细节或结论,这些细节很可能是API提供者曾经花费大量精力攻克的难关,也可能是API提供者设计的精妙机关。
没有达到”用好“的境界,就有可能在不合适的场景下使用”新特性/新API",最终得到极差的**“性能”、“安全性”**等。
7.参考
https://issues.apache.org/jira/browse/LOG4J2-2880
https://mail.openjdk.java.net/pipermail/zgc-dev/2019-March/000612.html
https://openjdk.java.net/jeps/259
https://cr.openjdk.java.net/~mchung/jdk9/jep259/api/java/lang/StackWalker.html